R语言——(六)、线性回归模型
文章目录
- 回归分析*
- 问题提出*
- 一、 一元线性回归
- 二、一元线性回归的参数估计
-
- 1. 普通最小二乘估计(OLS)
- 2. 极大似然估计(MLE)
- 3.随机误差项μ的方差σ^2的估计
- 二、一元线性回归模型的检验
-
- 1. 拟合优度检验(R^2)
- 2. 解释变量的显著性检验(t test)
- 三、 一元线性回归的预测
-
- 1. 点预测
- 2. 区间预测
- 四、 多元线性回归分析
-
- 1. 模型估计
- 2. 模型检验
- 3. 模型预测
提示:以下是本篇文章正文内容,下面案例可供参考,以下纯属学习笔记。其中借助到了许多资料。书籍。
回归分析*
回归分析(regression analysis)是统计分析中最重要的思想之一
被广泛应用于社会经济现象中变量之间的影响因素分析
回归分为:线性回归、非线性回归
问题提出*
例1:为了研究家庭月消费支出与月可支配收入之间的关系,
随机调查了12户家庭,具体数据如下:
可支配收入(income):800,1100,1400,1700,2000,2300,2600,2900,3200,3500
消费支出(consume):594,638,1122,1155,1408,1595,1969,2078,2585,2530
consum=c(594,638,1122,1155,1408,1595,1969,2078,2585,2530)
income=c(800,1100,1400,1700,2000,2300,2600,2900,3200,3500)
#首先对数据探索性分析
cor(income,consum) #计算pearson相关系数
plot(income,consum) #画散点图
abline(lm(consum~income))#添加回归趋势线
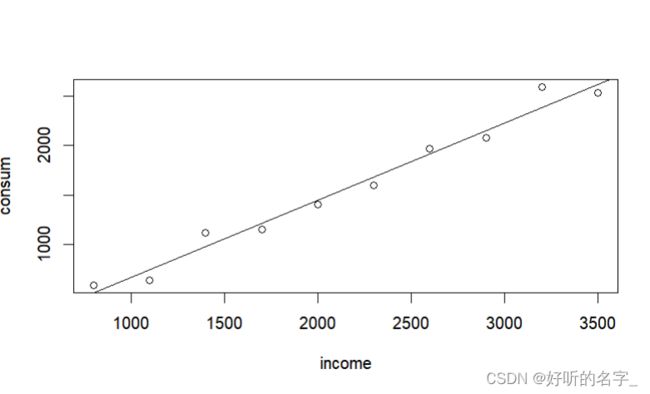
可以发现,income和consum之间具有较强的正线性关系
但是,从探索性结果并不知道这种线性关系的具体数量关系。
例2: 一组年龄与最大心率数据:
年龄Age (x): 18,23,25,35,65,54,34,56,72,19,23,42,18,39,37
最大心率MaxRate (y): 202,186,187,180,156,169,174,172,153,199,193,174,198,183,178
研究年龄与最大心率之间的关系。
x = c(18,23,25,35,65,54,34,56,72,19,23,42,18,39,37)
y=c(202,186,187,180,156,169,174,172,153,199,193,174,198,183,178)
探索性分析x、y之间的关系:
cor(x,y)#计算pearson相关系数
cor.test(x,y) #相关性检验
plot(x,y)
abline(lm(y~x))
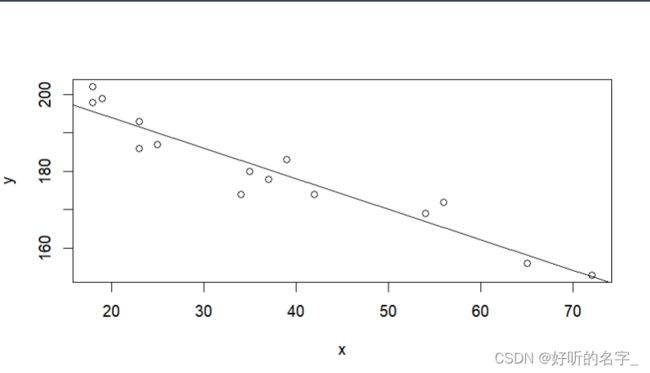
从以上分析可知,x,y之间具有很强的负(线性)相关性
但不知道具体的数量关系
以上两个例子中,想要知道两个变量之间的具体数量关系,
需要作线性回归分析
一、 一元线性回归
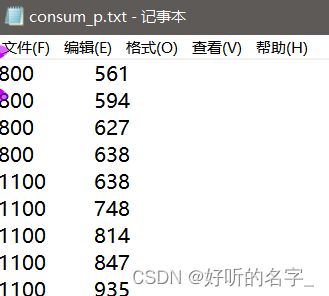
data=read.table("consum_p.txt")
data
x=data$V1 #定义可支配收入V1为x
y=data$V2 #定义消费支出V2为y
plot(x,y,xlab="x(可支配收入)",ylab="y(消费支出)")
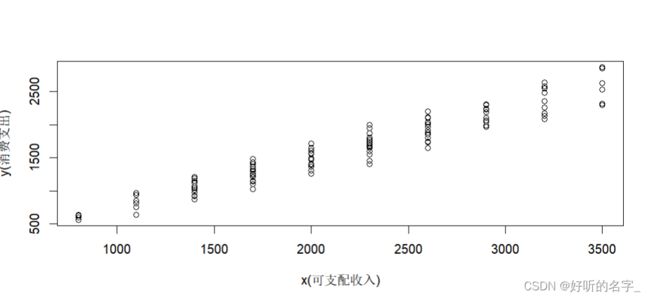
由散点图可知,家庭消费支出y的平均值随可支配收入x的增加而增加并且y的条件均值和收入x近似落在一条直线上,称这条直线即为回归线(总体的),相应的函数E(Y|Xi)=f(Xi)称为回归函数(总体的),总体回归函数,刻画了被解释变量Y的平均值随解释变量X变化的规律。
二、一元线性回归的参数估计
回归分析的目的:
通过样本回归模型尽可能准确地估计总体回归模型
回归模型中参数的估计方法很多,其中最常用的是:
普通最小二乘法(OLS)和极大似然估计法(MLE).
1. 普通最小二乘估计(OLS)
原理:使得样本观测值Y_i与拟合值Y_hat之间的差的平方和最小,从而达到估计模型参数的目的。
R中OLS估计的命令是:
lm(formula, data, subset, weights, na.action,
method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL, offset, ...)
-
formula表示回归模型里的表达式,一般为y~x,
-
前面是被解释变量,~ 后面是解释变量
默认模型中包含截距项
当不需要截距项时,在解释变量前面添加一项-1,即:y~-1+x
例1:上面收入与支出中的OLS估计:
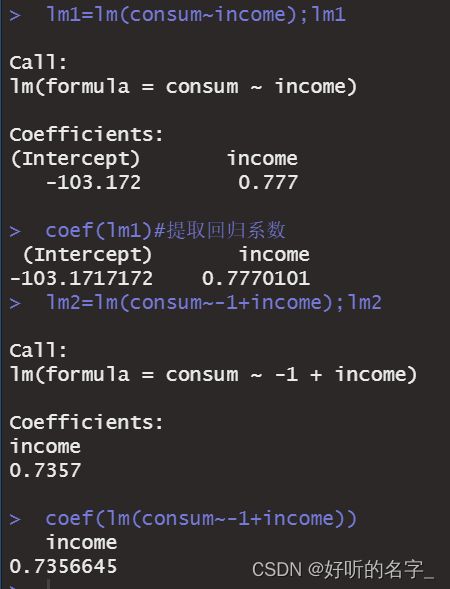
lm1=lm(consum~income);lm1
coef(lm1)#提取回归系数
lm2=lm(consum~-1+income);lm2
coef(lm(consum~-1+income))
例2:x和y的线性回归,OLS估计:
x = c(18,23,25,35,65,54,34,56,72,19,23,42,18,39,37)
y=c(202,186,187,180,156,169,174,172,153,199,193,174,198,183,178)
lm3=lm(y~x);lm3
coef(lm3)

2. 极大似然估计(MLE)
MLE的原理:利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
在满足基本假设条件下,模型的MLE估计与OLS估计是相同的。
R中,求MLE的函数是maxLik包中的maxLik()函数
但是,在求MLE之前,需要先写出对数似然函数的表达式
install.packages(“maxLik”)#安装极大似然估计函数包
library(maxLik) #或者使用require(maxLik)函数加载
定义对数似然函数的表达式:
loglik=function (para){
N=length(consum)#自变量(consum消费)的观测值个数
e=consum-para[1]-para[2]*income #消费的真实值与消费的估计值之间的误差(即为残差)
ll=-0.5*N*log(2*pi)-0.5*N*log(para[3]^2)-0.5*sum(e^2/para[3]^2)
return(ll)
}
然后可以使用maxLik()函数求MLE,命令:maxLik(logLik, start)
logLik为极大似然函数
start为参数的初始值,
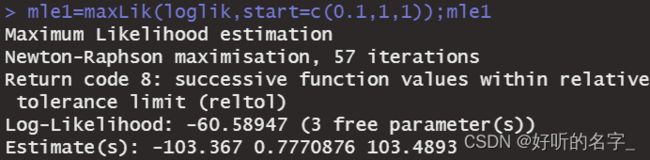
mle1=maxLik(loglik,start=c(0.1,1,1));mle1
start=c(0.1,1,1)中的0.1是指截距项的初始值,
第二个分量中的1是指解释变量回归系数的初始值,
第三个分量中的1是方差的初始值
coef(mle1)

coef(mle1)是返回极大似然估计的系数,
第一个系数-103.3670361是截距项
第二个系数0.7770876是自变量income的回归系数
第三个系数103.4893151是σ^2的估计值
可以发现,和前面的OLS估计结果一致
上面maxLik()函数的作用也等价于:
使得残差平方和最小,求得参数的估计值,
3.随机误差项μ的方差σ^2的估计
R中,估计误差项μ的方差σ^2时,
需要先利用summary()函数将OLS估计的结果
保存到一个对象中,然后在该对象中提取sigma成分(即(σ_hat)^2)
求收入、支出方差σ^2的估计结果:
consum=c(594,638,1122,1155,1408,1595,1969,2078,2585,2530)
income=c(800,1100,1400,1700,2000,2300,2600,2900,3200,3500)
lm1=lm(consum~income);lm1
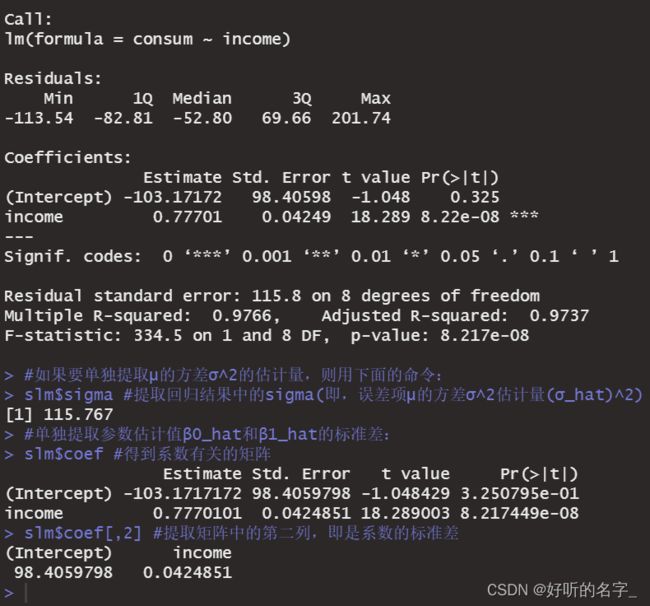
slm<-summary(lm1)#将lm()的结果lm1保存到一个对象slm中
slm
#如果要单独提取μ的方差σ^2的估计量,则用下面的命令:
slm$sigma #提取回归结果中的sigma(即,误差项μ的方差σ^2估计量(σ_hat)^2)
#单独提取参数估计值β0_hat和β1_hat的标准差:
slm$coef #得到系数有关的矩阵
slm$coef[,2] #提取矩阵中的第二列,即是系数的标准差
二、一元线性回归模型的检验
模型检验主要包括:
拟合优度检验(可决系数R^2);
变量的显著性检验(t检验)。
1. 拟合优度检验(R^2)
拟合优度检验,是检验模型对观测值的拟合程度;
拟合优度用指标R^2度量;
0 <= R^2 <= 1,R^2越接近1,说明拟合程度越高,模型越好。
通常,R^2 >= 0.8 时认为模型的拟合程度较好。
求R^2非常简单,在模型回归结果中提取即可,命令是:保存回归结果的对象$r.squared
2. 解释变量的显著性检验(t test)
模型检验的第二个内容是:
检验解释变量x是否为被解释变量Y的一个显著影响因素。
检验的统计量为 t 统计量
在R中,summary()函数会自动提供线性回归的t检验统计量,
可以通过命名: “回归结果的存储对象$coef” 提取,
可以提取到 “回归系数的估计值、标准差、t值、相应的P值”。
例如:
slm<-summary(lm1)
slm
slm$coef[,3]#提取相应矩阵中的第3列,即t值
slm$coef[,4]#提取相应矩阵中的第4列,即P值

从t统计量相应的P值可知:
β0_hat的t值为-1.048429,相应P值为3.250795e-01, 大于0.05,说明β0_hat不显著;
β1_hat的t值为18.289003,相应P值为8.217449e-08, 小于0.05,说明β1_hat显著。
三、 一元线性回归的预测
分为:点预测、区间预测
1. 点预测
(1).样本点外的解释变量观测值X0所对应的Y0_hat的预测值,
将x0带入回归模型中即可:
Y0_hat <- slm$coef[,1][1]+ slm$coef[,1][2]*4000; Y0_hat
Y0_hat <- coef(lm1)[1]+coef(lm1)[2]*4000; Y0_hat
Y0_hat也可以利用函数predict(),
但这需要在回归结果lm1基础上,且X0的格式要求是数据框的形式。
Y0_hat <- predict(lm1,newdata=data.frame(income=4000))
Y0_hat
(2).求样本内X给定下Y_hat的值:
在回归结果lm1上调用函数fitted()即可。
fitted(lm1)
round(fitted(lm1),2)#保留2位小数
如果想要返回残差,则在回归结果lm1上调用resid()函数即可:
resid(lm1)
round(resid(lm1),2)#保留2位小数
plot(resid(lm1))#画残差的散点图
2. 区间预测
(1)均值E(Y0|X0)的区间预测:
predict(lm1,newdata=data.frame(income=4000),interval="confidence",level=0.95)
#注意在设置参数interval时,要设置为"confidence"
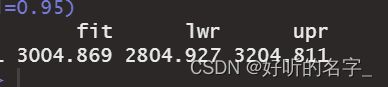
预测结果中,fit=3004.869为点预测,
lwr=2804.927, upr=3204.811 分别为区间预测的下限和上限。
(2)Y0的区间预测:
predict(lm1,newdata=data.frame(income=4000),interval="prediction",level=0.95)
#注意在设置参数interval时,要设置为"prediction"
为了比较均值的预测区间和个值的预测区间,
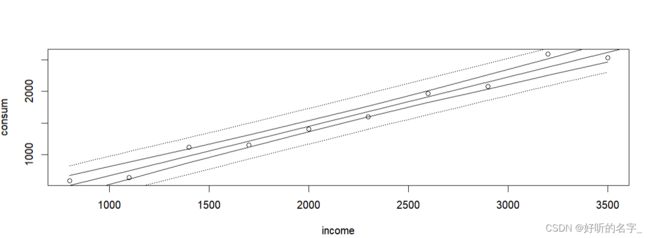
将样本内观测值、回归线、均值预测区间,个值预测区间画在同一张图上:
par(mfrow=c(1,1))
sx=sort(income) # 先将自变量income的值从小到大排序
conf = predict(lm1,data.frame(income=sx),interval="confidence")#求所有均值的预测区间
conf
pred = predict(lm1,data.frame(income=sx),interval="prediction")#求所有个值的预测区间
pred
plot(income,consum); #画散点图
abline(lm1) # 添加回归线
lines(sx,conf[,2]); lines(sx,conf[,3])#添加总体均值的95%置信区间
lines(sx,pred[,2],lty=3); lines(sx,pred[,3],lty=3)
#添加个体值的95%置信区间,lty=3是指虚线表示
四、 多元线性回归分析
1. 模型估计
例:研究中国税收收入增长的主要影响因素:
被解释变量:税收tax (Y)
解释变量:GDP (X1)、财政支出expand (X2)、物价指数CPI (X3)
模型设定:Y=β0+β1X1+β2X2+β3*X3+μ
模型估计:OLS估计
dat<-read.csv(file="tax.csv"); dat
lm3=lm(tax~GDP+expand+CPI,data=dat);lm3
lm4=lm(tax~GDP+expand+CPI+0,data=dat);lm4 #表示模型不含截距项
lm4=lm(tax~GDP+expand+CPI-1,data=dat);lm4
lm5=lm(tax~-1+GDP+expand+CPI,data=dat);lm5 #同样表示模型不含截距项
coef(lm3)
模型估计:MLE估计
attach(dat)
loglik=function (para){
#para[5]=sigma
N=length(tax)
e=tax-para[1]-para[2]*GDP-para[3]*expand-para[4]*CPI
ll=-N*log(sqrt(2*pi)*para[5])-(1/(2*para[5]^2))*sum(e^2)
#ll=-0.5*N*log(2*pi)-0.5*N*log(para[5]^2)-0.5*sum(e^2/para[5]^2)
return(ll)
}
library(maxLik)
mle3=maxLik(loglik,start=c(6616,0.04,0.6,58,100),iterlim=10000)
mle3
coef(mle3)
detach()
2. 模型检验
(1)模型检验:拟合优度检验
检验模型的拟合优度
slm3<-summary(lm3)
slm3$r.squared
slm3$adj.r.squared #提取调整的可决系数

(2)模型检验:检验模型整体显著性
summary(lm3)
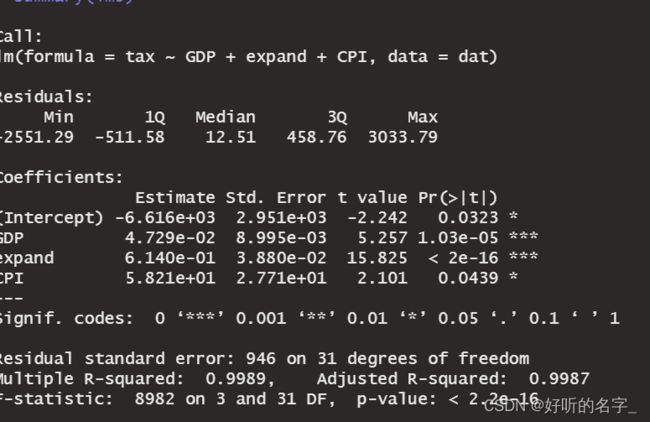
查看F统计量及对应的P值
F统计量为8982,对应P值为2.2e-16 < 0.05,说明模型整体显著。
(3)模型检验:检验各变量显著性
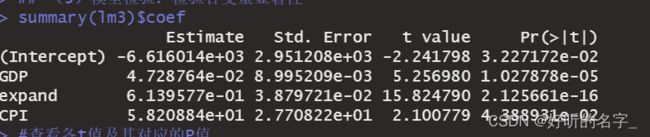
summary(lm3)$coef
#查看各t值及其对应的P值
#全部变量都显著
summary(lm3)
3. 模型预测
(1)单值预测
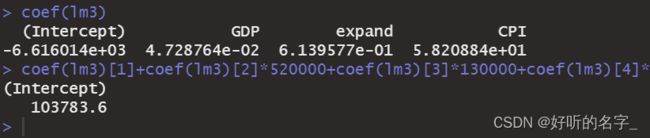
在上述例子假设2013年的GDP为520000亿元,财政支出expand为130000亿元,物价指数CPI为103%,预测2013年我国的税收tax。
coef(lm3)
coef(lm3)[1]+coef(lm3)[2]*520000+coef(lm3)[3]*130000+coef(lm3)[4]*103
(2)区间预测:E(Y0)和Y0的区间预测
求E(Y0)的预测区间时,设置参数interval=“confidence”
求Y0的预测区间时,设置参数interval=“prediction”
predict(lm3,interval="confidence")#E(Y0)的区间预测
predict(lm3,interval="prediction")#Y0的区间预测
predict(lm3,newdata=data.frame(GDP=520000,expand=130000,CPI=103),interval="confidence")
predict(lm3,newdata=data.frame(GDP=520000,expand=130000,CPI=103),interval="prediction")
参考教材:《R数据分析方法与案例详解》