[2022-10-30]神经网络与深度学习 hw7 - 第五章课后题(1×1 卷积核 | CNN BP)
contents
- hw7 - 第五章课后题(1×1 卷积核 | CNN BP)
-
- task1(5-2)
-
- 题目内容
- 题目思路
- 题目过程
- 题目总结
- task2(5-3)
-
- 题目内容
- 题目思路
- 题目过程
- 题目总结
- task3(5-4)
-
- 题目内容
- 题目思路
- 题目解答
- 题目总结
- task4(5-7)
-
- 题目内容
- 题目思路
- 题目解答
-
- 前向计算过程
- 反向计算过程
- 题目总结
- task ex-1
-
- 题目内容
- 题目思路
- 题目解答
- 题目总结
- 写在最后
hw7 - 第五章课后题(1×1 卷积核 | CNN BP)
task1(5-2)
题目内容
证明宽卷积具有交换性,即
r o t 180 ( W ) ⊗ X = r o t 180 ( X ) ⊗ ~ W rot180(W) \otimes X=rot180(X)\tilde{\otimes}W rot180(W)⊗X=rot180(X)⊗~W
题目思路
首先思考宽卷积是什么:给定一个二维图像 X ∈ R M × N X\in\mathbb{R}^{M\times N} X∈RM×N,和一个二维卷积核 W ∈ R U × V W\in\mathbb{R}^{U\times V} W∈RU×V,对图像进行零填充,两端各补 U − 1 U-1 U−1和 V − 1 V-1 V−1个零,得到全填充的图像 X ~ ∈ R ( M + 2 U − 2 ) × ( N + 2 V − 2 ) \tilde{X}\in \mathbb{R}^{(M+2U-2)\times(N+2V-2)} X~∈R(M+2U−2)×(N+2V−2),即为宽卷积。
然后思考卷积运算过程,将过程代换成字母进行运算即可。
题目过程
我们假设输入为 1 × 3 × 3 1\times3\times3 1×3×3的矩阵 X X X,卷积核 W W W大小为 1 × 2 × 2 1\times2\times2 1×2×2,由于是宽卷积,因此输出 Y Y Y大小为 1 × 4 × 4 1\times4\times4 1×4×4,具体如下:
X = ( X 00 X 01 X 02 X 10 X 11 X 12 X 20 X 21 X 22 ) , − − − − − − − − − − − − − − W = ( W 00 W 01 W 10 W 11 ) X=\left( \begin{array}{l} X_{00}&X_{01}&X_{02} \\ X_{10}&X_{11}&X_{12} \\ X_{20}&X_{21}&X_{22} \end{array} \right), \\ --------------\\ W=\left( \begin{array}{l} W_{00}&W_{01} \\ W_{10}&W_{11} \end{array} \right) X=⎝ ⎛X00X10X20X01X11X21X02X12X22⎠ ⎞,−−−−−−−−−−−−−−W=(W00W10W01W11)
由计算可知,
r o t 180 ( W ) ⊗ X = ( W 11 W 10 W 01 W 00 ) ⊗ ( 0 0 0 0 0 0 X 00 X 01 X 02 0 0 X 10 X 11 X 12 0 0 X 20 X 21 X 22 0 0 0 0 0 0 ) rot180(W) \otimes X= \left( \begin{array}{l} W_{11}&W_{10} \\ W_{01}&W_{00} \end{array} \right) \otimes \left( \begin{array}{l} 0&0&0&0&0 \\ 0&X_{00}&X_{01}&X_{02}&0 \\ 0&X_{10}&X_{11}&X_{12}&0 \\ 0&X_{20}&X_{21}&X_{22}&0 \\ 0&0&0&0&0 \end{array} \right) rot180(W)⊗X=(W11W01W10W00)⊗⎝ ⎛000000X00X10X2000X01X11X2100X02X12X22000000⎠ ⎞
同时,
r o t 180 ( X ) ⊗ ~ W = ( X 22 X 21 X 20 X 12 X 11 X 10 X 02 X 01 X 00 ) ⊗ ( 0 0 0 0 0 0 0 0 0 0 0 0 0 0 W 00 W 01 0 0 0 0 W 10 W 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ) rot180(X)\tilde{\otimes}W = \left( \begin{array}{l} X_{22}&X_{21}&X_{20} \\ X_{12}&X_{11}&X_{10} \\ X_{02}&X_{01}&X_{00} \end{array} \right) \otimes \left( \begin{array}{l} 0&0&0&0&0&0 \\ 0&0&0&0&0&0 \\ 0& 0&W_{00}&W_{01}& 0&0 \\ 0&0&W_{10}&W_{11}& 0&0 \\ 0&0&0&0&0&0 \\ 0&0&0&0&0&0 \end{array} \right) rot180(X)⊗~W=⎝ ⎛X22X12X02X21X11X01X20X10X00⎠ ⎞⊗⎝ ⎛00000000000000W00W100000W01W1100000000000000⎠ ⎞
通过计算,我们显然发现,这两个计算得到的输出矩阵是相同的(不信可以自己再算一遍)。
==> r o t 180 ( W ) ⊗ X = r o t 180 ( X ) ⊗ ~ W rot180(W) \otimes X=rot180(X)\tilde{\otimes}W rot180(W)⊗X=rot180(X)⊗~W
□ \square □
题目总结
这题考察的就是卷积的运算方式,并且通过卷积运算来证明了宽卷积的交换性。
这边给出一张带入值的计算过程:
![[2022-10-30]神经网络与深度学习 hw7 - 第五章课后题(1×1 卷积核 | CNN BP)_第1张图片](http://img.e-com-net.com/image/info8/29c5f20d8b934f36958d011f63aa8d54.jpg)
task2(5-3)
题目内容
分析卷积神经网络中使用1×1卷积核作用。
题目思路
首先思考1×1的卷积核会将一个通道的输入变成什么样:显然是大小保持不变而统一乘上一个值,这样显然并没有什么作用;
然后思考1×1卷积核在多通道上的作用:如果输出和输入通道数不同,那么在经过1×1卷积相加后,我们能够得到相应的升维、降维后的输出。
再思考1×1和其他卷积核在相同的升维/降维操作中的区别:计算量不同。
由此进行分析,得到答案。
题目过程
答:1×1卷积核的作用为:
- 在输入输出方面,1×1卷积核能够方便地进行升维或降维,实现跨通道的信息交互;
- 在网络结构方面,1×1卷积核能够使得输入输出大小保持不变,同时加深网络层数,增加了网络的非线性;
- 在计算量方面,1×1的卷积核计算量小,便于计算。
题目总结
本题考察的是多通道卷积的过程和结果,并在这个过程和结果上对特定卷积核的效果进行分析。
我们以Inception v1为例,该网络结构如下:
![[2022-10-30]神经网络与深度学习 hw7 - 第五章课后题(1×1 卷积核 | CNN BP)_第2张图片](http://img.e-com-net.com/image/info8/7f81d7b0264a4ae18ab07b19b5b4df6c.jpg)
其中(a)为没加入1×1卷积的模块,(b)为加入了1×1卷积的模块。通过别人的计算,我们可知计算量:

显然可见,随着1×1将输入降维,计算量显著减少。
这边还有张非常直观的输出仅为1通道的1×1卷积:
![[2022-10-30]神经网络与深度学习 hw7 - 第五章课后题(1×1 卷积核 | CNN BP)_第3张图片](http://img.e-com-net.com/image/info8/cc11d969c8644a908232005876eb817b.jpg)
task3(5-4)
题目内容
对于一个输入为100×100×256的特征映射组,使用3×3的卷积核,输出为100×100×256的特征映射组的卷积层,求其时间和空间复杂度.如果引入一个1×1卷积核,先得到100 × 100×64的特征映射,再进行3×3的卷积,得到100 ×100×256的特征映射组,求其时间和空间复杂度。
题目思路
卷积神经网络的时间和空间复杂度主要是在卷积的矩阵运算上消耗的,通过将每个步骤进行计算即可得到。注意,该题有两问:引入和不引入1×1卷积核。
题目解答
不引入1×1卷积核时:
- 时间复杂度 O ( i n h × i n w × k e r n e l h × k e r n e l w × c h a n n e l i n × c h a n n e l o u t ) = 5898240000 O(in_{h}\times in_{w}\times kernel_{h}\times kernel_{w}\times channel_{in}\times channel_{out}) = 5898240000 O(inh×inw×kernelh×kernelw×channelin×channelout)=5898240000
- 空间复杂度 T ( i n h × i n w × c h a n n e l i n ) = 2560000 T(in_{h}\times in_{w}\times channel_{in} )=2560000 T(inh×inw×channelin)=2560000
引入1×1卷积核后:
- 时间复杂度为两部分的 O ( i n h × i n w × k e r n e l h × k e r n e l w × c h a n n e l i n × c h a n n e l o u t ) O(in_{h}\times in_{w}\times kernel_{h}\times kernel_{w}\times channel_{in}\times channel_{out}) O(inh×inw×kernelh×kernelw×channelin×channelout),加和求得为1638400000
- 空间复杂度为两部分 T ( i n h × i n w × c h a n n e l i n ) T(in_{h}\times in_{w}\times channel_{in} ) T(inh×inw×channelin),加和求得为3200000
题目总结
本题主要考察我们对于矩阵运算的了解和对时间空间复杂度的计算。同时,通过本题我们能够清楚地意识到1×1卷积在加速计算上的重要用处。
task4(5-7)
题目内容
忽略激活函数,分析卷积网络中卷积层的前向计算和反向传播是一种转置关系。
题目思路
首先我们了解卷积神经网络中的前向计算和反向计算过程,然后进行计算和证明即可。
题目解答
前向计算过程
前向计算过程可以用以前使用的图来代替:
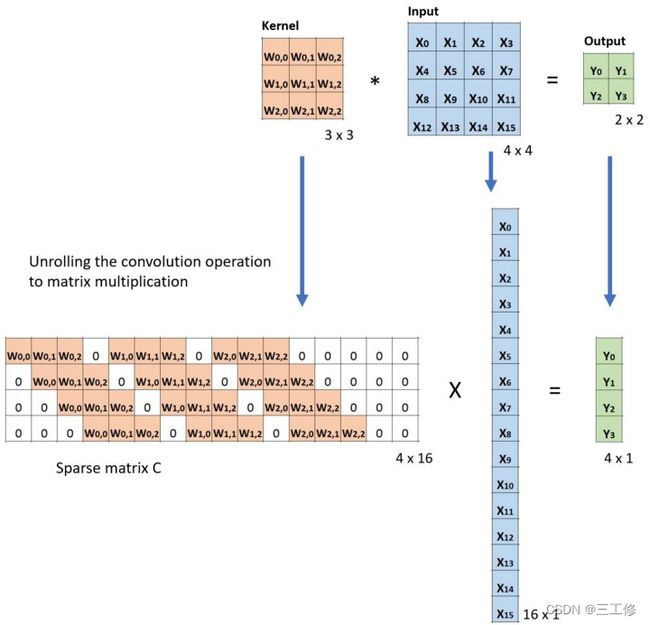
反向计算过程
反向计算依然需要计算每个参数的梯度。
由 ∂ L ∂ x i = ∑ j = 1 4 ∂ L ∂ y j ∂ y j ∂ x j = ∑ j = 1 4 ∂ L ∂ y j ⋅ W i j \frac{\partial L}{\partial x_i}=\sum_{j=1}^{4}\frac{\partial L}{\partial y_j}\frac{\partial y_j}{\partial x_j} = \sum_{j=1}{4}\frac{\partial L}{\partial y_j} \cdot W_{ij} ∂xi∂L=∑j=14∂yj∂L∂xj∂yj=∑j=14∂yj∂L⋅Wij
==> ∂ L ∂ X = ∂ L ∂ Y ( W 00 T W 01 T ⋮ W 22 T ) \frac{\partial L}{\partial X}=\frac{\partial L}{\partial Y}\left( \begin{array}{l} W_{00}^T \\ W_{01}^T \\ \vdots \\ W_{22}^T \end{array} \right) ∂X∂L=∂Y∂L⎝ ⎛W00TW01T⋮W22T⎠ ⎞
==> ∂ L ∂ X = W T ∂ L ∂ Y \frac{\partial L}{\partial X}=W^T \frac{\partial L}{\partial Y} ∂X∂L=WT∂Y∂L
□ \square □
题目总结
本题主要是通过矩阵的运算,让我们体验并认识到卷积前向、反向传播的过程和计算方法,通过计算发现的两者转置关系,我们能够更加方便地构建出代码。
task ex-1
题目内容
推导CNN反向传播算法。
题目思路
我们通过正向的思路进行反推,由前面得到的关系构建反向传播代码即可。
题目解答
代码在前面实验中定义的numpy卷积算子中进行构建,如下:
def backward(self, _grad_sum):
_grad_sum = _grad_sum.transpose(1, 2, 3, 0).reshape(self.out_channels, -1) # 将累计梯度重新按照图像(x,y,channel,batchsize)重组并拉平
grad_w = _grad_sum.dot(self.X_col.T).reshape(self.W.shape) # 计算梯度,重塑为卷积核形状用于卷积核参数的优化器
grad_bias = np.sum(_grad_sum, axis=1, keepdims=True) # 偏置值梯度
self.W = self.W_opt.update(self.W, grad_w)
self.bias = self.bias_opt.update(self.bias, grad_bias)
_grad_sum = self.W_col.T.dot(_grad_sum) # 累计梯度更新
_grad_sum = column2image(_grad_sum,
self._input.shape,
self.kernel_size,
stride=self.stride,
output_shape=self.padding) # 重新变形为输入图像形状
return _grad_sum
题目总结
本题考察了卷积过程反向传播的计算过程和代码实现。torch内置的卷积操作也是类似的,这边不再赘述。
写在最后
通过本次作业,我们回顾并熟悉了卷积神经网络中卷积层的特点、计算过程和误差逆传播过程,通过编码实现卷积层,我们也更熟悉了该层的计算过程和性质。特别地,我们了解并研究了1×1卷积核的各种优良性质,在后续网络优化中可以适当使用。