Rnn Lstm Gru Sru学习小结
1.Rnn
Rnn的详细介绍可以参考
深度学习之RNN(循环神经网络)
零基础入门深度学习(5) - 循环神经网络
详解循环神经网络(Recurrent Neural Network)
基本原理和算法可以参考下图:
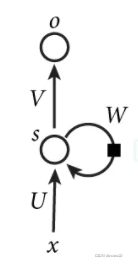
这里表示的是一个Rnn单元。
由左图可以知道Rnn单元的计算公式:

这里O(t)是当前时刻的输出,S(t)是当前时刻的隐藏层状态。X(t)是当前的输入,它是一个词根的向量表示,向量由x1、x2、x3...等分量组成。注意这里x1、x2、x3要和循环神经网络的Rnn单元展开的输入X(t)区别:
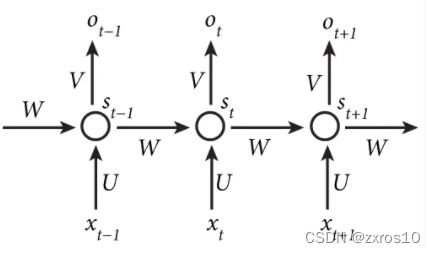
上图是一个Rnn单元在三个时刻的状态画在一张图上。X(t-1)、X(t)、X(t+1)是在t-1、t、t+1三个时刻的输入。每个时刻输入的都是一个词根,都是(x1, x2, x3, ...)组成的向量。
同理,O(t)和S(t)也是不同时刻的输出,也是向量,由若干分量组成。
Rnn有两个问题:
1. 梯度爆炸和消失。具体分析可以参考RNN梯度消失和爆炸的原因
2. 很难处理长距离的依赖。在前向过程中,开始时刻的输入对后面时刻的影响越来越小,失去了“记忆”的能力
2.Lstm
为了解决Rnn的问题,提出了Lstm。Lstm解决梯度爆炸和消失问题可以参考LSTM如何解决梯度弥散和爆炸问题
Lstm在Rnn的基础上增加了三个门(输入门、输出门、遗忘门)和一个记忆单元

Lstm的结构如下图所示
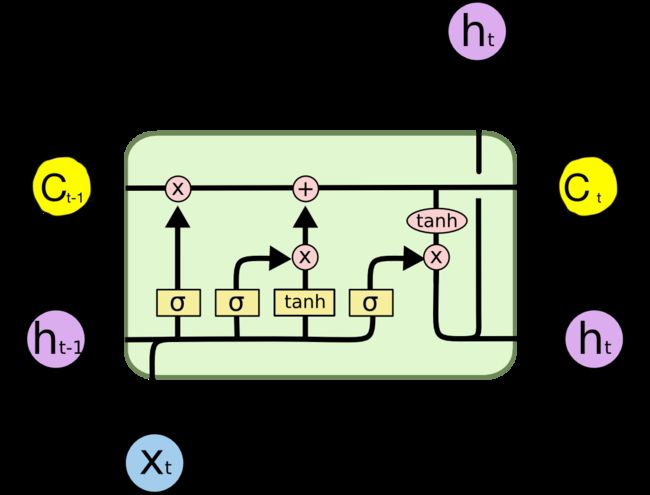
其中C(t-1)是上一时刻的记忆单元状态,h(t-1)是上一时刻的输出,X(t)是当前时刻的输入,C(t)是当前更新后的记忆单元状态,h(t)是当前的输出。σ表示sigmod函数。另外一个激活函数是tanh
遗忘门
遗忘门决定上一时刻的记忆状态有多少保留到当前状态
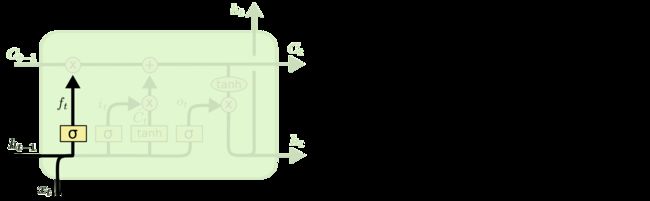
这里[h(t-1), x(t)]表示两个分量的拼接,是遗忘门的控制信号,也就是上一时刻的输出和当前的输入共同控制有多少记忆保留到当前。
输入门
输入门控制当前输入有多少用作更新当前状态
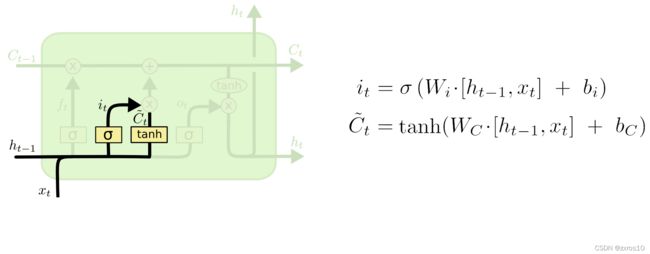 这里分两部分:
这里分两部分:
1. i(t)是输入门层,作为控制信号
2. C^(t)是当前用来更新的信息,它是[h(t-1), x(t)]使用tanh归一化后的数据
输出门
输出门控制当前状态C(t)有多少作为当前输出
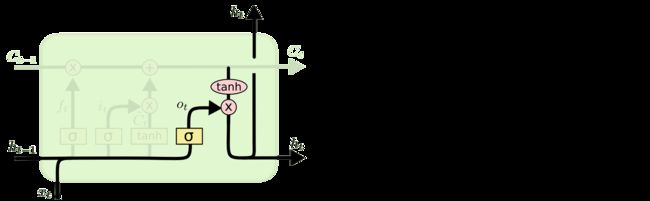
这里也分两部分:
1. o(t)为控制信号。
2. 当前状态C(t)经过tanh归一化后,由o(t)控制作为当前的输出h(t)
Lstm的缺点
1.只是部分解决了RNN梯度消失问题。序列长度超过一定限度后,梯度还是会消失。
2.计算量大且无法并行计算,训练困难
参考:
https://blog.csdn.net/qian99/article/details/88628383
https://blog.csdn.net/weixin_44901453/article/details/105383056
https://zybuluo.com/hanbingtao/note/581764
3. Gru
循环门单元Gru(Gated Recurrent Unit,GRU)是Lstm的一种变体。和Lstm相比,主要改变有:
1.将Lstm的遗忘门和输入门替换为一个单独的“更新门”;
2.合并记忆单元状态和隐藏层状态
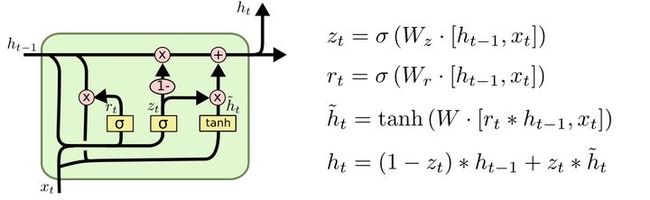
GRU有两个门,分别是reset gate r(t)和更新门z(t)。h^(t)为当前用作更新的数据,称为候选隐藏层。
重置门控制前一状态有多少信息被写入到当前的候选隐藏层h^(t-1)。重置门越小,前一状态的信息被写入的越少。
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。
一般来说那些具有短距离依赖的单元reset gate比较活跃(如果 r(t) 为1,而 z(t) 为0 那么相当于变成了一个标准的RNN,能处理短距离依赖);具有长距离依赖的单元update gate比较活跃。
GRU参数更少,收敛快
参考:
深入理解lstm及其变种gru
深度学习之GRU网络
4. Sru
SRU表示简单循环单元,结构如下:
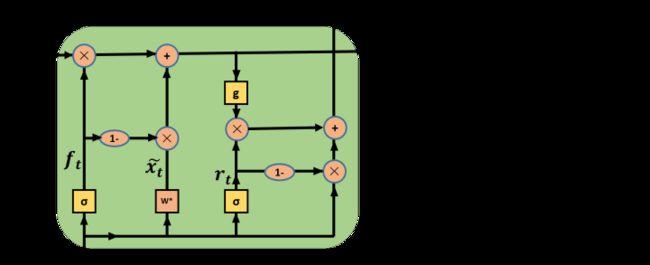
f(t)表示遗忘门,r(t)为重置门。
SRU与卷积和前馈网络具有相同的并行度。这是通过平衡顺序依赖和独立来实现的:虽然SRU的状态计算是依赖于时间的,但是每个状态维是独立的。这种简化使cuda级优化能够跨隐藏维度和时间步长并行化计算,有效地利用现代gpu的全部容量。
SRU代替了卷积的使用。与QRNN和KNN一样,具有更多的循环连接。这保留了建模能力,同时使用更少的计算(和超参数)。
SRU通过使用高速公路连接和为深度架构中的梯度传播量身定制的参数初始化方案,改进了深度递归模型的训练。
参考:
爆款论文提出简单循环单元SRU:像CNN一样快速训练RNN(附开源代码)
【干货】神经网络SRU
SRU