论文推荐:Rethinking Attention with Performers
重新思考的注意力机制,Performers是由谷歌,剑桥大学,DeepMind,和艾伦图灵研究所发布在2021 ICLR的论文已经超过500次引用
传统的Transformer的使用softmax 注意力,具有二次空间和时间复杂度。Performers是Transformer的一个变体,它利用一种新颖的通过正交随机特征方法 (FAVOR+) 快速注意力来有效地模拟 softmax 之外的可核化注意力机制来近似 softmax 注意力。
背景知识
传统Transformer由于softmax attention的存在,具有二次的空间和时间复杂度:
![]()
为解决上述问题,Performers提出了一些研究建议。
标准稀疏化技术
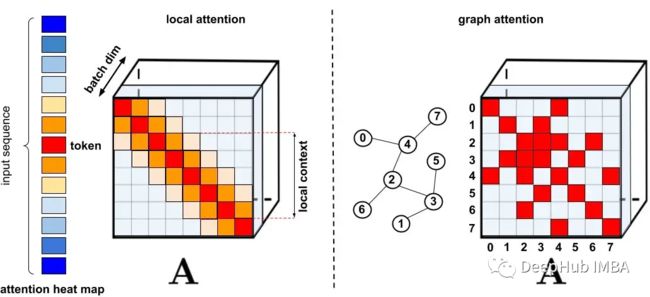
标准稀疏化技术。
左图:稀疏模式示例,其中令牌仅关注附近的其他令牌。
右图:在图注意力网络中,令牌仅关注图中的邻居,这些节点应该比其他节点具有更高的相关性。
Performer
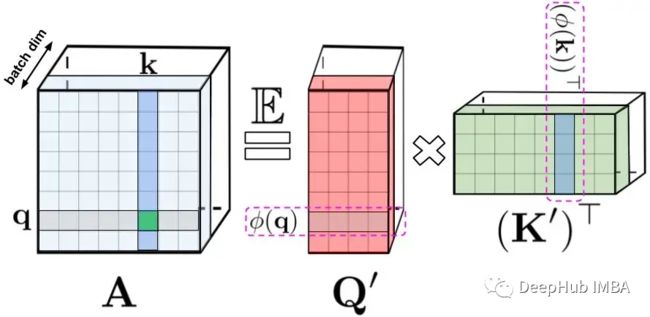
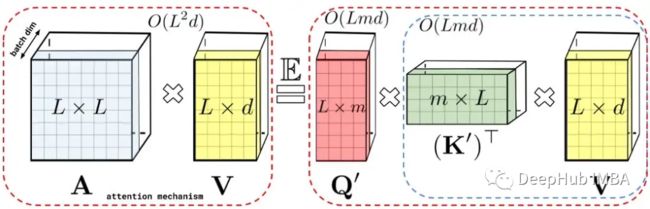
LHS:标准注意力矩阵,其中包含每对条目的所有相似性分数,由对查询和键的 softmax 用 q 和 k 表示。
RHS:标准注意力矩阵可以通过低阶随机矩阵 Q’ 和 K’ 来近似,其中行编码原始查询/键的潜在随机非线性函数。对于常规的 softmax-attention,这里的转换非常紧凑,涉及指数函数和随机高斯投影。
传统的Transformer自注意模块有Q, K, V,其中Q和K生成A,然后与V相互作用。Performer中矩阵A用低秩随机矩阵Q '和K '来近似,这是一种新的基于正交随机特征的快速注意方法(FAVOR+)。FAVOR+适用于注意力块,使用矩阵A的形式如下:
![]()
qi/kj代表Q/K中的第i/ j个查询/键行向量,内核K定义为(通常是随机的)映射Φ:
![]()
对于Q ', K ',行分别为Φ(qi)和Φ(ki)。
这里^Att↔代表近似注意,下图中的括号表示计算顺序:
![]()
对于某些分布D∈P(R^ D)(如高斯分布),函数f1,…,fl,函数h和确定性向量ωi或ω1,…,ωm, iid ~ D取如下形式的Φ:

形成有效的注意机制:
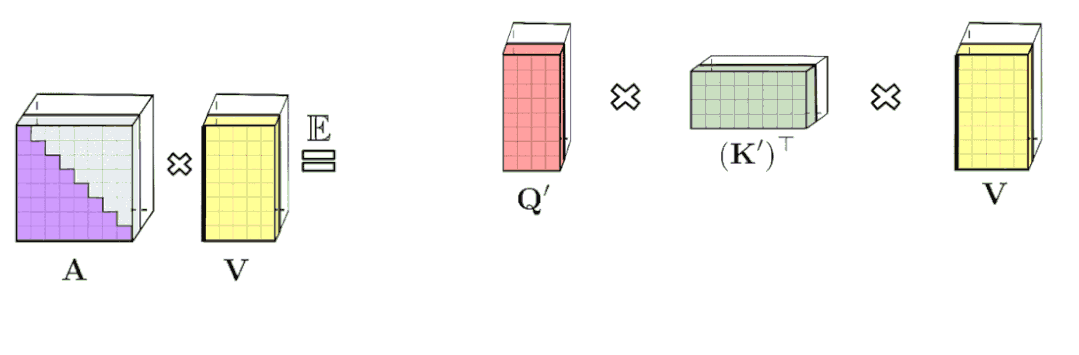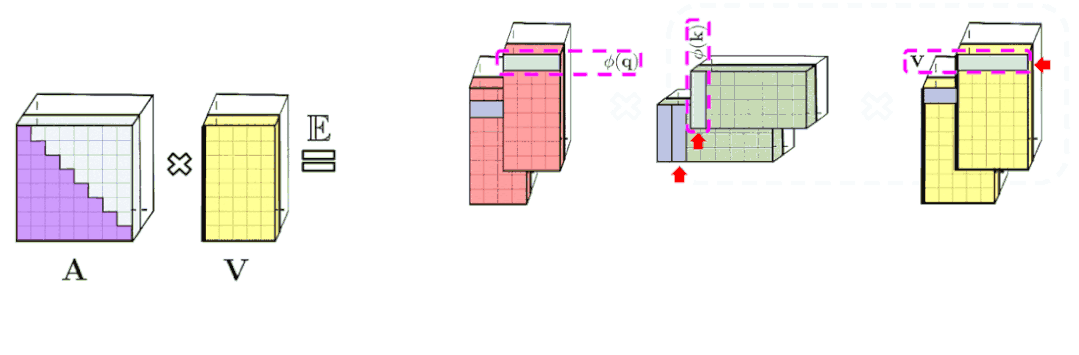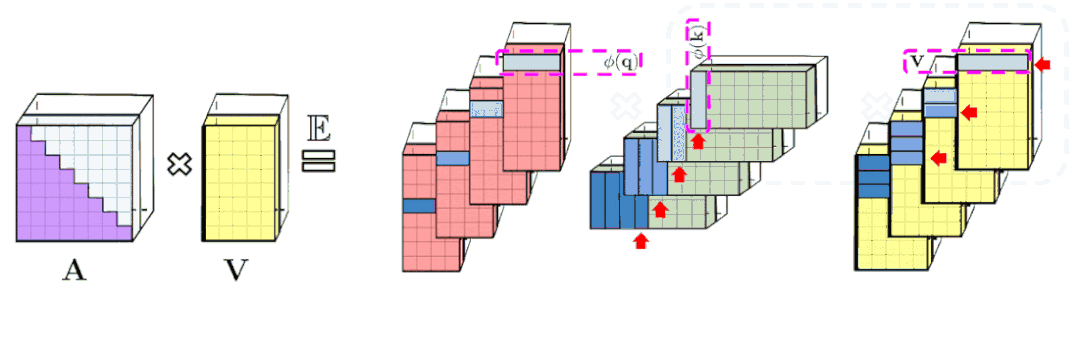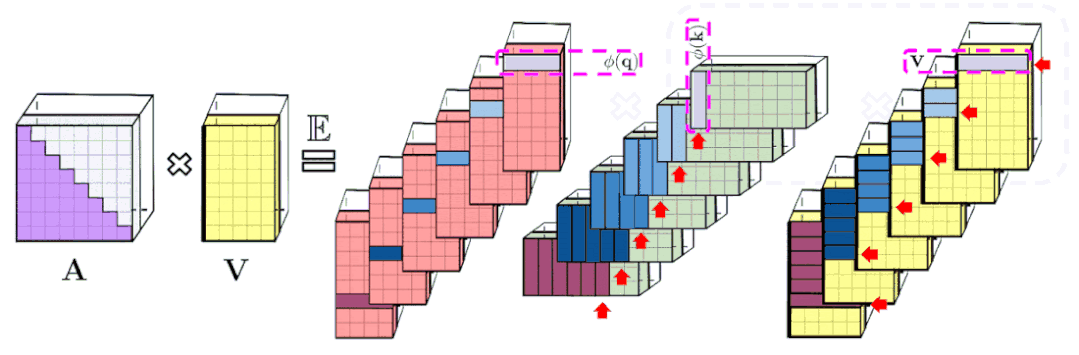
左图:标准单向注意需要遮蔽注意矩阵来获得它的下三角部分。
右:可以通过前缀求和机制获得 LHS 的无偏近似,其中键和值向量的随机特征图外积的前缀和是动态构建的,并与查询随机特征向量左乘 获得结果矩阵中的新行。
通过(随机)特征映射的规则注意机制AV (在D^(-1)-renormalization之前)的近似值。虚线块表示计算顺序,并附有相应的时间复杂度。
有了低秩近似/矩阵分解/矩阵分解的概念,空间和时间的复杂性变得更加线性。
结果展示
NLP 数据集
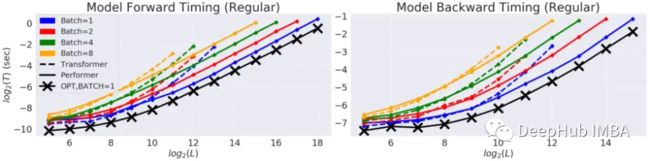
Transformer和Performer的前向和反向传递速度和允许的最大长度的比较
“X”(OPT)表示可实现的最大可能加速,此时注意力只是返回v矩阵。
Performer 几乎达到线性时间和次二次的内存消耗(因为显式O(L2)注意矩阵没有存储)。通过比较“X”,Performer实现了几乎最佳的加速和内存效率。
蛋白质序列数据集

使用2019年1月发布的TrEMBL中的蛋白质序列训练36层模型。Reformer和Linformer在蛋白质数据集上的准确性显著下降。
Performer-ReLU(取f=ReLU)在(U)和(B)两种情况下都达到了最高的精度。(U:单向,B:双向)

通过将来自 TrEMBL 的蛋白质序列连接到长度 L = 8192,尝试了一种蛋白质基准来预测蛋白质组之间的相互作用。
较小的 Transformer (nlayer = 3) 很快就限制在 19%,而 Performer 能够持续训练到 24%。
ImageNet64(图像生成)
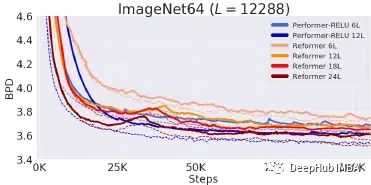
Performer/6 层匹配 Reformer/12 层,而 Performer/12 层匹配 Reformer/24 层。根据硬件(TPU 或 GPU),还发现通过针对 (U) 设置的 Jax 优化,Performer 可以比 Reformer 快 2 倍。Performer 使 Transformer 能够应用于更长的序列,而不受注意矩阵结构的限制,从而推进生物学和医学的应用(例如:非常长的蛋白质序列)。
论文地址:
[2021 ICLR] [Performer]Rethinking Attention with Performers
https://avoid.overfit.cn/post/4e5c93d291d94bd9ba1d06e0d8c0f4c9