讲解目标检测数据集--------VOC数据集和COCO数据集的使用
仅供学习参考,如有不足,敬请指正
一:VOC数据集
VOC官方网站:
http://host.robots.ox.ac.uk/pascal/VOC/
一般情况下,大家使用2007和2012比较多
voc2007数据集地址:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html
voc2012数据集地址:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
下载好数据之后,就需要进行解压,里面大概有这些文件:

1, 第一个文件是标注:(里面会有许多文件,里面的内容如下图)

里面会显示了图片的信息,以及一些图片中存在物体,和重要目标的bndBox.
这个bndBox中的x,y的最小值和最大值,在图中绘制矩形框就刚好可以将object的物体遮盖住,
根据上面图的id号:000005.jpg就可以找出图片,如下图:
从上图中,我们可以看到很多椅子,所以在物体object中就有好几个关于chair的信息,通过bndbox的x,y值可以框选对应的chair.。
2,第二个文件里面imagesets中,我们主要看main----主要包含了不同类别训练目标的训练/验证集图片的id。

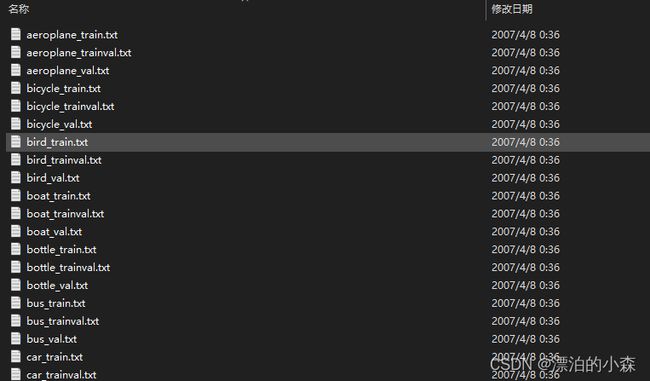
train.txt 是用来训练的图片文件的文件名列表 (训练集)
val.txt是用来验证的图片文件的文件名列表 (验证集)
trianval.txt是用来训练和验证的图片文件的文件名列表
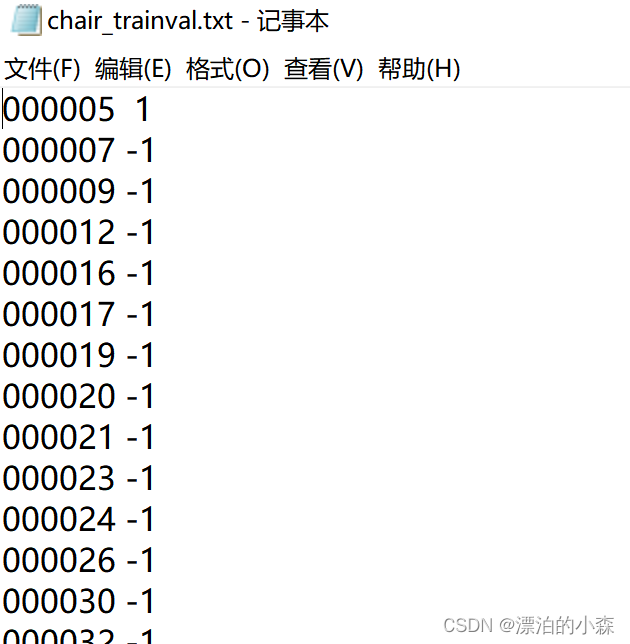
比如在000005这张图片中有chair,就会显示1.。
3,第三个文件里面主要是一些原图片
4,四五两个文件是语义分割和实例分割的文件图片

voc2007的数据集和voc2012数据集基本上操作大同小异,只不过2012的数据集里面数据更广阔。
二,COCO数据集
我下载的是2017验证数据集和标注
2017val_image地址:
http://images.cocodataset.org/zips/val2017.zip
2017val_image_标注地址:
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
大家可以进行下载,下载完之后,打开标注文件中的val的标注的json文件,由于里面没有分行,所以显示比较复杂,如图:
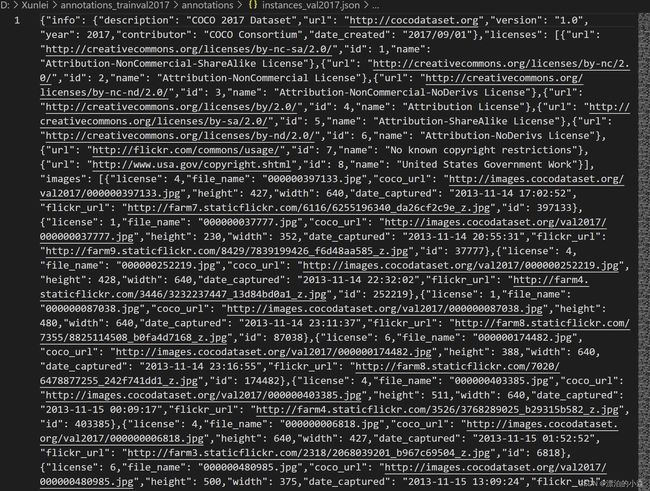
里面的内容包含了图片信息和标注的内容,各个字典的数据它们之间通过图片之间的id号连接在一起。
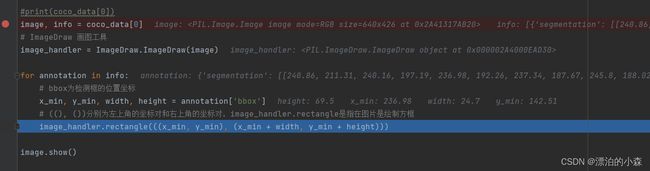
可能理解比较复杂,我们通过代码展示相关文件的内容:(对有些代码进行了注释)
import torchvision
from PIL import ImageDraw
coco_data=torchvision.datasets.CocoDetection(root=r'D:\Xunlei\val2017\val2017',annFile=r'D:\Xunlei\annotations_trainval2017\annotations\instances_val2017.json')
#print(coco_data[0])
image, info = coco_data[0]
# ImageDraw 画图工具
image_handler = ImageDraw.ImageDraw(image)
for annotation in info:
# bbox为检测框的位置坐标
x_min, y_min, width, height = annotation['bbox']
# ((), ())分别为左上角的坐标对和右上角的坐标对,image_handler.rectangle是指在图片是绘制方框
image_handler.rectangle(((x_min, y_min), (x_min + width, y_min + height)))
image.show()
通过调试,我们知道一共有多少数据,以及索引第一行我们可以知道,其返回 的值是两个一个是图片,一个是列表,以及列表是什么:

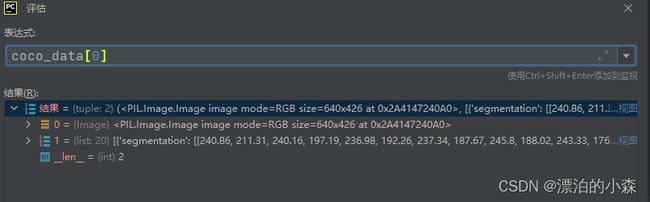

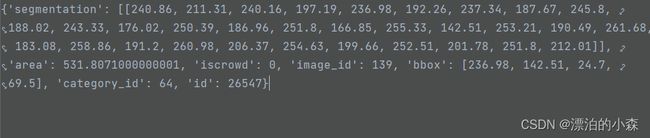
我们展示了第一张照片的内容:

三,如果大家自己想标注数据集,分享几个标注数据集的网站:
①labelme:LabelMe. The Open annotation tool
②make sense:Make Sense
③ cvat :Computer Vision Annotation Tool