论文:Improving One-stage Visual Grounding by Recursive Sub-query Construction
作者

摘要
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector,e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%,4.5%,7.5%,12.8% absolute improvements over the state-of-the-art one-stage approach on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling. Code is available at https://github.com/zyang-ur/ReSC.
我们通过解决当前对长而复杂查询进行grounding的限制,改进了单阶段Visual grounding。现有的单阶段方法将整个语言查询编码为一个句子嵌入向量,如从BERT中获取嵌入或从LSTM中获取隐藏状态。这种单一向量表示容易忽略查询中的详细描述。为了解决这种查询建模的不足,我们提出了一种递归子查询构造框架,该框架将图像和查询之间的关系进行多轮推理,并逐步减少引用歧义。我们证明了我们的新的一阶段方法与最先进的单阶段方法相比,在ReferItGame、RefCOCO、RefCOCO+和RefCOCOg上,得到了5.0%, 4.5%, 7.5%, 12.8%。特别是,在更长更复杂的查询上的优异性能验证了我们的query modeling的有效性。代码可在https://github. com/zyang-ur/ReSC。
Introduction
Visual grounding旨在将自然语言查询ground到图像的某个区域。Visual grounding的工作主要有两条主线:两阶段法[41,40,32,3,50,48]和一阶段法[47,5,37]。两阶段方法首先提取region proposal,然后根据其与查询的相似性对proposal进行排序。最近提出的单阶段方法采用了不同的范式,但很快就成为主流。一阶段方法在图像级融合视觉文本特征,并直接预测边界框以使参考对象grounding。通过对可能的对象位置进行密集采样并减少region proposal上的冗余计算,单阶段方法[47,5,37]简单、快速、准确。
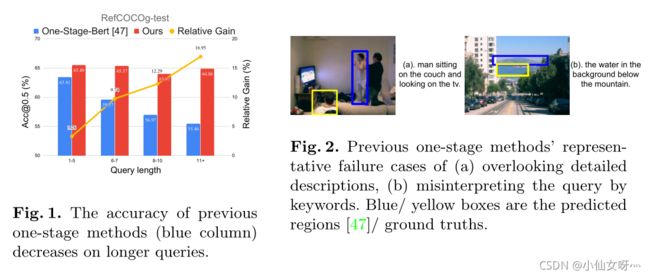
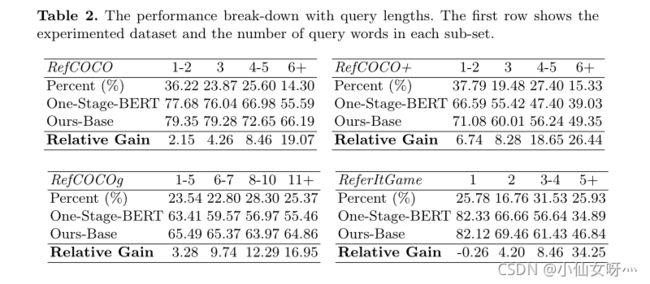
在本文中,我们改进了最先进的单阶段方法,解决了它们在建模长而复杂的查询时的弱点。我们的方法的整体优势如图1所示。与当前最先进的单阶段方法[47]相比,我们的方法在更长的查询中的性能显著下降,我们的方法取得了显著的优越性能。
我们分析了当前单阶段方法的局限性,如下所示。现有的单阶段方法[47,5,37]将整个query编码为单个embedding vector,例如,直接采用BERT[8,47]中的第一个token嵌入([CLS])或从LSTM[12,47,5,37]中聚合隐藏状态。然后将单个向量与视觉特征在所有空间位置连接,以获得用于grounding box预测的融合特征。将整个语言查询建模为单个嵌入向量往往会增加表示的模糊性,例如关注某些单词,而忽略其他重要单词。这样的问题可能会导致引用信息的丢失,特别是在那些长而复杂的查询上。例如,在图2(a)中,模型似乎忽略了诸如“坐在沙发上”或“看电视”之类的详细描述,并用头名词“man”将错误区域grounding。而在图2(b)中,模型似乎查看了错误的单词“mountain”,并将目标grounding,而没有充分考虑“mountain”的修饰语因此,忽略查询建模问题会导致单阶段方法的长查询性能下降。
几个两阶段的可视化基础工作[42,45,46,24,48,27]研究了类似的查询建模问题。这些工作的主要思想是将对象区域与解析的子查询链接起来,以全面理解引用。其中,MattNet[48]将查询解析为主题、位置和关系短语,并将每个短语与相关对象区域链接,以进行匹配分数计算。NMTREE[24]使用依赖树解析器[2]解析查询,并将每个树节点与可视区域链接。DGA[46]使用文本自我注意解析查询,并通过动态图形注意将文本与区域链接起来。这些方法虽然足够优雅,但直观地设计为两阶段方法,要求在第一阶段提取候选区域特征。由于进行一阶段可视化基础的主要好处是避免为了计算成本而显式提取候选区域特征,因此两阶段方法中的查询建模不能直接应用于一阶段框架[47,5,37]。因此,在本文中,为了在一个统一的单阶段框架中解决查询建模问题,我们提出了递归子查询构造框架。
当出现如图2(a)所示的引用问题时,人类倾向于通过在图像和查询之间来回推理多次来解决它,并递归地减少引用歧义,如包含引用对象的可能区域。受此启发,我们建议将每轮中引用的中间理解表示为文本条件视觉特征,该特征从图像特征开始,在多轮后更新,最终作为融合的视觉文本特征,为框预测做好准备。在每一轮中,该模型构造一个新的子查询,作为一组包含分数的词,以细化文本条件视觉特征。通过多次轮次,我们的模型逐渐减少了引用歧义。这种多轮解决方案与以前的单阶段方法不同,前者试图记住整个查询并在一轮中对区域进行定位。
我们的框架递归地构造子查询来细化基础预测。每一轮都面临两个有助于递归推理的核心问题,即1)如何构造子查询;以及2)如何使用子查询细化text conditional视觉特征。我们分别提出了一个子查询学习器和一个子查询调制网络来解决上述两个问题。它们交替和递归地工作,以减少引用的歧义。使用上一轮中的文本条件视觉特征,最终输出阶段将预测边界框以使引用对象固定。
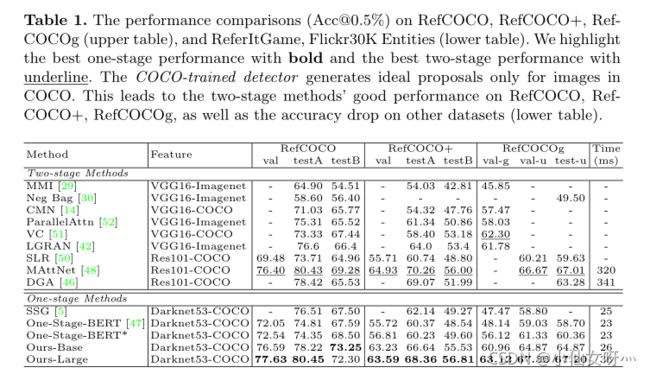
我们在ReferItGame[17]、RefCOCO[49]、RefCOCO[49]、RefCOCOg[29]数据集上对我们的框架进行了基准测试,共有5个数据集,提高了5.0%, 4.5%, 7.5%, 12.8%。同时,我们的方法以38fps(26ms)的速度运行。此外,图1中根据查询长度变化的相对增益曲线显示了我们的方法在解决上述查询建模问题方面的有效性。
我们的主要贡献有:
- 我们通过解决以前的一阶段方法在处理长而复杂的查询时的局限性,改进了一阶段Visual Grounding。
- 我们提出了一个递归子查询构造框架,该框架递归地减少了不同构造子查询的引用歧义。
- 我们提出的方法在多个数据集上显示了显著的改进结果,同时保持了实时推理速度。大量的实验和消融验证了我们方法的有效性。
Related Work
存在两大类Visual grounding方法:phrase localization [17,33,40]和referring expression comprehension[29,49,48,15,18]。大多数以前的Visual Grounding方法由两个阶段组成。在第一阶段,许多区域方案由off-line module生成,如EdgeBox[53]、选择性搜索[39]或预训练检测器[26,35,13]。在第二阶段,将每个区域与输入查询进行比较,并输出相似性分数。在推理过程中,将相似度得分最高的区域作为最终预测输出。在两阶段框架下,各种作品探索不同方面以改善视觉基础,如更好地利用属性[25,48,27]、对象关系[42,45,46,24]、短语共现phrase co-occurrences[4,9,1]等。
最近,一些工作[47,5,37,20,28]提出了一种不同的单阶段视觉基础范式。主要动机是解决两阶段方法的两个局限性,如,由于稀疏采样region proposal导致的性能上限,以及由于region特征计算导致的缓慢推理速度。一阶段方法不是显式地提取所有region proposal的特征,而是在所有空间位置密集地融合视觉文本特征,并直接预测边界框以使目标Grounding 。以前的单阶段方法通常将查询编码为单个语言向量,并沿视觉特征的通道维度连接特征。尽管单阶段方法很有效,但将语言查询建模为单个向量可能会导致引用信息的丢失,特别是在长而复杂的查询中。尽管两阶段方法[42,45,46,24,48,27]研究了语言查询建模的类似问题,但鉴于两种范式之间的内在差异,这些探索不能直接应用于一阶段方法。
此外,一个直观的替代方法是通过注意机制对查询短语进行建模。Linet al.[22]建议通过自我注意提取句子嵌入。在各种视觉语言任务中,还探索了带有注意机制的查询建模[19,48]。在实验中,我们观察到我们提出的多轮解决方案比简单的查询注意方法(参见表3中的“单/多头注意”和“子查询学习者(我们的)”更好)。
Approach

在本节中,我们将在一个统一的单阶段基础框架中介绍我们的查询建模。以前的一阶段基础方法将语言查询编码为 C l C_l Cl维语言特征,并将所有空间位置的文本特征与视觉特征连接起来 v ∈ R H × W × C v v∈R^{H×W×C_v} v∈RH×W×Cv。 H 、 W 、 C v H、 W、C_v H、W、Cv是视觉特征的高度、宽度和尺寸。视觉特征和文本特征通常在连接之前映射到同一维度C。额外的卷积层进一步细化融合特征 f ∈ R H × W × 2 C f∈R^{H×W×2C} f∈RH×W×2C,并预测每个空间位置 H × W H×W H×W处的边界框,以使目标Grounding。这种单轮查询建模往往会忽略重要的查询细节,并导致错误的预测。在更长更复杂的查询中,问题变得越来越严重,如图1所示。
为了在一个统一的one-stage Visual Grounding系统中解决这个问题,我们提出了一个递归子查询构造框架,该框架逐步细化 visual-text特征 v ( k ) v^{(k)} v(k)以获得更好的预测。如图3所示,初始特征 v ( 0 ) v^{(0)} v(0)是图像特征 v ∈ R H × W × C [ 34 ] v∈R^{H×W×C}[34] v∈RH×W×C[34]由视觉编码器编码的。在每轮 k k k中,该框架构造一个新的子查询作为一组带有分数向量 α ( k ) α^{(k)} α(k)的词,并获得子查询嵌入 q ( k ) q^{(k)} q(k)以细化视觉文本特征。该框架在 K K K轮之后以细化的特征 v ( K ) v^{(K)} v(K)结束,并预测 v ( K ) v^{(K)} v(K)的每个空间位置上的边界框以使目标Grounding。我们将 v ( K ) v^{(K)} v(K)命名为text-conditional visual feature。
在每一轮中,我们将讨论如何构造子查询以及如何通过子查询嵌入来细化特征 v ( k ) v^{(k)} v(k)以更好地定位目标。对于第一个问题,我们在第3.1节中提出了一个子查询学习器。目标是构造能够最好地解决当前引用歧义的子查询。我们发现在每一轮中参考文本条件视觉特征 v ( k ) v^{(k)} v(k)很重要。对于第二个问题,我们提出了一个子查询调制网络,该网络利用子查询特征缩放和移动特征 v ( k ) v^{(k)} v(k)。我们将在第3.2节中介绍细节。子查询学习器和调制网络交替进行多轮操作,递归地减少引用歧义。最后一轮中的特征 v ( K ) v^{(K)} v(K)包含完整的对象引用信息,并用于目标框预测。
3.1 Sub-query Learner
我们的方法将Visual Grounding问题处理为一个多轮推理过程。在每一轮中,子查询学习者引用文本条件视觉特征 v ( k ) v^{(k)} v(k)并构造子查询,该子查询可以逐渐减少引用歧义。
给定一个单词的语言查询,语言编码器提取每个单词的查询表示形式 S = { s n } n = 1 N S=\{s_n\}^{N}_{n=1} S={sn}n=1N,每个表示形式的维数为 C C C。如图3所示,子查询学习者在每一轮中构造一个子查询,作为一组单词,该词包含长度为 N N N的分数向量 α ( k ) = { α n ( k ) } n = 1 N α^{(k)}=\{α^{(k)}_n\}^{N}_{n=1} α(k)={αn(k)}n=1N。除了查询词特征 S S S外,我们发现在子查询构造中引用当前文本条件视觉特征 v ( k − 1 ) ∈ R H × W × C v^{(k−1)}∈R^{H×W×C} v(k−1)∈RH×W×C尤为重要,并因此取维度 C C C的average-pool特征 v ˉ ( k − 1 ) \bar{v}^{(k−1)} vˉ(k−1) 作为learner的额外输入。此外,前面子查询的历史记录有助于避免过分强调某些关键字。给定前面子查询的历史 { α ( i ) } i = 1 k − 1 \{α^{(i)}\}^{k-1}_{i=1} {α(i)}i=1k−1,历史向量 h ( k ) h^{(k)} h(k)表示先前参与的单词,计算如下

其中 1 1 1是全一向量。 h ( k ) h^{(k)} h(k)和 α ( i ) α^{(i)} α(i)都是N维向量,其值范围为0到1。子查询学习器采用查询词特征 { s n } n = 1 N \{s_n\}^{N}_{n=1} {sn}n=1N,文本条件视觉特征 v ˉ ( k − 1 ) \bar{v}^{(k−1)} vˉ(k−1) ,历史向量 h ( k ) = { h n ( k ) } n = 1 N h^{(k)}=\{h^{(k)}_n\}^{N}_{n=1} h(k)={hn(k)}n=1N,通过预测得分向量 α ( k ) α^{(k)} α(k)来构造 k k k轮的子查询:
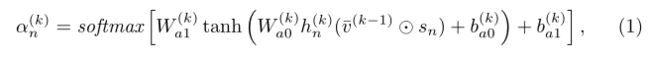
其中 ⊙ \odot ⊙表示hadamard乘积, W a 0 、 b a 0 、 W a 1 、 b a 1 W_{a0}、b_{a0}、W_{a1}、b_{a1} Wa0、ba0、Wa1、ba1是可学习的参数。我们计算 N N N个注意分数的softmax。
为了指导多轮推理,对单词注意分数进行显式正则化。直观地说,每轮构造的子查询都应该关注查询的不同元素,并且最终应该查看查询中的大多数单词。因此,我们添加了两个正则化项: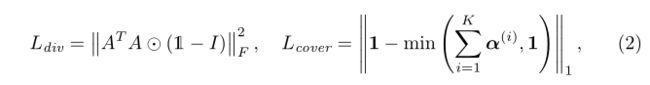
其中,矩阵A是预测注意得分矩阵 A = { α n ( k ) } n , k = 1 , 1 N , K A=\{α^{(k)}_n\}^{N,K}_{n,k=1,1} A={αn(k)}n,k=1,1N,K, 1 \mathbb{1} 1是ones的矩阵, I I I是identify矩阵。 L d i v L_{div} Ldiv避免在多轮中关注任何词语,从而加强多样性。 L c o v e r L_{cover} Lcover帮助模型查看查询中的所有单词,从而提高覆盖率。
所采用的基于注意的子查询学习技术与以前的合成推理研究有关[16,46]。主要区别在于,我们的方法引用文本条件视觉特性 v ( k ) v^{(k)} v(k)在每一轮中递归地构造子查询。相比之下,先前研究[16,46]中的子查询学习纯粹基于单词特征 S = { s n } n = 1 N S=\{s_n\}^{N}_{n=1} S={sn}n=1N,并在视觉文本融合之前生成所有子查询。
3.2 Sub-query Modulation
在每一轮中,sub-query learner将一个子查询构造为一组单词,并由分数向量 α ( k ) α^{(k)} α(k)表示,并生成子查询特征 q ( k ) q^{(k)} q(k),如下所示:

Sub-query Modulation的目标是使用新的子查询特征 q ( k ) q^{(k)} q(k)改善文本条件视觉特征 v ( k − 1 ) v^{(k-1)} v(k−1) ,使得改进的特征 v ( k ) v^{(k)} v(k)在grounding box预测中表现更好。
受图像级conditional normalization任务[7,10,31]的启发,我们对子查询表示 q ( k ) q^{(k)} q(k)进行编码,以调整先前的可视文本表示 v ( k − 1 ) v^{(k-1)} v(k−1) 通过缩放和移动。具体地说, q ( k ) q^{(k)} q(k)被分别投影到具有两个mlp的标度向量 γ ( k ) γ^{(k)} γ(k)和移位向量 β ( k ) β^{(k)} β(k)中:
 然后,文本条件视觉特征 v ( k ) v^{(k)} v(k)从 v ( k − 1 ) v^{(k-1)} v(k−1)和两个modulation vectors和extra learnable parameters中改进:
然后,文本条件视觉特征 v ( k ) v^{(k)} v(k)从 v ( k − 1 ) v^{(k-1)} v(k−1)和两个modulation vectors和extra learnable parameters中改进:
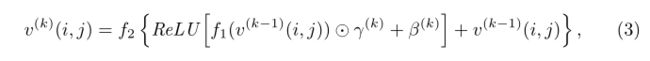 其中 ( i , j ) (i,j) (i,j)是空间坐标, f 1 , f 2 f_1,f_2 f1,f2是可学习的映射层,如图3所示。 f 1 f_1 f1由1×1卷积和实例规范化层组成。 f 2 f_2 f2包括3×3卷积,然后是批量标准化层和ReLU激活。grounding模块将最后一轮 v ( K ) v^{(K)} v(K)中的 text-conditional
其中 ( i , j ) (i,j) (i,j)是空间坐标, f 1 , f 2 f_1,f_2 f1,f2是可学习的映射层,如图3所示。 f 1 f_1 f1由1×1卷积和实例规范化层组成。 f 2 f_2 f2包括3×3卷积,然后是批量标准化层和ReLU激活。grounding模块将最后一轮 v ( K ) v^{(K)} v(K)中的 text-conditional
visual feature作为输入,并预测边界框以将参考对象接地。对于每个子查询 q ( k ) q^{(k)} q(k)中的额外参考信息,我们期望每轮中的调制增强参考对象的特征,同时抑制干扰对象和背景的特征。
我们在等式3中提出的子查询调制在所有空间位置 ( i , j ) (i,j) (i,j)上共享调制向量 γ ( k ) , β ( k ) γ(k),β(k) γ(k),β(k)。一种直观的替代方法是预测每个空间位置的不同调制矢量 γ ( k ) ( i , j ) 、 β ( k ) ( i , j ) γ^{(k)}(i,j)、β^{(k)}(i,j) γ(k)(i,j)、β(k)(i,j)。这可以通过使用相应的文本条件视觉特征 v ( k − 1 ) ( i , j ) v^{(k-1)}(i,j) v(k−1)(i,j)为每个位置构造子查询 α ( k ) ( i , j ) α^{(k)}(i,j) α(k)(i,j)来实现。尽管在不同的空间位置使用不同的调制参数似乎更直观,但我们表明,沿通道维度的调制实现了相同的目标,同时计算效率也很高(参见表3中的“空间独立子查询”和“子查询学习者(我们的)”部分)。
3.3 Framework details
Visual and text feature encoder
我们将输入图像的大小调整为3×256×256,并使用COCO目标检测[21]上预训练的Darknet-53[34]作为视觉编码器。我们采用了第102卷积层的视觉特征,其尺寸为32×32×256。我们将原始的视觉特征映射到具有1×1卷积层的视觉输入 v ( 0 ) v^{(0)} v(0)中,该卷积层具有批标准化和ReLU。我们将共享维度设置为 C = 512 C=512 C=512。
我们将查询中的每个单词编码为一个768D向量,并使用BERT[8,43]的无基版本。我们将最后四层中每个单词的表示相加,并将特征映射到两个完全连接的层,以获得表示 S = { s n } n = 1 N S=\{s_n\}^{N}_{n=1} S={sn}n=1N。N是query words的数量,不包括特殊tokens,如[CLS]、[SEP]和[PAD]。
Grounding module
接地模块将可视文本特征 v ( K ) v^{(K)} v(K)作为输入,并在每个空间位置生成目标预测,以使目标接地。我们使用与单阶段BERT[47]中相同的两个1×1卷积层进行盒预测。有32×32=1024个空间位置,我们预测每个位置有9个anchor box。我们使用相同的anchor box,遵循先前一级接地方法[47]中的anchor选择步骤。对于1024×9=9216anchor boxes中的每一个,我们预测相对偏移量和置信度得分。所有9216框上的softmax和one-hot target中心向量之间的交叉熵损失、相对位置和大小偏移的回归损失以及等式2中的正则化用于训练模型。我们使用与一个阶段中相同的分类和回归损失[47]。
Experiments

Conclusion
We have proposed a recursive sub-query construction framework to address the limitation of previous one-stage methods when understanding complex queries. We recursively construct sub-queries to refine the visual-text feature for grounding box prediction. Extensive experiments and ablation studies have validated the high effectiveness of our method. Our proposed framework significantly out-performs the state-of-the-art one-stage methods by over 5% in absolute accuracy on multiple datasets while still maintaining a real-time inference speed.
我们提出了一个递归子查询构造框架,以解决以前的单阶段方法在理解复杂查询时的局限性。我们递归地构造子查询来细化用于grounding box prediction的可视文本特征。大量的实验和消融研究已经证实了我们方法的高效性。我们提出的框架在多个数据集上的绝对准确度显著优于最先进的单阶段方法5%以上,同时仍保持实时推理速度。