文献阅读_Document-Level Event Argument Extraction by Conditional Generation
前言
小白读论文 文献阅读汇总

Proceedings of the 2021 Conference of the North American Chapter of the
Association for Computational Linguistics: Human Language Technologies, pages 894–908
June 6–11, 2021. ©2021 Association for Computational Linguistics
小白翻译了文章主要内容,和附录(因为附录有一些实现细节), 至于论文下标注释的就没加上,详细的大家可以去看看 原文 呢。
论文
摘要
在IE社区中,事件抽取一直被视为句子级任务。我们认为,这种设置与人的信息寻找行为不匹配,导致提取结果不完整和无信息。我们提出了一个文档级的神经事件参数提取模型,它通过模拟为根据事件模板的条件生成的任务实现。我们还编译了一个新的文档级事件提取基准数据集WIKIEVENTS,其中包含完整的事件和相关引用。在论元提取任务上,我们在RAMS和WIKIEVENTS数据集上分别获得了7.6% F1和5.7% F1的绝对增益。在更具挑战性的信息特征提取任务中,需要隐式共参推理,我们比最佳基线获得了9.3%的F1增益。为了演示我们的模型的可移植性,我们还创建了第一个端到端零样本事件提取框架,并实现了完全监督模型97%的触发器提取性能和 82%的论元提取性能,在此过程中只给定了ACE上33种类型中的10种。
1 引言
通过将大量非结构化文本转换为触发器论元结构,事件提取模型在帮助我们处理大量文档以形成洞察力方面提供了独特的价值。虽然现实世界中的事件经常被描述在整个新闻文档中(甚至跨越多个文档),但现有事件提取模型的操作范围一直被限制在句子级别。

事件提取的早期工作最初将任务作为文档级角色填充(Grishman和Sundheim, 1996),它在一组狭窄的场景和小数据集上进行评估。ACE的发布,一个具有完整事件注释的大规模数据集,开启了应用强大的机器学习模型的可能性,使得事件提取方面产生显著改进。这些模型的成功和ACE作为训练数据集的广泛采用建立了句子级别事件抽取作为主流任务的定义。
这个系统阐述表示了现实生活中的信息寻找行为和创建数据集的详尽注释过程之间的错位。一个信息搜寻会议(Mai, 2016)可以分为6个阶段:任务启动,话题选择,焦点预探索,焦点信息,信息收集和搜索终止 (Kuhlthau, 1991)。给定目标事件实体,我们可以安全地假设主题选择已经完成,用户在发现感兴趣的事件之前从浏览文档开始,关注这些事件,然后将所有相关的事件聚集在格式中。在“预聚焦探索”和“信息收集”阶段,用户自然会跨越句子边界。
从经验上看,使用句子边界作为事件范围方便地简化了问题,但也引入了基本缺陷:结果提取是不完整的和无信息的。我们在图1中展示了这一现象的两个例子。第一个例子说明了句子间的隐式论元。包含PaymentBarter论元“$280.32”的句子不是包含exchangebusell事件触发器“reserve”的句子。如果没有文档级别模型,这些论元将会被遗漏并导致不完整的提取。在第二个例子中,论元出现在同一个句子中,但写成代词。如果不解决交叉句的参照问题,这种抽取对读者来说是没有信息的。
我们提出了一个新的端到端文档级事件参数提取模型,将问题框架为给定模板的条件生成。在未填充模板和给定上下文的条件下,要求模型生成一个带的论元已填充的模板,如图2所示。我们的模型不需要实体识别,也不需要作为预处理步骤的共引用解析,并且可以处理单个句子以外的长上下文。由于模板通常作为事件本体定义的一部分提供,因此不需要额外的人工工作。与最近的努力相比(Du和Cardie, 2020;Feng et al., 2020;Chen et al., 2020)重新定位问答(QA)模型用于事件提取,我们基于生成的模型可以轻松处理缺少论元和相同角色的多个论元的情况,而不需要调优阈值,并且可以在一次中提取所有参数。
为了评估文档级事件抽取的性能,我们收集并注释了一个新的基准数据集WIKIEVENTS。这种文档级评估还允许我们超越最近的论元,而在整个文档上下文中寻找最有信息的论元。特别是,在与触发器相同的句中检测到的论元中,只有34.5%可以被认为是有信息的。我们提出了这个文档级语义参数提取的新任务,并表明尽管这个任务需要更多的交叉句子推断,我们的模型仍然可以可靠地很好地执行。
由于我们通过模板提供本体信息(事件需要哪些角色)作为外部条件,因此我们的模型对不可见的事件类型具有很好的可移植性。通过将论元提取模型与基于关键字的零样本触发提取模型配对,我们可以对新事件类型零样本迁移。
本文的主要贡献可以总结如下:
-
我们通过条件文本生成的端到端神经事件参数提取模型, 来处理文档级论元提取任务。我们的模型不依赖于实体提取,也不依赖于实体/事件的相关引用。与基于QA的方法相比,它可以很容易地处理缺少论元和相同角色中的多个论元的问题。
-
我们提出了第一个具有完整的事件和参考注释的文档级事件抽取基准数据集。我们还引入了新的文档级语义论元提取任务,该任务评估模型在长范围内学习实体-事件关系的能力。
-
通过将我们的论元抽取模型与一个零样本事件触发器分类模型相结合,我们发布了第一个端到端零样本事件抽取框架。
2 方法
事件提取任务由两个子任务组成:触发器提取和论元提取。事件本体作为数据集的一部分,为每个事件类型提供可能的事件类型和角色。每个事件类型通常在本体中预先定义一个模板。
我们首先在第2.1节介绍文档级论元提取模型,然后在第2.2节介绍基于关键字的零样本触发器提取模型。
2.1 论元抽取模型
我们使用条件生成模型提取论元,其中条件是一个未填充的模板和一个上下文。模板是一个用 < a r g >

我们的基本模型是编码器-解码器语言模型(BART (Lewis et al., 2020), T5 (Raffel et al., 2020)。生成过程模拟在给定之前的token和对编码器的输入的情况下选择新token的条件概率。

在编码器中,双向注意层用于使每对标记之间的交互,并产生上下文c的编码。除对前一个已解码标记的注意力外,解码器的每一层还对编码器的输出进行交叉注意。
为了使用编码-解码器模型进行论元提取,我们创造了一个 < s > t e m p l a t e < s > < / s > d o c u m e n t < / s > ~template ~ <s> template <s></s> document </s>。所有在模板中的论元名字(arg1, arg2, etc.)被替换为特殊的占位token < a r g > ~document~
生成概率是由解码器输出和来自输入的token的嵌入之间的点积来计算的。

为了防止模型产生论元幻觉,我们将单词的词汇表限制为 V c V_c Vc:输入中的token集。
通过最小化数据集D中所有(内容、模板、输出)实例的负对数似然来训练模型:
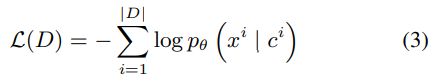
事件本体经常对论元施加实体类型约束。当仅使用模板时,该模型无法获得约束,会生成看似流畅和有意义的回复,然而却是错误的论点。受(Shwartz et al., 2020)的启发,我们使用澄清(clarification)状态来添加约束而不打破模型的端到端属性。
在表1所示的示例中,我们可以看到贪婪解码选择“tax plan”作为PublicStatement事件的第二个参与论元。除了介词“with”之外,模板中没有任何东西表明这个位置应该填上一个人而不是一个主题。为了纠正这个错误,我们以类型语句的形式为其论元填充添加了“clarifications”: < a r g >

E r E_r Er是角色r根据本体的有效实体类型的集合, z e z_e ze是类型状态。因为““tax plan is a person.”违背常识,所以产生这句话的可能性很低。通过这种方式,我们可以删除具有冲突实体类型的响应。
2.2 基于关键字的触发器提取模型
我们的参数提取模型依赖于检测到的事件触发器(类型和偏移量)作为输入。任何触发器提取模型都可以在实践中使用,但是这里我们描述了一个触发器提取模型,该模型设计用于仅使用关键字级别的监督。例如,对于“StartPosition”事件,我们使用3个关键字“hire, employment and appoint”作为初始监督,但没有提到级别标注。这个模块允许快速转移到感兴趣的新事件类型。
我们将触发提取任务视为序列标注,我们的模型由TapNet改进而来 (Yoon et al., 2019;Hou et al., 2020),该模型设计用于少样本分类,后来扩展到条件随机场(CRF) 模型。与(Hou et al., 2020)相比,我们没有折叠转移矩阵的条目,这使得我们的模型可以了解每种事件类型的不同概率。由于我们的模型以类关键字作为输入,因此我们将此模型称为TAPKEY。
对于每个事件类型,我们首先利用(孟et al., 2020)中的屏蔽类别预测方法,基于给定的关键字获得一个类表征向量 c k c_k ck。这个类表征向量是关键字的BERT向量表征的平均值,并应用了一些过滤器来消除出现的歧义。过滤过程的细节包括在附录A中。
采用线性CRF模型,被标注句子的概率为

h i h_i hi 是对应的 x i x_i xi 的嵌入网络(在我们的例子,是BERT-large)输出。
y i y_i yi的标签空间是IO标记的集合。我们选择使用这个简化的标记方案,因为它有更少的参数和事实,热该事实在同一事件的连续触发器是非常罕见的。
特征函数 ϕ ( ⋅ ) \phi (\cdot) ϕ(⋅) 被定义为

ϕ k \phi_k ϕk 是类别k的一个正则化的引用向量,并且M是一个投影矩阵,它两都是模型的参数。M不是一个习得的参数,而是通过对修正的引用向量矩阵进行QR分解来求解的。具体来说,M满足以下方程:
我们详见TapNet (Yoon et al., 2019)的论文,并在附录a中提供了简化的推导。标签之间的过渡分数ψ(·)是使用两个对角矩阵 W W W和 W o W_o Wo对进行参数化的:


在训练阶段,通过最小化序列的负对数概率来学习模型参数 { φ , W , θ f } \{φ, W, θ_f\} {φ,W,θf}。

将所有参考向量的矩阵Φ初始化为对角矩阵,第二项对向量进行正则化表示训练时接近标准正交。 α \alpha α是一个超参数。
在零样本设置中,在应用模型之前,我们首先在伪标记数据上进行训练。在伪标签阶段,我们直接使用类向量和语言模型中标记的嵌入之间的余弦相似度来给文本分配标签。我们使用高置信度的事件I标签和事件O标签标签。其余的token将被标记为X(表示未知)。然后对该模型进行token分类任务的训练。由于模型中的参数都不是特定于类的,因此可以在零样本迁移设置中使用模型。
3 基准数据集WIKIEVENTS
3.1 评估任务
我们的数据集评估两个任务:论元提取和语义论元提取。
对于论元提取,我们使用标题词F1 (head F1)和相关提及F1 (Coref F1)作为度量。如果偏移量与引用匹配,则认为论元范围是正确的。如果论元角色也匹配,则认为论元分类正确。因为注释器被要求尽可能注释标题词,所以我们将此度量称为head F1。对于Coref F1,如果提取的论元与(Ji和Grishman, 2008)中使用的黄金标准参数相关联,则该模型将获得全额分数。
对于下游的应用程序,如知识库构建和问答,作为代词的论元填充对用户没有用处。运行额外的共指解析模型来解决它们将不可避免地引入传播错误。因此,我们提出了一个新的任务:文档级语义论元提取。我们认为姓名提及比名词性提及信息更丰富,而代词信息最少。当提及类型相同时,我们选择最长的提及作为信息量最大的提及。在此任务下,只有当提取的论元是整个文档中信息最丰富的论元时,才会给模型打分。
3.2 数据集创建
我们收集英文维基百科上关于真实世界事件的文章,然后根据参考链接抓取相关新闻文章。我们首先手动识别类别页面,比如
https://en.wikipedia.org/wiki/Category:Improvised_explosive_device_bombings_in_the_United_States, 然后对于每一个时间页(举个例子, https://en.wikipedia.org/wiki/Boston_Marathon_bombing), 我们记录其“参考”部分的所有链接,并使用文章抓取工具提取网页的全文。
我们遵循最近从KAIROS项目中建立的事件注释本体。这个本体在三层层次结构中定义了67种事件类型。相比之下,常用的ACE本体在两个层次上定义了33种事件类型。
我们雇佣了研究生作为注释者,并为不常见的事件类型提供了示例句子。该过程总共涉及26个注释者。我们使用BRAT接口进行在线注释。
标注过程分为两个阶段:事件提及(触发器和论元)标注和事件引用标注。除了参考提及集群,我们还为每个集群提供最有信息的提及。详细的数据收集和标注过程可在附录B中找到。
3.3 数据集分析
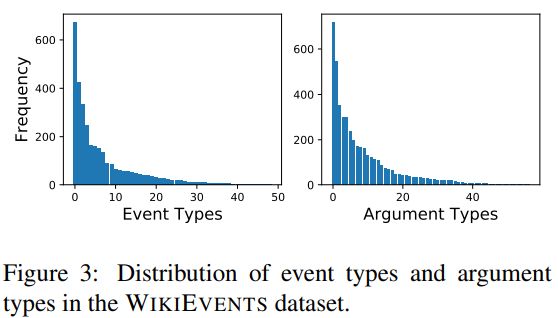
表2列出了数据集的总体统计信息。与ACE相比,我们的WIKIEVENTS数据集拥有更丰富的事件本体,特别是对于论元角色。观察到的事件类型和论元角色的分布如图3所示。
在图4中,我们进一步检查事件触发器和论元之间的距离。当考虑提到的最近的论元时,参数的分布非常集中于0,这表明该注释标准更偏向局部提取。在提取信息提及的情况下,我们有一个相对平坦的长尾分布,平均距离为68.82个单词(相比之下,最近的提及为4.75个单词)。特别是,在相同的句子检测到的论元中,只有34.5%的参数可以被认为是有信息的。这证实了在搜索语义论元填充符时需要文档级推理。
4 实验
我们的实验分为三种设置:(1)文档级事件论元提取;(2)文档级信息参数提取和(3)零样本事件提取。
对于文档级事件论元提取,我们遵循传统的方法,即将最接近触发器的论元视为基本事实。在第二种情况下,我们认为论元中最有信息的提及是基本真理。
零样本设置检查模型对新事件类型的可移植性。在这个集合下,我们认为一部分事件类型是已知的,并且只会看到这些事件类型的注释。我们使用两种设置来选择已知类型:10种最频繁的事件类型和8种事件类型,分别来自事件本体的父类型。评估是在完整的事件类型集上完成的。读者可参考附录C了解实现细节和超参数设置。
4.1 数据集

除了我们的数据集WIKIEVENTS,我们还报告了自动内容提取(ACE) 2005数据集10和多句角色(RAMS)数据集的性能。
我们遵循预处理从(Lin et al., 2020;Wadden et al., 2019)用于ACE数据集。ACE数据分割的统计信息可以在表3中找到。RAMS (Ebner et al., 2020)是最近发布的具有交叉句论证注释的数据集。为每个事件触发器提供了一个5个句子的窗口,并为每个角色标注了最近的论元范围。我们遵循从1.0版本开始的官方数据划分。
4.2 文档级事件论元提取
表4显示了在RAMS上进行论元提取的性能。在RAMS数据集上,我们主要与该数据集上目前使用的SOTA Two-step (Zhang et al., 2020)进行比较。为了处理长上下文,它将论元提取分为两个步骤:头部检测和扩展。
在表5中,我们展示了WIKIEVENTS数据集的结果。我们将流行的常用的在句子级别上执行触发器提取的BERT-CRF基线(Shi和Lin, 2019)和在句子级别和文档级别上运行的BERT-QA (Du和Cardie, 2020)进行比较。

4.3 文档级语义论元提取
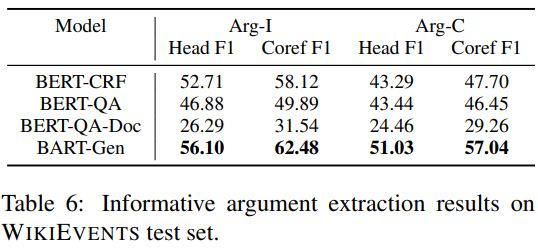
我们使用语义论元作为训练数据的WIKIEVENTS上进行测试,并与BERT-CRF和BERT-QA基线进行比较。结果如表6所示。
对比表5和表6的结果,我们有以下发现:
-
语义论元提取比最近论元提取要困难得多。所有模型的巨大性能差距说明了这一点。
-
虽然CRF模型很好地识别跨度,但性能受到类别的阻碍。论元遵循长尾分布,由于CRF模型分别学习每个论元标签,它不能利用论元角色之间的相似性来提高罕见角色的性能。
-
另一方面,QA模型的论元识别能力很差。当QA模型为相同的角色生成多个答案时,这些答案范围通常彼此接近或重叠。我们在定性分析中给出了一个具体的例子。
-
直接将BERT-QA模型应用到文档级别是行不通的。QA模型很容易被附加的文本分心,不知道应该关注哪个事件。我们认为这不是QA方法的基本限制,而是将QA模型改用于文档级事件提取需要更多研究。
4.4 零样本事件抽取
我们在表8中显示了零样本迁移设置的结果。由于基线BERT-CRF模型(Shi和Lin, 2019)不能直接处理新标签,我们将其排除在比较之外。除了BERT-QA,我们还用原型网络替换了TAPKEY触发器提取模型(Snell et al., 2017) 14。我们用类向量替换原型以实现零样本学习。触发器提取的完整结果包含在附录D中。
BERT-QA的性能受到触发器识别步骤的极大限制。无论是原型网络,还是我们的模型TAPKEY,都可以利用关键字信息来协助传递。引人注目的是,与完整集相比,仅使用30%的训练数据,TAPKEY在F1中只下降了3个点。论元提取组件对训练数据的减少更为敏感,但仍然表现得相对较好。我们注意到,当模板是全新的时,模型可能会在生成过程中改变模板结构。
4.5 定性分析
我们在表7中展示了我们模型的抽取与基线在WIKIEVENTS上的论元抽取任务的比较。我们的模型能够有效地捕获所有的论元,而CRF模型艰难地捕获少量事件类型,而QA模型则受到过度生成的阻碍。
图6显示了我们的模型提取的语义论元的示例。我们的模型能够选择被告的起诉书和攻击地点的信息提及,即使触发是几句话之外。
我们还将我们的模型作为管道多媒体多语言知识提取系统 (Li et al., 2020)的一部分,用于NIST流媒体知识库构建任务(SM-KBP2020)15。与原始系统相比,我们的模型能够发现53%的新论元,特别是那些离事件触发器更远的论元。系统整体性能排名第一。我们在图5中展示了一些示例。



4.6 仍面临的挑战
Ontological Constraints
有些角色是互斥的,例如Transport事件中的Origin/Destination和Surrender事件中的receiver /Yielder。在下面的例子中,“Japan”被提取为Recipient和Surrender事件的Yielder的一部分: “If South Korea drifts into the orbit of the US and Japan, China’s influence on the Korean peninsula could be badly compromised." At a military parade in Beijing to mark the 70th anniversary of the surrender of Japan last September, …". 这样的约束可以合并到模型的解码过程中。
常识性的知识
在下面的立场与含蓄的论点: “Whether the U.S. extradites Gulen or not this will be a political decision, ”Bozdag said.“ If he is not extradited, Turkey will have been sacrificed for a terrorist.” A recent opinion poll showed two thirds of Turks agree with their president that Gulen was behind the coup plot." 我们的模型错误地将“美国”标记为引渡目的地,将“土耳其”标记为引渡源,尽管“引渡者”被正确地标记为“美国”。“The extraditer, if being a country, is usually is same as the source of extradition”等常识有助于纠正这一错误。

5 相关的工作
5.1 文档级别的事件抽取
文档级事件提取可以追溯到MUC会议的角色填充任务(Grishman和Sundheim, 1996),这些会议需要为特定的场景检索参与实体和属性值。KBP插槽填充挑战与此任务类似,但以实体为中心。
一般来说,文档级论元提取是一个研究不足的主题,主要是由于缺乏数据集。已经发布了一些专门用于隐式语义角色标注的数据集,如SemEval 2010 Task 10 (Ruppenhofer et al., 2010)、Beyond NomBank数据集(Gerber and Chai, 2010)和ON5V (Moor et al., 2013)。然而,这些数据集的规模很小,只涵盖了一小组精心挑选的。最近,(Ebner et al., 2020)发布了RAMS数据集,其中包含了跨句隐含论证的注释,涵盖了广泛的事件类型。尽管如此,这个数据集每个文档只标记一个事件,这促使我们创建一个具有完整的事件和引用注释的新基准数据集。
GRIT模型(Du et al., 2021)是为MUC任务设计的一个生成模型,该任务可以看作是填写预定义的表格。相比之下,我们处理模板(例如“ < a r g 1 >
5.3 零样本事件提取
早期尝试的零样本或少样本事件提取依赖于预处理,如语义角色标注(SRL) (Peng et al., 2016)或抽象意义表示(AMR) (Huang et al., 2018),以便在对检测广度进行分类之前,检测触发提及和论元提及。
另一行工作只检查触发器检测的子任务,从本质上把任务减少到少样本分类。(Lai et al., 2020)和(Deng et al., 2020)都扩展了原型网络模型(Snell et al., 2017)进行分类。
最近关于零样本事件提取的工作提出了一个问题作为问答(Chen et al., 2020;杜和卡迪,2020;Feng et al., 2020),它采用不同的问题设计方法。
6 总结 & 未来工作
在本文中,我们提倡文档级事件抽取,并提出了第一个文档级神经事件参数抽取模型。我们还发布了第一个文档级事件提取基准数据集WIKIEVENTS,其中包含完整的事件和协引用注释。在传统的论元抽取任务和新的语义论元抽取任务上,我们提出的模型性能都大大超过了基于CRF和基于QA基线的性能。此外,我们演示了通过将其应用到零样本设置来演示我们的模型的可移植性。展望未来,我们希望引入更多的本体论知识,以产生更准确的抽取。
附录

1 触发器提取模型详细信息
1.1 标签方案
我们使用IO标记方案,其中I代表“inside a span”,O代表“outside any span”。 这个简化标签方案被选中来减少参数但却没有没有多少损失的建模能力因为 (1)触发器通常是单个词和I 标记(B代表“beginning of a span”)很罕见,(2)我们很少看到连续两个相同类型的事件触发。
1.2 类向量
对于每种事件类型,我们提供了3个关键字作为初始种子。 如果事件类型可以由名词触发,则为名词形式添加关键字。 我们选择的关键词将作为补充材料随本体文件一起提供。
对于每种事件类型,我们在Gigaword语料库中搜索其对应的关键词的出现情况。为了过滤关键词的歧义用法,我们使用BERT-large作为掩码语言模型,预测可以替代当前提及关键词的词语。如果该事件类型的另一个关键字出现在前50个候选关键词中,我们接受此示例。这个例子的向量表征是包含关键字的词块token的平均值。
类向量是事件类型的所有例子的平均值。
2 M的求解
以下部分是TapNet派生的简化版本(Yoon et al., 2019)。
为了正确分类 c k c_k ck, 我们希望在M定义的子空间中使与 ϕ k \phi_k ϕk 的点积最大, 而使与 ϕ l ≠ k \phi_{l \ne k} ϕl=k 的点积最小。
一个可能的解决方法是找到投影矩阵M:

这蕴含着

这是类之间相当好的分隔。
令 ϕ ^ k = ϕ − ∑ l ≠ k ϕ l \hat{\phi}_k = \phi - \sum_{l \ne k}\phi_l ϕ^k=ϕ−∑l=kϕl, 然后我们可以将前面的方程重新排列为:

注意这对每个k都成立。
如果我们定义一个矩阵 D ∈ R d × n D \in R^{d\times n} D∈Rd×n 并让 c k − λ ϕ ^ k c_k - \lambda \hat{\phi}_k ck−λϕ^k 作为它的第 k 列, 我们可以得到 M T D = 0 → M^TD = \overrightarrow{0} MTD=0, 意味着 M 的每一列是 D T D^T DT 的零空间。 D T D^T DT的零空间可以通过QR分解得到。

虽然D的秩是未知的,但它不会大于n(并且有很高的概率接近n),因此对于 m ∈ R d × m m\in R^{d\times m} m∈Rd×m,我们可以从Q的 n + 1 n + 1 n+1列开始取 m m m列。
为了适应新类型,我们在培训时间上做了一些宽限,并学习了 n ′ > n n' > n n′>n 个参考向量而不是训练集中出现的 n 个类的 n 个向量。然后当我们在推理过程中被要求识别新的类型时,我们基于新的类向量 c n ′ c'_n cn′ 更新 M。
完整的算法列在算法1中。

2.1 伪标签
在伪标记过程中,我们计算类向量与BERT-Large编码的平均句子嵌入之间的token-wise余弦相似度。如果相似度得分高于0.65,则该时间类型的token标签被接受,如果相似度得分没有一个高于0.4,则分配O标签。对于介于两者之间的情况,我们使用在X标号进行标注,这意味着忽略token进行损失计算。
3 数据集收集和注释详细信息
我们删除了少于100个token的文档,以及一些无关主题的文档,比如历史书的摘录。在注释过程中,注释者还可以将文档标记为重复文档或无关文档。所有文件均为英文。
在使用KAIROS事件本体时,在67种定义的事件类型之外,我们使用51种在我们的数据集中找到的类型,并合并一些罕见的子子事件类型。特别地, Contact.Prevarication, Contact.RequestCommand, Contact.下的事件子子类型。Movement.Transportation.GrantAllowPassage, Transaction.AidBetweenGovernments.Unspecified, Personnel.ChangePosition类型被删除。
在事件注释阶段之前,我们运行了一个SOTA实体检测模型OneIE (Lin et al., 2020)来突出实体跨度。 尽管这个模型并不完美,但它可以帮助注释者找到事件论元的候选者,并减少标注的时间。
事件注释阶段的任务是确定事件触发器和论元范围,并使用正确的事件类型(参数角色)给它们打标签。 注释者还可以添加缺失的实体或纠正自动生成的实体跨度。 应用两道程序来控制注释的质量:在注释器A完成注释后,我们将注释的文档随机分配给另一个更高级的注释B进行校正。
在阶段1结束后,我们通过将跨度调整回单词边界来清理注释,然后运行一个联合实体和事件共引用系统。 在阶段2中,标注者被实体(事件)簇所激发,并被要求纠正它们。
4 实现细节
我们使用BART-large模型(Lewis et al., 2020)作为我们的论元提取模型。表1给出了超参数。对于零样本迁移设置,我们使用较小的学习率(1e-5)和更多的epoch(6)进行训练。在生成过程中,我们使用集束大小为4的集束搜索。然后我们使用澄清语句来选择概率最高的输出。
对于触发提取任务,我们使用bert-large-cases (Devlin et al., 2019)模型。超参数列表如表2所示。BERT-CRF模型类似于(Shi and Lin, 2019)。为了指示触发器,我们将触发器附加到输入句子中:[CLS] sentence [SEP] trigger [SEP]
为了将BERT-QA模型用于我们的事件本体,我们使用Template 2(基于论元的问题模板)来提取带有触发信息的论元: [wh_word] is the [role name] in [trigger]?
5 关于ACE的额外实验
在表4和表5中,我们展示了ACE上完整的触发器提取和论元提取结果。带有星号(*)的条目表示这些是已报告的数字,并且在数据集拆分和预处理中可能容易有轻微的差异。



