详细介绍NLP对话系统
任务型对话系统
任务型对话系统主要应用于固定领域。任务型对话的广泛应用的方法有两种,一种是模块法,另一种是端到端的方法。
模块法是将对话响应视为模块,每个模块负责特定的任务,并将处理结果传送给下一个模块。
端到端的任务型对话系统不再独立地设计各个子模块,而是直接学习对话上下文到系统回复的映射关系,设计方法更简单。相关研究可以划分为两大类:基于检索的方法和基于生成的方法。

(NLU)模块的主要任务是将用户输入的自然语言映射为用户的意图和槽位。该模块的主要作用也是会以三元组的形式输出用户意图、槽位和槽位对应的槽值,输出给对话状态跟踪模块。
【案例分析】
用户输入:“今天北京天气怎么样”
用户意图定义:询问天气
槽位定义:
槽位一:时间
槽位二:地点
我们针对“询问天气 ”任务定义了两个必要槽位,是“时间 ”和“地点 ”。

意图和槽位
意图识别,就是将用户输入的自然语言会话进行划分类别,类别对应的就是用户的意图分类,例如“现在几点了 ”,其意图为“询问时间 ”。“今天气温多少度”,“询问天气的”。其实意图识别就是典型的分类问题,并且一般为多分类问题。也就是我们常用的文本分类任务。
意图识别的方法:基于SVM\TextCNN 等算法,也是通过序列标注、特征提取等方法,再经过模型训练的方式实现意图识别。
槽位,即意图对应的参数,确定意图之后(是问天气,还是查询图书),一个意图可以对应若干个参数。例如在线图书馆查找一本图书时,需要给出书名、作者、出版社等必要参数,以上参数即“查询图书 ”这一意图对应的槽位。
槽位填充的方法:槽位填充是序列标注问题,用机器学习HMM、SVM和深度学习RNN等算法都可以实现。
对话状态跟踪(DST)
填槽工作可能是通过多轮对话来完成,状态跟踪模块包括持续对话的各种信息,它根据旧状态(即对话历史),用户状态(即目前槽值填充情况)与系统状态(即通过与数据库的查询情况)来更新当前的对话状态。
系统与用户多轮对话,逐步明确用户需求,用户表达需求的过程,就是不断的填槽过程。

对话策略学习(DPL)
对话策略学习(DPL)是用来决策模型在当前状态下采取何种回复策略。
当用户输入语句后,由NLU、DST模块处理后形成3个结果向量。其中意图、槽位、槽值三个向量会拼接成一个高纬度的特征向量,输入LSTM模型。
LSTM经过Softmax激活函数输出系统当前时刻各系统动作的概率分布,再经过概率最大化取到概率最大元素所在索引等一些列动作处理和特定生成模板,生成系统的回复返回给用户。

自然语言生成(NLG)
自然语言生成(NLG)其目的是将语义表示转化为自然语言话语。
自然语言生成主要有三种生成方法:
(1)基于模板的方法。
通过预先设定好模板,进行自然语言生成,来返回给用户。例如已经为您预定{time}的从{origin}到{destination}的机票。
(2)基于语法规则的方法。
和自然语言理解中提到的方法类似,判断用户的语句是疑问句还是陈述句等,结合词性进行自然语言内容的生成。
(3)基于生成的方法。
通过依靠Seq2Seq等模型,计算上下文向量;最终Decoder部分结合Encoder的输入状态,上下文向量,以及Decoder的历史输入,预测当前输出对应于词典的概率分布。
在对话系统中,首先从训练语料中提取大量的问题模板,并构成一个对应的模板池。从问题集里通过关系向量与答案模板池多对多对应。
闲聊式对话系统
闲聊式对话系统也被称为开放领域对话系统,或者聊天机器人。
闲聊式对话系统是无任务驱动、为了纯聊天或者娱乐而开发的,它的目的是生成有意义且相关的内容回复。
开放领域闲聊式对话系统主要分为检索式和生成式对话系统。在检索式对话系统通过对用户的输入信息先进行查询和排序,再给出最佳答案的方法。生成式对话系统是通过已有的语料生成新文本作为回答。目前生成式闲聊对话系统的研究属性大于应用属性,很多问题尚在探索阶段。
检索式对话系统
检索式对话系统通过匹配技术从预定义数据库中检索与用户查询匹配的话语并排序,选取出排名最高的回复,核心是如何构建较好的查询-回复匹配模型。
案例分析:最简单的对话系统
import random
# 提问数据存储
greetings = ['你好', 'hello', 'hi', '早上好', 'hey!','hey']
# 随机函数选择提问
random_greeting = random.choice(greetings)
# 对于“你好吗? ”这个问题的回复
question = ['How are you?','你好吗?']
# “我很好 ”
responses = ['Okay',"I'm fine"]
# 随机选一个回
random_response = random.choice(responses)
# 死循环让程序不断接受提问,当输入“再见 ”程序退出
while True:
userInput = input(">>> ")
if userInput in greetings:
print(random_greeting)
elif userInput in question:
print(random_response)
# 当你说“拜拜 ”程序结束
elif userInput == '再见':
break
else:
print("我不知道你在说什么")
输出如下结果:
>>>你好
早上好
>>>你好吗?
我不知道你在说什么?
>>>你好吗?
I’m fine
检索式聊天系统的架构过程通常经过问题解析、规则系统、粗排、精排等几个过程。
最后选择语料库中得分最高的回复。

粗排模型
粗排模型是检索式问答的一种方法,目的是从语料库中快速检索出相似问题。理解粗排模型首先需要了解倒排索引。
倒排索引(Inverted index)常被称为反向索引。倒排索引打乱了语料的正向排序,故称倒排索引。通常来说,以文档id作为索引,以文档内容作为记录;而倒排索引则以文档内容作为索引,以文档id作为记录。

燕山大学对应的记录是0说明第0篇文档中包含燕山大学这个词。

粗排模型:
倒排索引之后,就可以快速的将包含所在词的文档找到,这样就大大提高了搜索速度。包含单字的、包含介词等内容的顺序靠后排。而出现次数少的词,模型认为有可能是关键语句,则需要往前排。
粗排模型实现:按问题句中词的出现次数进行升序排序,取靠前的候选问题句作为粗排结果。
精排模型
在粗排模型中我们按照词的方式进行比较。而精排模型,我们是要比较两个问答句的相似度。不难发现,查询词语序的问题并没有考虑进去,“我请你吃饭 ”和“你请我吃饭 ”在粗排模型中都是一个结果。
并且倒排索引也严重依赖分词,例如上面例子中“燕山 ”、“大学 ”和“燕山大学 ”就是两种不同的分词,结果也是完全不同的。
分词问题主要的解决方式,最近两年的做法是以字为单位输入,以字为输入单位的方式逐渐的超过了以词为单位的效果。而词序的问题,我们可以通过深度学习网络解决。
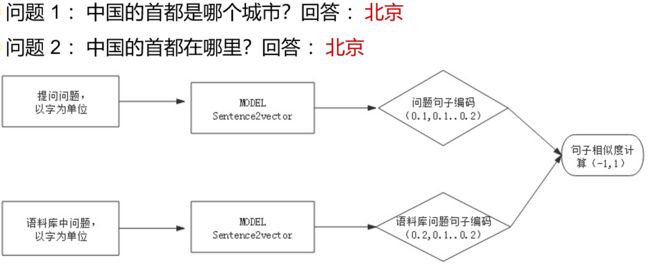
Sentence2Vector 精排模型结构:

以句子为单位输入到LSTM模型中,LSTM模型把句子处理成时序信息,为句子中的每个字都建立关联。将每个字上一时刻的输出作为这一时刻的输入。这样“你请我吃饭 ”和“我请你吃饭 ”由于字的时序不一样,这样就解决了粗排模型中遗留的语序问题和必须分词的问题。
Self-Attention就是在信息处理过程中,对不同的词分配不同的注意力权重。
Dense模块,是将Self-Attention层输出转换成向量,分别将问题句和语料库中的问题句做向量内积,从而得到两句话的相似程度。
Sentence2Vector模型与CBOW模型用多个词预测一个词结构基本类似,只是Sentence2Vector是把词换成了句子,是一个对句子进行向量化,同时可以进行相似度计算的一个模型。