ICCV 2021 | Transformer结合自监督学习!Facebook开源DINO
Emerging Properties in Self-Supervised Vision Transformers
ABSTRACT
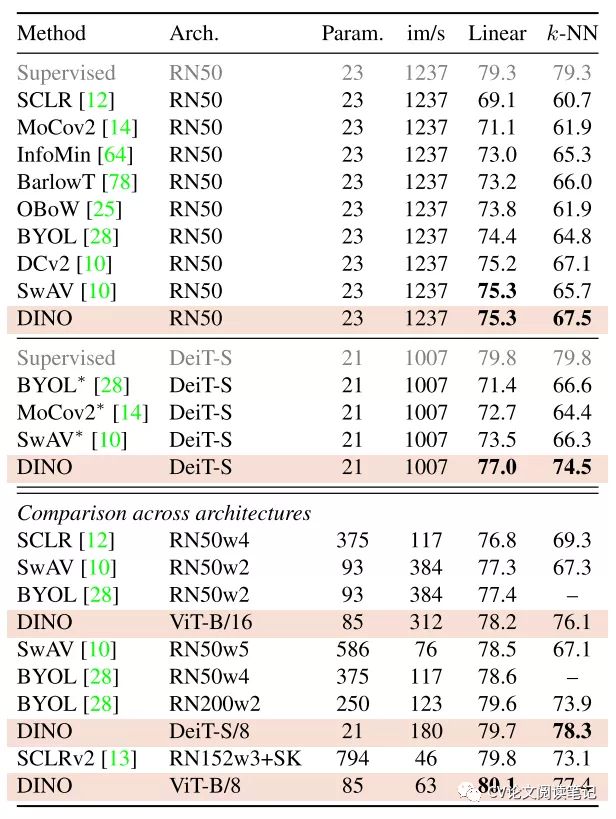
在 本 文 中 , 我 们 质 疑 自 监 督 学 习 是 否 为 Vision Transformer (ViT) 提 供 了 新 的 特 性 。除了使自监督方法适应这种架构 的效果特别好这一事实之外,我们还进行了以下观察:首先, 自监督 ViT 特征包含有关图像语义分割的明确信息,而监督 ViT 则不会如此清晰地出现,也没有convnets。其次,这些 特征也是优秀的 k-NN 分类器,在 ImageNet 上以较小的 ViT 达到 78.3% 的 top-1。我们的研究还强调了动量编码器 的重要性 [33]、多作物训练[10],以及使用带有 ViT 的小 补丁。我们将我们的发现应用到一种简单的自我监督方法中, 称为 DINO,我们将其解释为一种没有标签的自我蒸馏形式。我们通过在使用 ViT-Base 的线性评估中在 ImageNet 上实 现 80.1% 的 top-1 来展示 DINO 和 ViT 之间的协同作用。
1 介绍
transformer [70] 最近出现作为用于视觉识别的卷积神经网络 (convnets) 的替代品 [19, 69, 83]。它们的采用与受自然语言处理 (NLP) 启发的训练策略相结合,即对大量数据进行预训练并对目标数据集进行微调 [18, 55]。由此产生的视觉转换器 (ViT) [19] 与 convnets 竞争,但是,它们还没有带来明显的好处:它们在计算上要求更高,需要更多的训练数据,并且它们的特征没有表现出独特的特性。在本文中,我们质疑变形金刚在视觉方面的成功是否可以通 过 在 预 训 练 中 使 用 监 督 来 解 释 。我 们 的 动 机 是 Transformers 在 NLP 中取得成功的主要因素之一是使用自 我监督的预训练,在 BERT 中以封闭程序的形式[18] 或 GPT 中的语言建模 [55]。这些自我监督的预训练目标使用句子中的词来创建借口任务,这些任务提供比预测每个句子单个标签的监督目标更丰富的学习信号。类似地,在图像中, 图像级监督通常将图像中包含的丰富视觉信息简化为从几千类对象的预定义集合中选择的单个概念.虽然 NLP 中使用的自监督借口任务是特定于文本,许多现有的自监督方法已经在使用 convnets 的图像上显示了它们的潜力 [10, 12, 30, 33]。它们通常共享相似的结构,但具有不同的组件,旨在 避免琐碎的解决方案(崩溃)或提高性能 [16]。在这 项工作中,受这些方法的启发,我们研究了自监督预 训练对 ViT 特征的影响。特别有趣的是,我们已经确 定了几个有趣的属性,这些属性不会出现在有监督的 ViTs 中,也不会出现在 convnets 中:
• 自监督 ViT 特征明确包含场景布局,特别是对象 边界,如图所示1.此信息可在最后一个块的自注 意力模块中直接访问。
• 自监督 ViT 特征在没有任何微调、线性分类器和 数据增强的基本最近邻分类器 (kNN) 上表现特 别好,在 ImageNet 上达到了 78.3% 的 top-1 准确率。分割掩码的出现似乎是自监督方法共享的一个属性。然而,k-NN 的良好性能只有在结合某些组件(例如动 量编码器)时才会出现 [33] 和多作物增强 [10]。我 们研究的另一个发现是使用带有 ViT 的较小补丁来提高 生成特征的质量的重要性。总体而言,我们对这些组件重要性的发现使我们设 计了一种简单的自我监督方法,可以将其解释为一种 知识提炼形式。35] 没有标签。由此产生的框架 DINO 通过使用标准交叉熵损失直接预测教师网络的输出 (使用动量编码器构建)来简化自监督训练。有趣的是,我们的方法只能对教师输出进行居中和锐化以避 免崩溃,而其他流行的组件如预测器 [30]、高级归一 化[10] 或对比损失 [33] 在稳定性或性能方面几乎没 有增加任何好处。特别重要的是,我们的框架非常灵 活,无需修改架构,也无需调整内部规范化,即可在 convnets 和 ViTs 上运行。58]我们进一步验证了 DINO 和 ViT 之间的协同作用, 在 ImageNet 线性分类基准上以 80.1% 的 top-1 准 确率和带有小补丁的 ViTBase 的性能优于之前的自 监督特征。我们还通过将现有技术与 ResNet-50 架构 相匹配来确认 DINO 与 convnets 一起工作。最后, 我们讨论了在计算和内存容量有限的情况下将 DINO 与 ViT 一起使用的不同场景。特别是,使用 ViT 训 练 DINO 只需要两台 8-GPU 服务器超过 3 天,即可 在 ImageNet 线性基准测试中达到 76.1%,即 优于基于卷积神经网络的自监督系统 可比较的大小,但计算要求显着降低 [10, 30].

2. 相关工作
自监督学习
大量关于自监督学习的工作都集中在创造实例分类的判别方法上。12, 20, 33, 73],它将每个图像视为不同的类别,并通过将它们区分为数据增强来训练模型。然而,明确地学习一个分类器来区分所有图像 [20] 不能很好地与图像数量成比例。吴等人。[73] 建议使用噪声对比估计器 (NCE) [32] 来比较实例而不是对它们进行分类。这种方法的一个警告是它需要同时比较大量图像的特征。在实践中,这需要大批量 [12] 或存储库 [33, 73]。几个变体允许以聚类的形式自动分组实例 [2, 8, 9, 36, 42, 74, 80, 85].最近的工作表明,我们可以在不区分图像的情况下学习无监督特征。特别感兴趣的是,Grill 等人[30] 提出了一种称为 BYOL 的度量学习公式,其中通过将特征与使用动量编码器获得的表示相匹配来训练特征。像 BYOL 这样的方法即使没有动量编码器也能工作,但代价是性能下降 [16, 30]。其他几部作品回应了这一方向,表明可以匹配更精细的表示[26, 27],训练特征匹配到均匀分布[6] 或通过使用美白 [23, 81]。我们的方法从 BYOL 中汲取灵感,但使用不同的相似性匹配损失。并为学生和教师使用完全相同的架构。这样,我们的 工作完成了 BYOL 中对自我监督学习的解释,作为一 种平均教师自我蒸馏的形式[65] 没有标签。
自我训练和知识蒸馏。自训练旨在通过将一小部分初 始注释传播到一大组未标记实例来提高特征质量。这 种传播可以通过标签的硬分配来完成 [41, 78, 79] 或 使用软分配 [76]。使用软标签时,该方法通常称为知 识蒸馏 [7, 35] 并且主要设计用于训练一个小型网络 来模仿更大网络的输出来压缩模型。谢等人。[76] 已经表明蒸馏可用于在自训练中将软伪标签传播到未 标记的数据 管道,在自我之间建立了重要的联系 培训和知识蒸馏。我们的工作建立在 这种关系并将知识蒸馏扩展到没有标签可用的情况。之前的工作也结合了自监督学习和知识蒸馏[25, 63, 13, 47],实现自我监督的模型压缩和性能提升。然而,这 些作品依赖于预先训练好的固定教师,而我们的教师 是在训练期间动态建立的。这样,知识蒸馏,而不是 用作自监督预训练的后处理步骤,而是直接作为自监 督目标。最后,我们的工作也与共蒸馏有关 [1] 其中 学生和教师具有相同的架构并在训练期间使用蒸馏。但是, codistillation 中的老师也在从学生中提取,同时更新 我们工作中学生的平均值。
3. 方法
3.1. SSL与知识蒸馏
用于这项工作的框架 DINO 与最近的自我监督方法具 有相同的整体结构[10, 16, 12, 30, 33]。然而,我们的方法也有相似之处解决。所有作物都通过学生传递,而只有全局视图通 过教师传递,因此鼓励“本地到全局”的对应关系。我 们最小化损失:用知识蒸馏 [35],我们在这个角度下呈现它。我们在 图中说明了 DINO2 并提出一个 分钟是 x∈{x g ,x g } x t∈VH(Pt(x), Ps(x)). (3) 1 2 算法中的伪代码实现1. x x
知识蒸馏是一种学习范式,我们训练学生网络 g是以 匹配给定教师网络 g它的输出,分别由 θs和 θt参数 化。给定输入图像 x,两个网络都输出 K 维的概率分 布,用 Ps和 Pt表示。概率 P 是通过使用 softmax 函 数对网络 g 的输出进行归一化得到的。更确切地说,

输出分布的锐度,类似的公式适用于温度 τt的 Pt。给 定一个固定的教师网络 g它,我们通过最小化交叉熵损 失 w.r.t. 来学习匹配这些分布。学生网络θs的参数:
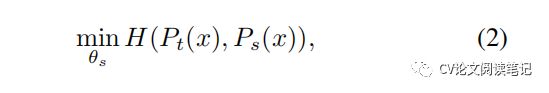
在下文中,我们将详细介绍我们如何调整方程中的 问题。(2) 进行自我监督学习。首先,我们使用多重 裁剪策略构建图像的不同扭曲视图或裁剪[10]。更准 确地说,从给定的图像中,我们生成一组不同视图的 V。此套装包含两个 全局视图,xg和 xg以及一些较小的局部视图

这种损失是通用的,可以用于任意数量的视图, 甚至只有 2 个。但是,我们遵循多裁剪的标准设置, 使用 2 个分辨率为 2242的全局视图覆盖一个大的 (例如大于 50% ) 原始图像的区域,以及几个分辨 率为 962的局部视图,仅覆盖原始图像的小区域 例如小于 50%)。除非另有说明,否则我们将此 设置称为 DINO 的基本参数化。
Avoiding collapse
DINO通过一个centering和momentum teacher输出的sharpening来避免退化解。
用这种方法来避免退化解,可以减少对batch的依赖来增加稳定性:centering在一阶batch统计量中可以解释为给teacher增加一个bias项c: ,并且这个c通过指数滑动平均来更新,公式为:


如左图所示,centering鼓励输出均匀分布,而sharpening鼓励输出的一个维度占主导地位。
KL散度为0表示出现退化解。当单独使用centering和sharpening时,DINO无法正常训练;当同时使用centering和sharpening时,随着训练epoch增加,KL散度先增大后减小,避免出现退化解。

总结
在这项工作中,我们展示了自监督预训练标准 ViT 模型 的潜力,其性能可与专门为此设置设计的最佳卷积网络相媲 美。我们还看到了两个可以在未来应用中利用的特性:k-NN 分类中特征的质量具有用于图像检索的潜力,其中 ViT 已 经显示出有希望的结果[22]。特征中关于场景布局的信息的 存在也有利于弱监督图像分割。然而,本文的主要结果是我 们有证据表明自监督学习可能是开发基于 BERT 的模型的关 键