机器学习学习整理(二)对数几率回归与支持向量机
文章目录
- 前言
- 对数几率回归
- 支持向量机
-
- 感知机
- 支持向量机
-
- 线性可分
- 近似线性可分
- 线性不可分
- 总结
前言
欢迎大家来看我的机器学习第二章,hhh这其实是第二次排版了,中午wifi坏了印象笔记没有自动保存,然后我写完之后点了下自动备份,它用我新建笔记的记录覆盖了我写完之后的记录…心累:)
拖更的时间有点久,这段时间基本把鲁伟老师的《机器学习 公式推导与代码实现》看完了,也有些自己的感悟,一直没有动笔是因为前段时间没太明白做这个的意义是什么,这些知识在书上已经很清晰了,想学的人大可以买一本自行阅读;嘛,反正这两天感觉There are thousand Hamlets in a thousand people’s eyes. 也许我比较通俗的理解可以带动一些初学的同学学习的热情?
跑远了,回归正题;机器学习整本书分为监督学习与无监督学习,本章我将介绍监督学习中除了线性回归我获益较深的对数几率回归与支持向量机;第三章我会开始介绍无监督学习并用个人的见解解释为什么称之为“无监督”第四章则是想和大家分享一个对聚类的小妙用,思想十分有意思,已经迫不及待写第四章了hhh
对数几率回归
之前的文章讲述了线性回归的基本思想:建立一个线性回归模型,基于这个模型不断输入训练数据进行最小二乘,使得这个模型与样本数据点的均方误差最小,以预测接下来输入的输入;但是很多时候我们希望我们的算法具有判断能力:
比如说我们是一群电商商人,我们有一批货物想卖出去,因此我们想把我们的商品推送给最有可能买的人。我们拥有过去访问过这批货物的用户记录,我们想通过这些记录里找出什么样的人最可能买我们的商品,之后我们便可以只把我们的商品推荐给符合这个判断标准的人。由于原数据很大我们不可能去用肉眼判断,那么我们可以把这个数据尝试从不同角度分类,例如:访问时间、访问地点、使用的手机(IOS/Android)/通过什么app访问的等等……我们可以把这些属性单独拿出来,分别列一个是否购买的表,然后把这些表合起来便可以知道什么样的人最可能购买我们的商品了。
提到是否购买,无非是买了(1)和没买(0);这是不是让一些学过信号与系统的同学们想到了sgn函数?没错我第一反应也是符号函数,但是我们想一想,如果使用sgn函数,像上一章一样处理后续步骤的时候会涉及到很多导数运算,sgn函数虽然很方便但是求导特性确实不尽人意(不连续)这会导致后续的决策概率不连续,会引出一些新的问题;那么不如让我们把思路放在良好的求导特性上,于是我们很快想到了我们今天的主角—sigmoid函数。
sigmoid函数:
sigmoid函数刚好满足所有我们对模型函数的需求:良好的求导特性、单调可微、0,1分类、连续
 sigmoid求导特性:
sigmoid求导特性:
那么我们只需要依照线性回归的思路照葫芦画瓢来建立对数几率回归模型即可:
线性回归模型:
代入sigmoid函数,

把x解放出来,于是两边取对数:

这便是对数几率模型的表达式了~
y是取1(正例)的概率,1-y为取0(反例)的可能性,
 称为几率(odds)
称为几率(odds)
同样的,我们想要确定这个模型,我们需要求出w和b,求w和b又需要我们求损失函数(最小二乘法)
接下来一些简短的计算:
y可以取1可以取0,那么我们用概率的知识来看:
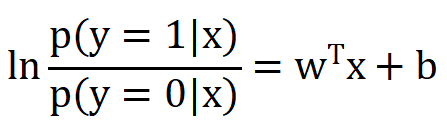
展开:


令
可以得到
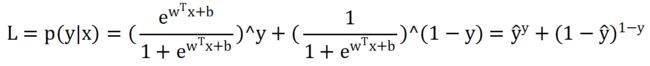
在L中对w,b求偏导:
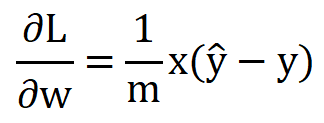

这下,基于w和b的梯度下降对损失的最小值,便是模型最优参数
怎么样,是不是和线性回归长得很像hhh,在回归前用sigmoid函数分类,再对这个表达式求损失函数,找到损失最小的点,便是对数几率回归的基本思想了。
支持向量机
要介绍支持向量机,各位同学应该先明确感知机是什么;感知机作为神经网络的理论基础,我们还是有必要来了解一下的。
感知机
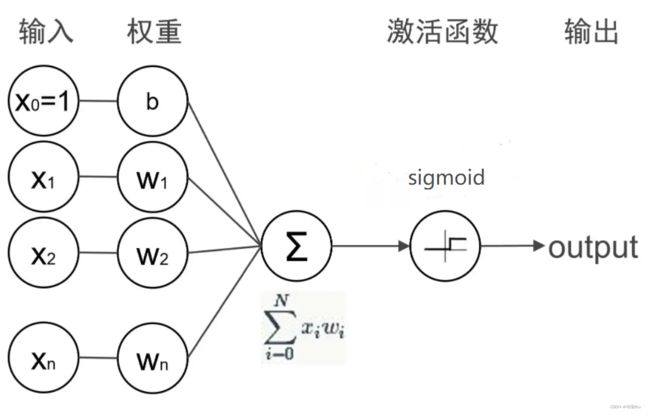
从我的理解,感知机无非是一个线性系统,它支持每一级前向、反向传播,它存在的意义是建立一个线性分割超平面,把输入按照正例反例分开:
线性可分问题图例:
这个过程其实和上文讲述的对数几率回归很像,涉及到正例反例,我们便想到了sigmoid函数,在上文对数几率回归的过程中:将输入与权重系数w进行加权求和,然后过一遍sigmoid函数进行输出;感知机需要在这个基础上根据你的输出和实际输出按照损失函数计算当前损失,计算损失函数关于权重和偏置的梯度,然后不断更新权重和偏置,以达到损失最小,这便是单层感知机的工作原理。
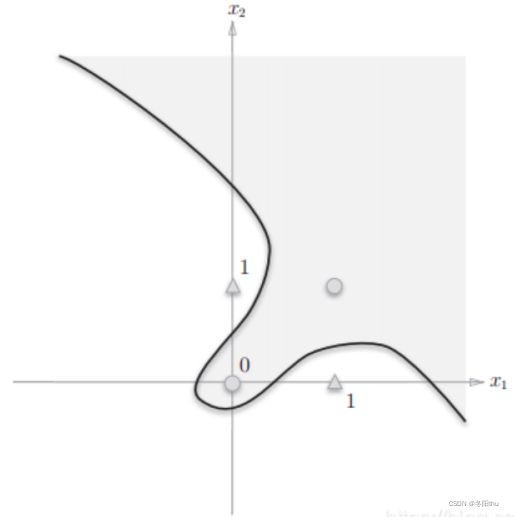
为了解决线性不可分的情况(无法用一条直线把正例反例分割)
我们引入了多层感知机和支持向量机:
线性不可分问题图例:
多层感知机:
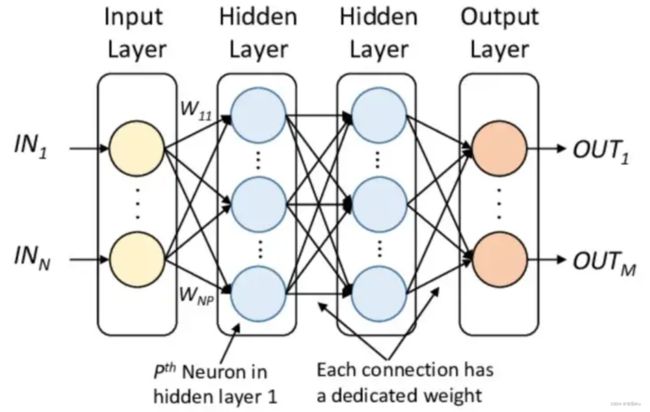
多层感知机中引入反向传播(BP),这样可以每步计算中都更新权重,来实现梯度下降,大家如果对反向传播可以参考一下具体介绍的文章,我感觉我也只是理解了皮毛hh
支持向量机
感知机的目的是把正例反例分开,最后会得出无数个满足条件的超平面,从感知机更进一步的是,支持向量机从感知机得出的无数个超平面中选取一个到两边的数据最大间隔的线性分割超平面。
根据问题类型我们可以总结三种情况:
1 线性可分
2 近似线性可分
3 线性不可分
线性可分
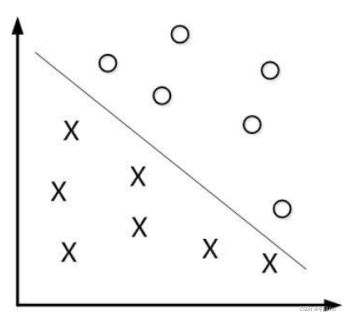 最通俗易懂的情况,一组数据包含A和B,A和B在离得很远,用一个到两边的数据最大间隔的线性超平面把A与B分隔开,我们可以先把间隔用数学语言表示出来,使它最大化:
最通俗易懂的情况,一组数据包含A和B,A和B在离得很远,用一个到两边的数据最大间隔的线性超平面把A与B分隔开,我们可以先把间隔用数学语言表示出来,使它最大化:
对于任意xi,yi,到超平面的间隔表示为:
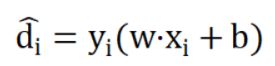
那么该训练集与超平面的间隔可以用最小间隔来表示,即:

为了使间隔不受参数w,b的影响,我们需要添加一个约束:
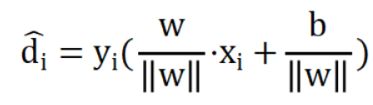
至此,我们便可以把问题形式化为一个条件约束最优化的问题;
运用拉格朗日函数对表达式进行一系列求解,可解得:
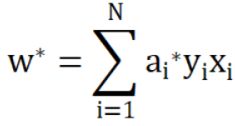
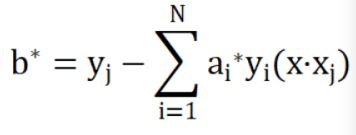
那我们便可以得到超平面方程:

近似线性可分

与线性可分不同,此时我们无法用一个超平面分割所有两类数据,我们便可以引入一个松弛变量(≥0),此时间隔成为软间隔,使得函数间隔加上松弛变量≥1,我们便认为可以满足近似线性可分;(推导过程与线性可分十分相似不再赘述)
线性不可分
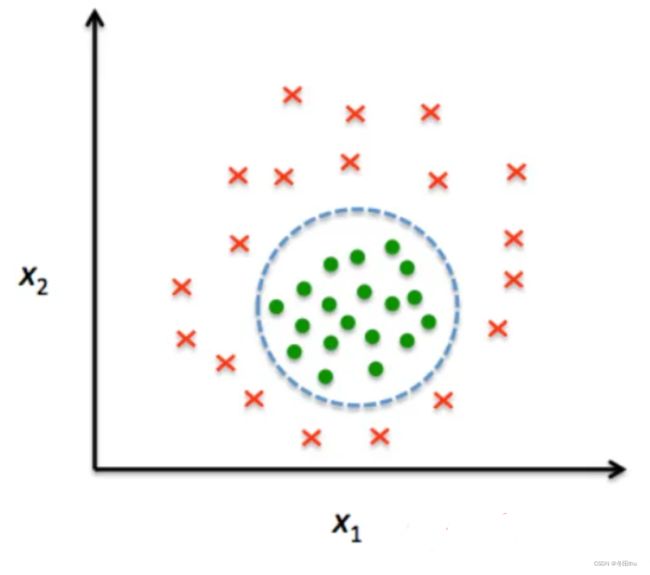
上图这种情况,我们最好的解决办法就是用一个圆把两类数据分开,可惜这并不是线性的,导致很难求解,于是我们可以进行非线性变化,把这个问题转化为线性问题,在支持向量机中,这个过程称作核技巧。
核技巧是将非线性变换为线性的映射方法,具体是引入高维特征空间,因为原始空间的维数有限,那么我们一定可以找一个高维空间使它线性可分。于是我们将原始空间的点映射到高维特征空间,使其线性可分,实现这个方法的主要工具是核函数,设输入空间A,特征空间B,存在一个A到B的映射φ(x),使所有x,z∈A,函数K(x,z)=φ(x)·φ(z),K(x,z)便是核函数,φ(x)便是映射函数。
有很多常用的核函数,例如高斯核函数,多项式核函数等等,如大家有需要可以直接搜索常用核函数,资源应当有很多;
总结
监督学习的部分就到这里了~该着手于写无监督学习部分和深度学习部分了
希望大家可以见到我的时候提醒我一下hhh(防止拖更
哦我的朋友,谢谢你能看到这!