简明扼要理解YOLO v3
YOLO 系列目标检测算法在目标检测史上的具有里程碑式的意义,网上YOLO系列的文章也是数不胜数,今天我就结合几个比较好的文章以及我自己的理解,简明扼要记录一下YOLO的经典版本YOLO v3,虽然现在再谈yolov3似乎已经有点过时了,但是其中的思想是一直延续到了后面的yolo v4、yolo v5,以及yolox。
网络结构

如上图是YOLO v3的网络结构图。
DBL:是YOLO v3的基本组件,就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, res8等等,表示这个res_block里含有多少个res_unit
concat:张量拼接操作。其实现方法是将darknet中间层和中间层后某一层的上采样进行拼接。值得注意的是,张量拼接和Res_unit结构的add的操作是不一样的,张量拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
下图为网络具体结构图
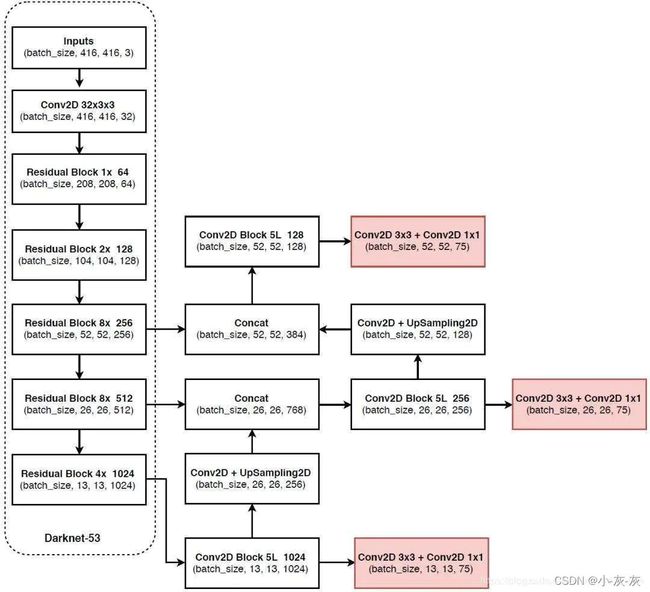
可以看到网络从上到下一路下采样,然后又从下到上一路上采样,下采样的输出层和上采样的输出层连接到一起作为输出层,这就是FPN的思想。这部分没什么较复杂的内容,至于为什么这样做,我的理解是将输入的浅层特征和深层特征结合可以相互弥补信息的不足;浅层特征目标的整体特征和全局性特征不足,而深层特征目标的局部细节信息不足,上采样的目的是为了能和浅层特征进行concat计算。
输入输出映射关系

忽略神经网络结构细节,对于一个输入图像,YOLOv3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们再看看YOLO3共进行了多少个预测。对于一个416*416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维的向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
边界框预测
Yolo v3关于bounding box的初始尺寸还是采用Yolo v2中的k-means聚类的方式来做,这种先验知识对于bounding box的初始化帮助还是很大的,毕竟过多的bounding box虽然对于效果来可能会有帮助,但是对于算法速度影响还是比较大的。
在COCO数据集上,9个聚类如下表所示,这里需要说明:特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。

Yolo v3采用直接预测相对位置的方法。预测出bounding-box中心点相对于网格单元左上角的相对坐标。直接预测出(tx,ty,tw,th,t0),然后通过以下坐标偏移公式计算得到bounding-box的位置大小和confidence。
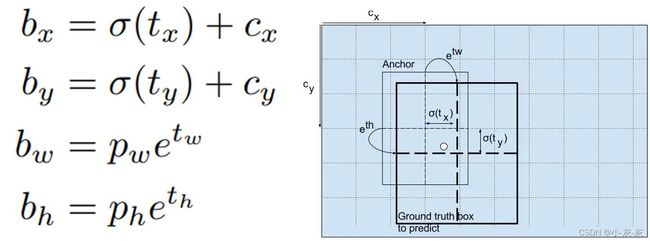
tx、ty、tw、th就是模型的预测输出。cx和cy表示grid cell的坐标,比如某层的feature map大小是13×13,那么grid cell就有13×13个,第0行第1列的grid cell的坐标cx就是0,cy就是1。pw和ph表示预测前bounding box的size。bx、by、bw和bh就是预测得到的bounding box的中心的坐标和size。在训练这几个坐标值的时候采用了sum of squared error loss(平方和距离误差损失),因为这种方式的误差可以很快的计算出来。
注:这里confidence = Pr(Object) * IoU 表示框中含有object的置信度和这个box预测的有多准。也就是说,如果这个框对应的是背景,那么这个值应该是 0,如果这个框对应的是前景,那么这个值应该是与对应前景 GT的IoU。
多尺度预测
在上面网络结构图中可以看出,Yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数。Yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。y1,y2和y3的深度都是255,边长的规律是13:26:52。
每个预测任务得到的特征大小都为N ×N ×[3∗(4+1+80)] ,N为格子大小(13,26,52),3为每个格子得到的先验边界框数量, 4是边界框需要的坐标数量(tx,ty,tw,th),1是目标预测值,80是类别数量。对于COCO类别而言,有80个类别的概率,所以每个box应该对每个种类都输出一个概率。所以3×(5 + 80) = 255。这个255就是这么来的。
Yolo v3用上采样的方法来实现这种多尺度的feature map。在Darknet-53得到的特征图的基础上,经过六个DBL结构和最后一层卷积层得到第一个特征图谱,在这个特征图谱上做第一次预测。Y1支路上,从后向前的倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第2个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第二个特征图谱,在这个特征图谱上做第二次预测。Y2支路上,从后向前倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第1个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第三个特征图谱,在这个特征图谱上做第三次预测。
就整个网络而言,Yolo v3多尺度预测输出的feature map尺寸为y1:(13×13),y2:(26×26),y3:(52×52)。网络接收一张(416×416)的图,经过5个步长为2的卷积来进行降采样(416 / 2ˆ5 = 13,y1输出(13×13)。从y1的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个26×26大小的特征图张量连接,y2输出(26×26)。从y2的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个52×52大小的特征图张量连接,y3输出(52×52)
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

预测框的3种情况
预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
正例:任取一个ground truth, 与上面计算的10647个框全部计算IOU, IOU最大的预测框, 即为正例。并且一个预测框, 只能分配给一个ground truth。 例如第一个ground truth已经匹配了一个正例检测框, 那么下一个ground truth, 就在余下的10646个检测框中, 寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(使用真实的x、y、w、h计算出); 类别标签对应类别为1, 其余为0; 置信度标签为1。
忽略样例:正例除外, 与任意一个ground truth的IOU大于阈值(论文中使用5), 则为忽略样例。忽略样例不产生任何loss。
为什么要有忽略样例?
由于YOLOv3采用了多尺度检测, 那么再检测时会有重复检测现象. 比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例), 与全部ground truth的IOU都小于阈值(0.5), 则为负例。负例只有置信度产生loss, 置信度标签为0。
输出处理
我们的网络生成10647个锚框,而图像中只有一个狗,怎么将10647个框减少为1个呢?首先,我们通过物体分数过滤一些锚框,例如低于阈值(假设0.5)的锚框直接舍去;然后,使用NMS(非极大值抑制)解决多个锚框检测一个物体的问题(例如红色框的3个锚框检测一个框或者连续的cell检测相同的物体,产生冗余),NMS用于去除多个检测框。
具体使用以下步骤:抛弃分数低的框(意味着框对于检测一个类信心不大);当多个框重合度高且都检测同一个物体时只选择一个框(NMS)。
LOSS Function
YOLO v3现在对图像中检测到的对象执行多标签分类。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。
不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
yolov3对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的每个anchor与ground truth的IOU值,计算IOU值时不考虑坐标,只考虑形状(因为anchor没有坐标xy信息),计算出对应的IOU值,IOU值最大的那个先验框anchor与ground truth匹配作为正样本参与训练,对应的预测框用来预测这个ground truth。那么正样本应该如何找?label中存放着[image,class,x(归一化),y,w(归一化),h],我们可以用这些坐标在对应13×13 Or 26×26 or 52×52的map中分别于9个anchor算出iou,找到符合要求的,把索引与位置记录好(找到IOU最大的anchor 是哪一个尺度的fearure map的哪一个anchor)。用记录好的索引位置找到predict的anchor box。
xywh是由均方差来计算loss的,其中预测的xy进行sigmoid来与lable xy求差,label xy是grid cell中心点坐标,其值在0-1之间,所以predict出的xy要sigmoid。
分类用的多类别交叉熵,置信度用的二分类交叉熵。只有正样本才参与class,xywh的loss计算,负样本只参与置信度loss。
以上就是本人参考几位大神的文章之后的理解,当然文中的图和部分说明是参考过来的。如有遗漏或者错误烦请指正。