PyTorch以及VGG模型
PyTorch以及VGG模型
- PyTorch
-
- 张量(Tensor)
- 数据集和数据加载器(DATASETS & DATALOADERS)
- 未完待续
- VGG模型
-
- PyTorch版(加载cifar10数据集)
-
- cifar10数据集
- 加载数据集
- VGG模型结构
- 训练模型
- 测试模型
- 结果示意图
- Keras(TensorFlow)版
-
- GPU使用与分配
- 数据导入
- 模型
- 训练并测试模型
- 结果(截取部分)
PyTorch
PyTorch官网
- PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
- 它是一个基于Python的可续计算包,提供两个高级功能:
1、具有强大的GPU加速的张量计算(如NumPy)
2、包含自动求导系统(自动微分机制)的深度神经网络
张量(Tensor)
- 张量(Tensor),类似于数组和矩阵, 是一种特殊的数据结构。在PyTorch中, 神经网络的输入、输出以及网络的参数等数据, 都是使用张量来进行描述。
- 张量的初始化:
- 由原始数据直接生成
- Numpy与Tensor的相互转换生成
- 根据已有的张量来生成
- 通过指定数据的维度生成
代码如下:
import torch
# 由原始数据直接生成
data = {[1, 2], [3, 4]}
data_t = torch.tensor(data)
# Numpy与Tensor的相互转换生成
# 1. Tensor转化为Numpy
ten_data = torch.ones(3)
num_data = t.numpy()
# 2. Numpy转化为Tensor
num_data1 = np.ones(3)
ten_data = torch.from_numpy(n)
# 根据已有的张量来生成
data_t1 = torch.ones_like(data_t) # 保留data_t的属性
data_new = torch.rand_like(data_t, dtype=torch.float) # 改变data_t的数据类型(int——>float)
# 通过指定数据的维度生成
data_shape = (2,3,)
rand_ten = torch.rand(data_shape)
ones_ten = torch.ones(data_shape)
zeros_ten = torch.zeros(data_shape)
- 张量属性:
- 维度 tensor.shape
- 数据类型 tensor.dtype
- 所存储的设备 tensor.device
- 张量的计算在GPU上进行操作的方法
# 首先判断当前环境GPU是否可用, 如果可以将tensor导入GPU内运行
if torch.cuda.is_available():
tensor = tensor.to('cuda')
- 张量的计算:(tensor = torch.ones(4, 4))
-
索引和切片:tensor[ a : b(行索引), c : d (列索引)]
-
连接:torch.cat([tensor, tensor], dim=1)
-
矩阵的乘法:
- y1 = tensor @ tensor,T
- y2 = tensor.matmul(tensor.T)
- y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)

-
矩阵按元素进行乘积:
- z1 = tensor * tensor
- z2 = tensor.mul(tensor)
- z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
-
就地运算(将结果存储到操作数中的运算称为就地运算):
以‘ _ ’后缀表示 -
单元素张量转换:
t_sum = tensor.sum()
t_item = t_sum.item()
-
数据集和数据加载器(DATASETS & DATALOADERS)
- 引言:用于处理数据样本的代码有时会很凌乱并且难以维护;在理想的情况下,我们希望能够将数据集代码与模型训练代码分离,以提高可读性和模块化性。
- PyTorch本身提供了两种数据原语(data primitives)
(补充说明–原语:原语是在操作系统中调用核心层子程序的指令;一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。)- torch.utils.data.DataLoader
- torch.utils.data.Dataset
未完待续
VGG模型
PyTorch版(加载cifar10数据集)
cifar10数据集
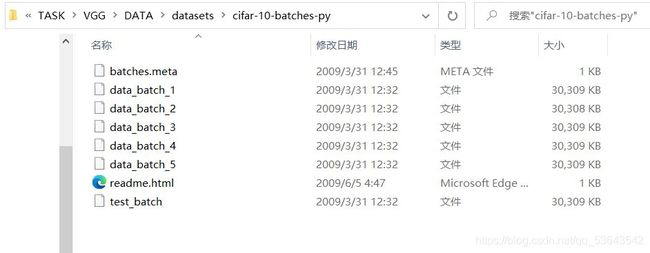
基本说明:CIFAR10包含了 10 个类别的 RGB 彩色图片,分别为:飞机(airplane)、汽车(automobile)、鸟类(bird )、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck);该图像尺寸为32*32大小。
如图所示: data_batch_1-data_batch_5分别包含了5个批次的训练数据,每个批次有10000张训练图片;test_batch包含的是测试数据集,有10000张测试的图片。
加载数据集
''' 定义超参数 '''
batch_size = 256 # 每批数据量的大小
'''
transforms.Compose:将几个变换组合在一起
transforms.Normalize:用均值和标准差归一化张量图像--计算公式:output[channel] = (input[channel] - mean[channel]) / std[channel]
RandomHorizontalFlip:以0.5的概率水平翻转给定的PIL图像
transforms.RandomResizedCrop:将PIL图像裁剪成任意大小和纵横比
transforms.ToTensor:转换一个PIL库的图片或者numpy的数组为tensor张量类型;转换从[0,255]->[0,1]
'''
''' 数据增强 '''
transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.5, 0.5, 0.5 ],
std = [ 0.5, 0.5, 0.5 ]),
])
'''加载训练集 CIFAR-10 10分类训练集'''
train_dataset = datasets.CIFAR10(root=r"D:\TASK\VGG\DATA\datasets", train=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.CIFAR10(root=r"D:\TASK\VGG\DATA\datasets", train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
VGG模型结构
表格示意图:
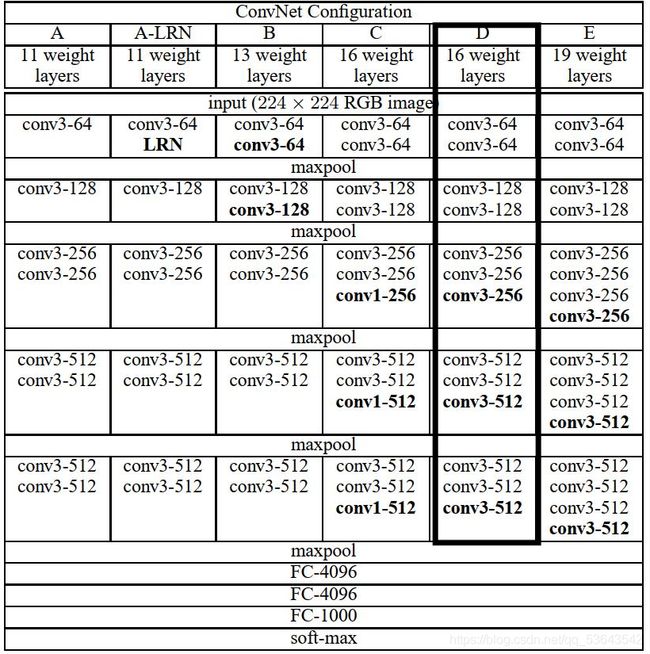
文字说明:

以VGG16为例由上图可知:在卷积中,卷积核的大小为33,步长为1,padding为1;在池化中,共有五个最大池化,池化窗口为22,步长为2
代码如下:
from torch import nn
class VGG(nn.Module):
def __init__(self,num_classes=1000):
'''
# VGG16继承父类nn.Moudle,即把VGG16的对象self转换成nn.Moudle的对象
# nn.Sequential()是nn.module()的容器,用于按顺序包装一组网络层
# nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
# nn.Conv2d是二维卷积方法,nn.Conv2d一般用于二维图像;nn.Conv1d是一维卷积方法,常用于文本数据的处理
'''
super(VGG, self).__init__()
self.features=nn.Sequential(
# 第1层卷积 3-->64
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64), # 批归一化操作,为了加速神经网络的收敛过程以及提高训练过程中的稳定性,用于防止梯度消失或梯度爆炸;参数为卷积后输出的通道数;
nn.ReLU(True),
# 第2层卷积 64-->64
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 第3层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2,stride=2),
# 第4层卷积 64-->128
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 第5层卷积 128-->128
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 第6层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2, stride=2),
# 第7层卷积 128-->256
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第8层卷积 256-->256
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第9层卷积 256-->256
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第10层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2, stride=2),
# 第11层卷积 256-->512
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第12层卷积 512-->512
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第13层卷积 512-->512
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第14层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2, stride=2),
# 第15层卷积 512-->512
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第16层卷积 512-->512
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第17层卷积 512-->512
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第18层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier=nn.Sequential(
# 全连接层512-->4096
nn.Linear(512,4096),
nn.Dropout(),
# 全连接层4096-->4096
nn.Linear(4096,4096),
nn.Dropout(),
# 全连接层4096-->1000
nn.Linear(4096,num_classes),
nn.Dropout()
)
def forward(self,a):
out = self.features(a)# 所得数据为二位数据
# view功能相当于numpy中resize()的功能,作用:将一个多行的Tensor,拼接成一行(flatten)
out = out.view(out.size(0),-1)
out = self.classifier(out) # 分类数据为一维数据
return out
module=VGG()
print(module)
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
训练模型
''' 定义超参数 '''
learning_rate = 1e-3 # 学习率
num_epoches = 50 # 遍历训练集的次数
''' 定义loss和optimizer '''
# 交叉熵损失(包括softmax运算和交叉熵损失计算的函数)
criterion = nn.CrossEntropyLoss()
# SGD优化器(随机梯度下降算法)
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
''' 训练 '''
for epoch in range(num_epoches):
print('*' * 25, 'epoch {}'.format(epoch + 1), '*' * 25)
running_loss = 0.0
running_acc = 0.0
for i, data in tqdm(enumerate(train_loader, 1)): # 遍历
img, label = data
# cuda
if use_gpu:
img = img.cuda()
label = label.cuda()
# Variable 变量
img = Variable(img)
label = Variable(label)
# 向前传播
# with torch.no_grad():
out = model(img)
loss = criterion(out, label) # 计算交叉熵损失
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1) # 预测最大值所在的位置标签,维度为1
num_correct = (pred == label).sum() # 预测正确的数目
accuracy = (pred == label).float().mean()
running_acc += num_correct.item() # 统计预测正确的总数
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
测试模型
''' 模型评估 '''
model.eval()
eval_loss = 0
eval_acc = 0
''' 测试模型 '''
for data in test_loader:
img, label = data
if use_gpu:
img = Variable(img).cuda() # Variable将其转换为变量
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(test_dataset)), eval_acc / (len(test_dataset))))
print()
# 对模型进行保存
torch.save(model.state_dict(), './cnn.pth')
结果示意图
************************* epoch 45 *************************
196it [00:43, 4.48it/s]
Finish 45 epoch, Loss: 0.090376, Acc: 0.978320
0it [00:00, ?it/s]Test Loss: 1.095920, Acc: 0.743900
************************* epoch 46 *************************
196it [00:43, 4.48it/s]
Finish 46 epoch, Loss: 0.023772, Acc: 0.996000
0it [00:00, ?it/s]Test Loss: 1.250700, Acc: 0.736100
************************* epoch 47 *************************
196it [00:44, 4.41it/s]
Finish 47 epoch, Loss: 0.013472, Acc: 0.998060
0it [00:00, ?it/s]Test Loss: 1.363737, Acc: 0.739100
************************* epoch 48 *************************
196it [00:44, 4.44it/s]
Finish 48 epoch, Loss: 0.008261, Acc: 0.999160
0it [00:00, ?it/s]Test Loss: 1.361765, Acc: 0.745700
************************* epoch 49 *************************
196it [00:43, 4.48it/s]
Finish 49 epoch, Loss: 0.005402, Acc: 0.999560
0it [00:00, ?it/s]Test Loss: 1.441942, Acc: 0.744200
************************* epoch 50 *************************
196it [00:43, 4.49it/s]
Finish 50 epoch, Loss: 0.003578, Acc: 0.999760
Test Loss: 1.482398, Acc: 0.745400
Keras(TensorFlow)版
GPU使用与分配
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # 按照PCI_BUS_ID顺序从0开始排列GPU设备
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 设置当前使用的GPU设备仅为0号设备 设备名称为'/gpu:0'
gpus = tf.config.experimental.list_physical_devices("GPU") # 将 GPU 的显存使用策略设置为 “仅在需要时申请显存空间”
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
except RuntimeError as e:
print(e)
exit(1) # 有错误时退出
数据导入
- dataload.py文件:读取数据(数据的预处理命令的定义)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from tensorflow.keras import backend as K
import numpy as np
import os
import sys
from six.moves import cPickle
def load_batch(fpath, label_key='labels'):
"""Internal utility for parsing CIFAR data.
# Arguments
fpath: path the file to parse.
label_key: key for label data in the retrieve
dictionary.
# Returns
A tuple `(data, labels)`.
"""
with open(fpath, 'rb') as f:
if sys.version_info < (3,):
d = cPickle.load(f)
else:
d = cPickle.load(f, encoding='bytes')
# decode utf8
d_decoded = {}
for k, v in d.items():
d_decoded[k.decode('utf8')] = v
d = d_decoded
data = d['data']
labels = d[label_key]
data = data.reshape(data.shape[0], 3, 32, 32)
return data, labels
def load_data(ROOT):
""" 加载CIFAR1数据集
# Returns
Tuple of Numpy arrays: `(x_train, y_train), (x_test, y_test)`.
"""
path = ROOT
num_train_samples = 50000
x_train = np.empty((num_train_samples, 3, 32, 32), dtype='uint8')
y_train = np.empty((num_train_samples,), dtype='uint8')
for i in range(1, 6):
fpath = os.path.join(path, 'data_batch_' + str(i))
(x_train[(i - 1) * 10000: i * 10000, :, :, :],
y_train[(i - 1) * 10000: i * 10000]) = load_batch(fpath)
fpath = os.path.join(path, 'test_batch')
x_test, y_test = load_batch(fpath)
y_train = np.reshape(y_train, (len(y_train), 1))
y_test = np.reshape(y_test, (len(y_test), 1))
if K.image_data_format() == 'channels_last':
x_train = x_train.transpose(0, 2, 3, 1)
x_test = x_test.transpose(0, 2, 3, 1)
return (x_train, y_train), (x_test, y_test)
- 数据导入
(x_train, y_train), (x_test, y_test) = load_data('D:\TASK\VGG\DATA\datasets\cifar-10-batches-py')
模型
代码如下:
''' 库的导入 '''
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D,MaxPooling2D
from tensorflow.keras.layers import Flatten,Dense,Dropout
''' 模型构建 '''
model = Sequential()
# 卷积层
model.add(Conv2D(64,(3,3), strides = (1,1), input_shape = (32,32,3), padding = 'same', activation = 'relu'))
model.add(Conv2D(64,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D((2,2), strides = (2,2)))
model.add(Conv2D(128,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(128,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D((2,2), strides = (2,2)))
model.add(Conv2D(256,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(256,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(256,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D((2,2), strides = (2,2)))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D((2,2), strides = (2,2)))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(512,(3,3), strides = (1,1), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D((2,2), strides = (2,2)))
# 全连接层
model.add(Flatten())
model.add(Dense(4096, activation = 'relu'))
model.add(Dense(4096, activation = 'relu'))
model.add(Dense(1000, activation = 'softmax'))
model.summary() # 对模型进行展示,即输出模型的参数情况
''' 定义优化器 '''
model.compile(optimizer=keras.optimizers.Adam(0.0001), # 优化器,其中0.0001为学习率
loss=keras.losses.sparse_categorical_crossentropy, # 损失函数
metrics=["accuracy"]) # 标注网络评价指标 "accuracy" : y_ 和 y 都是数值,如y_ = [1] y = [1] 其中y_为真实值,y为预测值
模型展示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_11 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 1, 1, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 4096) 2101248
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
=================================================================
Total params: 37,694,248
Trainable params: 37,694,248
Non-trainable params: 0
_________________________________________________________________
训练并测试模型
''' 数据可视化 '''
Tensorboard = TensorBoard(log_dir="logs", histogram_freq=1)
# histogram_freq:对于模型中各个层计算激活值和模型权重直方图的频率
# log_dir: 用来保存被 TensorBoard 分析的日志文件的文件名。
history = model.fit(x_train, y_train,
epochs=50, callbacks=[Tensorboard],
batch_size=256,
validation_data=(x_test, y_test))
'''
元组 (x_val,y_val) 用来评估损失,以及在每轮结束时的任何模型度量指标;模型将不会在这个数据上进行训练。
'''
结果(截取部分)
