ECCV 2020最佳论文讲了啥?作者为ImageNet一作、李飞飞高徒邓嘉
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
作为计算机视觉三大顶会之一,备受瞩目的ECCV 2020(欧洲计算机视觉国际会议)最近公布了所有奖项。
其中,最佳论文奖被ImageNet一作、李飞飞高徒邓嘉及其学生摘得。

这篇名为《RAFT: Recurrent All-Pairs Field Transforms for Optical Flow》的论文,究竟讲了啥?
一起来学习一下。
视频中的「光流预测」
在解读这篇论文前,先来大致回顾一下论文涉及的领域,即光流预测。
光流预测是什么
在计算机视觉中,光流是一个有关物体运动的概念,指在一帧视频图像中,代表同一目标的像素点到下一帧的移动量,用向量表示。

根据光流的亮度恒定假设,同一物体在连续的帧间运动时,像素值不变(一只小鸟不会在运动时突然变成鸭或者飞机)。
所以这个运动的过程,就像是光的“流动”过程,简称光流,预测光流的过程,就被称之为光流预测。
应用上,光流通常会用于视频中的目标跟踪,例如TLD算法。

此外,光流还可以作为视觉里程计和SLAM同步定位,以及视频动作识别和视频插帧等。
先前光流预测法的缺陷
根据是否选取图像稀疏点(特征明显,梯度较大),可以将光流预测分为稀疏光流和稠密光流,如下图左和右。
其中,稀疏光流会选取图像稀疏点进行光流估计;而在稠密光流里,为了表示方便,会使用不同的颜色和亮度表示光流的大小和方向。

针对这两种方法,目前有传统预测和基于深度学习的两种经典算法。
1、传统方法:稀疏光流估计算法
求解光流预测算法前,首先要知道孔径问题。
如图,从圆孔中观察移动条纹的变化,发现条纹无论往哪个方向移动,从圆孔来看,移动的变化都是一致的。
例子再通俗一点,看看发廊的旋转灯,灯上的条纹看起来总在往上走(其实没有)。

其中一种传统的Lucas-Kanade算法,是求解稀疏光流的方法,选取了一些可逆的像素点估计光流,这些像素点是亮度变化明显(特征明显)的角点,借助可逆相关性质,预测光流方向。
2、深度学习方法:FlowNet
FlowNet是CNN用于光流预测算法的经典例子。
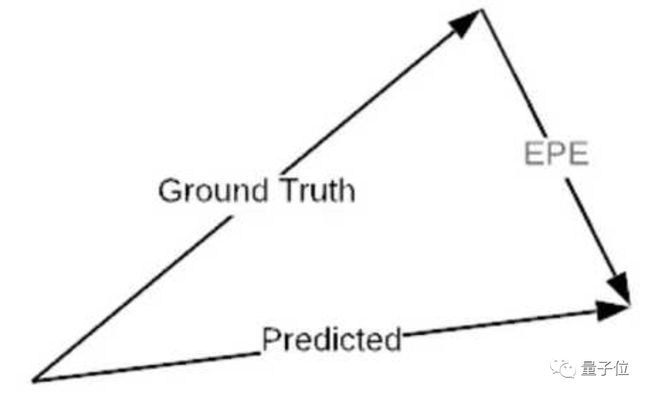
在损失设计上,对于每个像素,损失定义为预测的光流值和真值(groundtruth)之间的欧氏距离,称这种误差为EPE,全称End-Point-Error。
当然,说到这里,不得不提一句光流预测的经典数据集FlyingChairs(飞椅)。
为了模拟目标的多种运动方式,飞椅数据集将虚拟的椅子叠加到背景图像中,并将背景图和椅子用不同的仿射变换,得到对应的另一张图。

△ 画风有点像玩个锤子
这个数据集也成为许多光流预测网络必备的数据集之一。
然而,上述基于深度学习的经典光流预测算法,存在着几个缺点,无论怎么优化,这些缺点都会因为框架自身而一直存在。
但在RAFT,这个全称光流循环全对场变换的框架中,过往的3大缺点都被一一解决了:
突破局限,三点创新
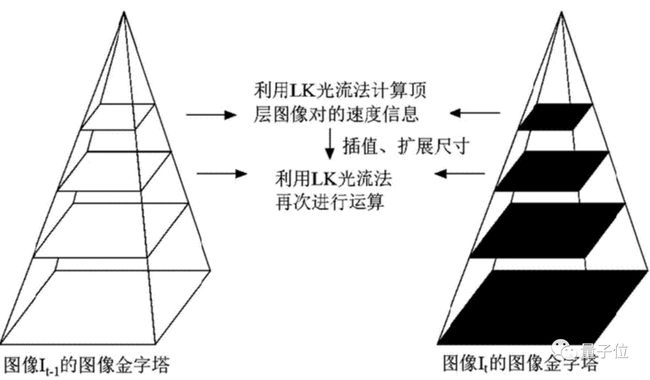
第一,先前的框架普遍采用从粗到细的设计,也就是先用低分辨率估算流量,再用高分辨率采样和调整。
相比之下,RAFT以高分辨率维护和更新单个固定的光流场。
这种做法带来了如下几个突破:低分辨率导致的预测错误率降低,错过小而快速移动目标的概率降低,以及超过1M参数的训练通常需要的迭代次数降低。
第二,先前的框架包括某种形式上的迭代细化,但不限制迭代之间的权重,这就导致了迭代次数的限制。
例如,IRR使用的FlowNetS或PWC-Net作为循环单元,前者受网络大小(参数量38M)限制,只能应用5次迭代,后者受金字塔等级数限制。
相比之下,RAFT的更新运算是周期性、轻量级的:这个框架的更新运算器只有2.7M个参数,可以迭代100多次。
第三,先前框架中的微调模块,通常只采用普通卷积或相关联层。
相比之下,更新运算符是新设计,由卷积GRU组成,该卷积GRU在4D多尺度相关联向量上的表现更加优异。
光流预测的效果
话不多说,先上RAFT光流预测的效果图。
这是在Sintel测试集上的效果展示,最左边是真值,最右边是RAFT预测的光流效果,中间的VCN和IRR-PWC是此前效果较好的几种光流预测框架。

可以看出,相较于中间两个框架的预测效果,RAFT的预测不仅边界更清晰,而且运动的大小和方向准确(看颜色)。
此外,在KITTI数据集上的预测效果也非常不错。
图左的几辆小车被清楚地预测了出来,而图右中,驾驶方向不同的车辆也能用不同的颜色(红、蓝)区分标记。

不仅小视频,在1080p的高分辨率视频(DAVIS数据集)中,光流预测的效果也非常不错。

有意思的是,在训练参数(下图横轴)几乎没有明显增加的情况下,RAFT在一系列光流预测框架中,EPE误差(下图纵轴)做到了最小。

由上图可见,团队同时推出了5.3M参数量和1.0M轻量级的两个框架,EPE误差效果均非常好。
从效果来看,在KITTI数据集上,RAFT的F1-all误差是 5.10%,相比此前的最优结果(6.10%)减少了16%;在Sintel数据集上,RAFT只有2.855像素的端点误差(End-Point-Error),相比先前的最佳结果(4.098 像素)减少了30%。
不仅推理效率高,而且泛化能力强,简直就是光流预测中各方面超越SOTA的存在。
那么,RAFT的框架究竟是怎么设计的呢?
高性能端到端光流网络架构
从图中可见,RAFT框架主要由三个部分构成:特征编码器、相关联层(correlation layer)和基于GRU的更新运算器。
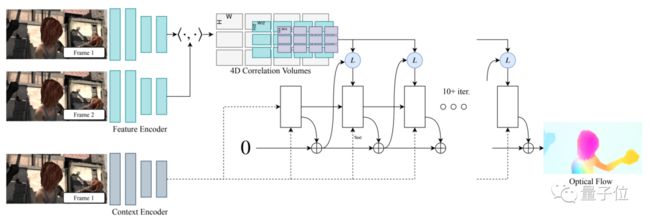
其中,特征编码器主要用来从输入的2张图中提取每个像素的特征,期间也包括一个上下文编码器,专门用来提取图1的特征。
至于相关联层,则构建了一个4D的W×H×W×H相关联向量,用于表示所有特征向量对的点积(内积)。当然,这个4D向量的后2维会被多尺度采样,用于构建一系列多尺度向量。
下图是构建相关联向量的方法,从图中可见,作者将用了几个2D片段来描述一整个4D向量。
在图1的一个特征向量中,构建了图2中所有向量对的点积,从而生成了一个4D的W×H×W×H向量(其中,图2的每个像素产生一个2D的响应图)。

这样,就能用大小为{1,2,4,8}的卷积核对向量进行平均采样了。
而更新操作器,则通过光流预测,来重复更新光流,以展现这一系列多尺度向量的向量值。
总结归纳一下,RAFT的框架流程分为三步,对每个像素提取特征,计算所有像素对的相关性,高效迭代更新光流场。
目前,RAFT框架已经放出了GitHub的项目链接,想要学习代码、或者复现的小伙伴们,可以戳文末传送门~
作者介绍
这篇论文的第一作者是Zachary Teed。
Zachary Teed目前在普林斯顿大学读博,是视觉与学习实验室的一名成员,导师为邓嘉。目前的主要研究方向为视频3D重建,包括运动、场景流和SLAM中的结构。
此前,他曾获圣路易斯华盛顿大学的计算机科学学士学位,并在那里取得了Langsdorf 奖学金和 McKevely研究奖。
而论文二作,则是普林斯顿大学计算机科学系助理教授邓嘉。

邓嘉曾于2006年本科毕业于清华大学计算机系,随后赴美国普林斯顿大学读博。
2007 年,李飞飞回到他的母校普林斯顿大学任职后便开始启动 ImageNet 项目,李凯教授作为支撑,将邓嘉介绍到李飞飞的实验组中,2012 年邓嘉于普林斯顿大学获计算机科学博士学位。
这并非他第一次获ECCV最佳论文奖。
2014 年,邓嘉就曾凭借论文《Large-Scale Object Classification Using Label Relation Graphs》获得当年的ECCV最佳论文奖,并且是该研究的第一作者。

除此之外,他也是ImageNet论文的第一作者。
传送门
论文链接:
https://arxiv.org/abs/2003.12039
项目链接:
https://github.com/princeton-vl/RAFT
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
每天5分钟,抓住行业发展机遇
如何关注、学习、用好人工智能?
每个工作日,量子位AI内参精选全球科技和研究最新动态,汇总新技术、新产品和新应用,梳理当日最热行业趋势和政策,搜索有价值的论文、教程、研究等。
同时,AI内参群为大家提供了交流和分享的平台,更好地满足大家获取AI资讯、学习AI技术的需求。扫码即可订阅:

加入AI社群,与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !