【论文简述】AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network(CVPR 2021)
一、论文简述
1. 第一作者:Zizhuang Wei
2. 发表年份:2021
3. 发表期刊:CVPR
4. 关键词:MVS、深度学习、可变形卷积、自适应聚合、LSTM
5. 探索动机:普通卷积对于薄结构和弱文理区域的特征提取效果有限,具有上下文感知的特征没有被充分利用;很少有研究在多视图匹配代价聚合过程中考虑像素可见性问题:从粗到细的结构成功地降低了内存消耗,但由于深度间隔较大,粗阶段的深度预测可能会出错,因此不适用于高分辨率深度重建;3D CNN内存开销太高,因此近期很多方法都在使用循环卷积的结构。
- general features extracted by 2D CNN in regular pixel grids with fixed receptive fields often have difficulties in handling thin structures or textureless surfaces, which limits the robustness and completeness of 3D reconstruction. Recent MVSNet-based attempts introduce multi-scale information to improve depth estimation. However, context-aware features have not been leveraged well enough for varying richness of texture on different regions.
- few works consider pixel-wise visibility issues during multi-view matching cost aggregation, which inevitably deteriorates the final reconstruction quality, especially under severe occlusion.
- Though the coarse-to-fine architectures successfully reduce memory consumption, they are not suitable for highresolution depth reconstructions as the depth prediction of coarse stage may be wrong with a large depth interval.
- in order to meet the needs of various realworld applications, memory consumption is also essential for a scalable MVS algorithm. Instead of using 3D CNN, some recent methods apply recurrent convolution structure for cost volume regularization, which is effective and memory efficient to reconstruct scenes with wide ranges of depth.
6. 工作目标:根据以上问题,是否可以提出一个新颖的循环卷积结构?
7. 核心思想:提出了一种基于长短期记忆(LSTM)的循环多视图立体网络,该网络同时具有视图内和视图间自适应聚合模块,即AA-RMVSNet。
- 引入视图内(intra-view)特征聚合模块,利用可变形卷积和多尺度聚合自适应提取图像特征,视图内方案用于鲁棒特征提取,其中上下文感知的特征自适应地聚合了多个尺度和具有丰富纹理的区域的信息;
- 提出了一个视图间(inter-view)代价体聚合模块,通过为每个视图生成像素级注意力图,自适应地聚合不同视图的代价体,目的是通过在匹配良好的视图对上分配更高的权重来克服复杂场景下不同遮挡的困难
8. 实验结果:在各种数据集上取得了优异的性能。在Tanks and Temples基准测试中排名第一,在DTU数据集上取得了具有竞争力的结果,具有较强的泛化性和鲁棒性。
9. 论文下载:
https://openaccess.thecvf.com/content/ICCV2021/papers/Wei_AA-RMVSNet_Adaptive_Aggregation_Recurrent_Multi-View_Stereo_Network_ICCV_2021_paper.pdf
https://github.com/QT-Zhu/AA-RMVSNet
二、实现过程
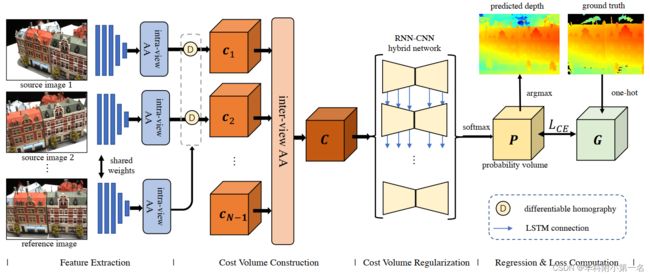
1. AA-RMVSNet:概述
AA-RMVSNet由4个阶段组成。视图内AA模块聚合了多个尺度和具有不丰富纹理的区域的上下文感知特征。视图间AA模块通过为每个视图生成像素级注意力图,自适应地聚合不同视图的代价体。采用RNN-CNN混合网络以循环的逐片模式对代价体进行正则化。最后,采用交叉熵进行像素级分类,计算反向传播的损失。
原文对于基于学习的MVS的流程做了非常规范的表述,建议反复阅读。
2. 视图内自适应聚合模块
目的:三维重建中使用普通CNN提取特征时,由于使用固定的2D网格感受野,经常会在反射、低纹理或无纹理区域出现问题,因此希望这些区域特征的卷积感受野大一些、在纹理丰富的区域感受野小一些。 因此设计视图内自适应聚合模块,如下图:

- 通过编码器(灰白色部分)特征提取3个不同空间尺度的特征图,分别为H×W×16、H/2×W/2×16和H/4×W/4×16;
- 分别送入3个使用可变形卷积核(3x3)、参数不共享的卷积层进一步聚合特征;
- 将尺度分别为[[H/2, ,W/2, 8]、[H/4, W/4, 8],进行x2,x4的双线性插值来统一尺度为[H,W, 8];
- 延通道维度连接最终得到[H, W, 16+8+8]的特征图。
可变形卷积定义为:

其中f(p)表示像素点p的特征,wk和pk分别为普通卷积层中卷积核参数和固定偏移量,Δpk和Δmk为通过可变形卷积层的可学习的子网络产生自适应的偏移和调整权重。通过将更小的特征图插值大小为H × W,得到3个通道分别为16,8,8的特征图,并将这些特征连接成H × W × 32的特征图。
3. 视图间自适应聚合模块
在构建了每个视图的代价体之后,下一步是将所有代价体聚合为一个以进行正则化。
一种常见的做法是求N-1个代价体的平均值,其基本原则是所有视图都应该同等重要。然而,这是不够合理的,因为不同的拍摄角度可能会导致诸如遮挡和非兰伯表面的不同照明条件等问题,使深度估计更加困难。为了让不同视角根据相似程度为本视角下特征赋予不同权重,设计视图间自适应聚合模块,如下图:

- 经过视图内自适应聚合模块,得到各视图特征体C1 — CN-1([H,W,32,D])
- 各视图特征体的深度d的特征图Ci(d)([H,W,32])通过中间通道数分别为4,4,4,1的卷积最终输出一张的注意力权重图[H,W,1]
- 注意力权重图与特征图Ci(d)做哈达玛积,再加上特征图切片Ci(d)构成该深度最终的特征图切片([H,W,32])
- 对N-1个视图同一深度d切片下的注意力特征体求平均,得到最终代价体的深度d的特征图([H,W,32])。
- 沿着通道维度相加得到最终的代价体([H,W,32,D])
用公式表述上述过程为:

⊙表示哈达玛积(对应像素相乘),ω(·)是根据每张图的代价体自适应生成的像素级的注意力图。通过这种方式,可能会混淆匹配的像素将被抑制,而那些具有关键上下文信息的像素将被分配更大的权重。其中,1+ω(·)比单独使用ω(·)能更好地避免过度的平滑化。
4. 循环代价体正则化
代价体正则化步骤是利用空间上下文信息,将匹配代价转为在D个深度假设平面上的概率分布,本文采用RNN - CNN混合方式来进行正则化。将代价体(H×W×Dx32)在深度维度上切片出D个深度代价图(H×W×32),正则化网络中的特征传递有水平方向和垂直方向:
- 在水平方向,通过使用2D CNN编码器-解码器结构来聚合空间上下文信息和正则化;
- 在垂直方向,通过5个并行的RNN结构来将前一个ConvLSTMCell的中间输出传递给后一个ConvLSTMCell
并行RNN中的ConvLSTMCell模块来自论文《Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking》(D2HC-RMVSNet),基本就是普通的LSTM模块引入,这里不展开介绍。通过这样的混合网络,既实现了空间上下文和深度方向上的信息聚合与正则化,同时减少了内存消耗(类似RMVSNet原理)
参考:https://blog.csdn.net/qq_41794040/article/details/128184731?spm=1001.2014.3001.5502
5. 损失函数
由于代价体正则化将匹配代价转化为深度假设的像素级概率分布,因此深度估计的任务现在类似于像素级分类问题。因此,通过对真实值进行one-hot模式编码,我们采用交叉熵来计算训练损失,定义为

其中G(d)(p)和P(d)(p)表示像素p处深度假设d的真实概率和预测概率。{pv}是具有可信深度的有效像素的集合。
6. 实验
6.1. 数据集
DTU Dataset
Tanks and Temples Benchmark
Evaluation of Tanks and Temples benchmark is done online by uploading reconstructed point clouds to its official website.
BlendedMVS dataset
BlendedMVS dataset [35] is a recently published large-scale synthetic dataset for multi-view stereo training containing a variety of indoor and outdoor scenes, such as cities, architectures, sculptures and shoes.The dataset consists of over 17k high-resolution images and is split into 106 training scenes and 7 validation scenes.However, this dataset does not officially provide evaluation tools, so we utilize BlendedMVS dataset for network finetuning and qualitative evaluation.
6.2 评估指标
Evaluation Metrics.the accuracy and the completeness of the distance metric are used for DTU dataset while the accuracy and the completeness of the percentage metric for Tanks and Temple dataset.In order to obtain a summary measure for the accuracy and the completeness, the mean value of them is employed for the distance metric and the F1 score is utilized for the percentage metric.
6.3. 实现
训练:使用DTU数据集训练。深度图尺寸为160×128。输入视图数N = 3,图像大小裁剪到160 × 128,输入图像的总数设置为N = 7,深度值的样本总数设置为D = 192。Dmin和dmax分别固定为425mm和935mm。通过PyTorch实现,Adam为优化器。batch size为4,在4张NVIDIA TITAN RTX显卡训练.培训阶段需要20.16GB内存,耗时约3天。
测试:由于训练阶段需要额外的内存来保存反向传播的中间梯度,AA-RMVSNet的测试阶段相对内存效率较高,因此它可以处理更高分辨率的图像和更细深度的平面假设。在测试阶段设置N = 7和D = 512,以获得更详细的深度图。为了适应网络,输入图像的高度和宽度必须是8的倍数。使用800 × 600分辨率的输入图像进行DTU评估。在测试BlendedMVS之前,在BlendedMVS的训练集上对网络进行微调,以提高各种场景的性能。使用768×576的原始图像和反向深度设置在BlendedMVS的验证集上测试网络。为了对Tanks and Temples进行基准测试,应用COLMAP-SfM来估计深度范围和相机参数。与MVSNet中的图像裁剪方法不同,将图像大小调整为1024 × 544或960 × 544来适配网络,这样就保留了图像边界附近的上下文信息。
滤波与融合:与MVSNet一致,使用光度一致性、几何一致性。
6.4. 结果
DTU数据集基准:SOTA,得益于视图内AA模块,该模块集成了多尺度和上下文感知特征,我们的方法能够估计更完整和连续的深度。由于深度图估计的改进,该方法在保留细节的情况下获得了更完整的三维密集点云。

DTU的可视化结果:重建点云更完整,边缘细节部分(红框)恢复很好。
Tanks and Temples基准:排名第一(Rank是表示所有8个场景的平均度量,是最终排序的依据),相比在DTU上排第一的CVP-MVSNet,在不同的场景下展现出了更强的泛化性。

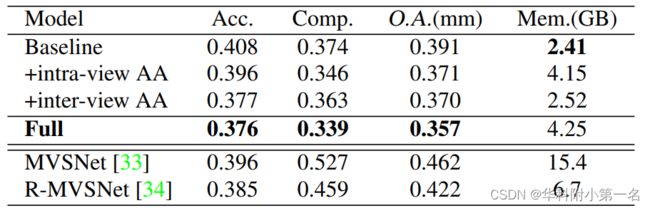
6.5. 消融实验
DTU评价数据集上不同部分的定量和内存表现。完整的AARMVSNet只需要4.25GB就可以获得800 × 600分辨率的密集而准确的深度图,这表明该方法内存效率很高。