知识图谱框架DeepKE简单使用+关系抽取+小小bug修复
一、关系抽取
知识图谱里面主要涉及两个很重要的领域:实体识别、关系抽取。当然,一般来说实体识别是关系抽取的前提条件,实体识别是序列标注的一种,通过将语句中的各种词的词性进行标注作为标签放入模型中训练,便可进行识别。当一段话能被识别出具体的实体信息后,我们便可以做关系抽取,关系抽取逻辑也比较简单,最简单是是三元组POI,
也即(吴京,战狼,主演)。其中实体head为吴京,实体tail为战狼,关系为主演,那么词性呢?吴京词性是人名,战狼词性是电影名或影视剧名。
如何实现的关系抽取,一般训练的数据是带有标签的,比如数据:
周星驰导演了《大话西游》,这是很棒的一部电影。 -- label = "导演"
《战狼2》是一部很成功的爱国主义情怀电影,主演是吴京。--label="主演"
导弹之父钱学森毕业于上海交通大学。--label="毕业院校"
于是我们先进行实体抽取,每段话里面会抽取到很多不同的实体,然后再进行训练识别标签,那么我得到标签之后,也就是三元组的relation,我们还需要两个对应的实体,也就是,比如关系“毕业院校”对应的两个实体应该是人名和学校名,于是我们进行实体识别,发现钱学森是人名,上海交通大学是学校名,于是得到了抽取的结果为:
(钱学森,上海交通大学,毕业院校)的三元组关系,从而实现了比较简单的关系抽取。
那么这就需要我们人为提前的告知,这个关系表是啥样的,所以关系抽取部分,会需要一个额外的文件信息,关系表relation.csv。如DeepKE框架中给出的关系表内容如下所示。

index为索引,模型训练用的,比如这里对应了11个关系,第0个None指的是如果文本中出现了关系表中没有的关系,就输出为None。如果模型训练输出的数值为第3个概率最大,多分类用softmax,于是对应的关系应该是:人物,地点,祖籍,3。然年去这个文本中找到人物和地点的实体。
当然可能有人提问,如果一个文本中出现多个相同的实体呢?那咋办。
比如样例:
周星驰指导电影《功夫》的拍摄时,请教了很多武打明星如洪金宝进行武术指导。关系relation为导演。
那么导演对应的实体为:head:人名,tail:影视作品。
上面的文本中出现多个人名的实体:周星驰、洪金宝。
那么现在又怎么识别周星驰才是我们需要的那个人名的实体呢?
于是又提出了空间关系的方法,也就是进行位置标记。为了更精确进行识别,我们对出现的位置进行标记:
于是标签就是:周星驰,0,功夫,7,导演。
这样把很多数据进行位置标记后,再通过模型去训练识别这种空间上的位置关系,那么当出现多个实体后,模型就能很高效的识别出哪对实体对才是正确的,比如上面的文本中出现两个实体对:
(周星驰、功夫)—>(0,7)
(洪金宝,功夫)—>(26,7)
反复训练位置关系后,会认为(0,7)的关系对更接近模型要求,于是选择了周星驰和功夫,这样做后效果精确率大大提高了不少。
这就是关系抽取的简单介绍了。
二、DeepKE
2.1 框架介绍
DeepKE是我们课程老师和他的课题组联合开源到github的一个知识图谱操作框架,主要功能就是实体识别和关系抽取,这次使用这个框架就是老师的期末课程大作业要求,,,,,。不过框架还是设计的很棒的,包含了cnn, rnn, transformer, capsule, gcn, lm这些框架,相当于集成了很多基本的模型,可以任意调用。
但是有一个小小的bug,一开始我下载框架按样例运行,读取框架给的样例数据,没问题,可以正常运行,但是我换成了自己找的其他数据集,读取就报错了,说是一些列名不存在,我就很奇怪了,明明是有的。这个框架当时按流程是直接把deepke安装到了python里面,当然你也可以直接下载deepke的源代码读取。因为读取报错,然后读取文件是deepke里面的,所以我只好卸载了安装在python里面的deepke,直接网上下载了源代码使用。
然后找到报错的那部分代码,才发现了原因,然后修复了下bug提交到了DeepKE,今天刚提交的,可能DeepKE的维护的人员还没来得及审核提交修复申请,不过下面我会说一下原因,问题不大。
请先下载DeepKE源代码。https://github.com/zjunlp/DeepKE
文件截屏如下:
我们使用关系抽取的话,按照官网的readme.md说明就行,就是直接找到这个目录下:/DeepKE-main/example/re/standard。
内容如下:
然后按照人家的要求配置python模块如下:
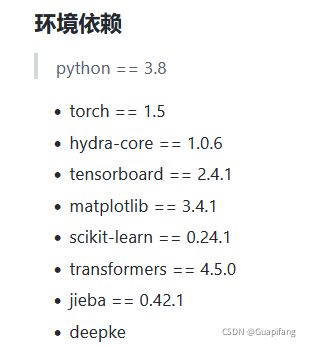
这里我为啥单独说一下环境呢?我当时是在服务器上跑的,服务器的话是Linux系统,然后我同学做这个作业的时候,直接windows上安装的模块,一直报错torch1.5找不到,后来仔细思考回忆到python的很多模块的开发都是基于Linux或Ubuntu,很多模块windows版本是没有的,然后他用电脑开启了一个Linux的虚拟机,然后直接安装成功了!!!这里也提个醒,建议很多同学可以这样试试,跑代码在windows环境确实不太友好,不是这样错就是那样错。。。。
安装成功后,看吧,最后就是让你安装deepke到python内部,当然你也可以直接下载源代码。安装成功后,直接python run.py运行即可。
刚才看了下,工作人员还没审核更新修复读取bug,所以建议可以先直接文件读取试试,直接卸载deepke模块,下载deepke的文件。
其实就是在主页的src文件夹下就是deepke的代码文件,请单独把这个文件夹复制到/DeepKE-main/example/re/standard目录下。
如下:
因为我们从python中卸载了deepke,run.py里面是直接加载的,所以需要把deepke源代码和run.py同一目录下。
2.2 bug修复
现在解释下错误在哪里。
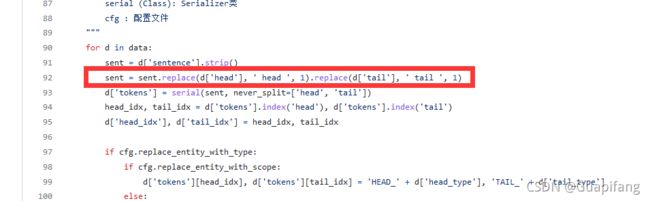
找到deepke里面关于关系抽取的读取代码部分,/deepke/relation_extraction/standard/tools/preprocess.py,错误的部分如下:
 我们先看一下样例中提供的样例数据,格式如下。
我们先看一下样例中提供的样例数据,格式如下。
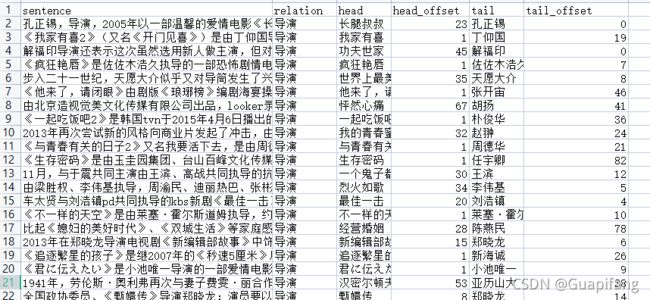
head和tail为实体,head_offset为出现的位置。
在preprocess.py文件中,加载数据格式是把文本setence中对应的head和tail的词都替换成head和tail,比如:
孔正锡,导演,2005年以一部温馨的爱情电影《长腿叔叔》敲开电影界大门
head=长腿叔叔
tail=孔正锡
head -> 导演 -> tail
替换后为:
tail,导演,2005年以一部温馨的爱情电影《head》敲开电影界大门
替换的目的在于后面模型加载训练数据比较方便,也是为了在文本中标出哪些实体是我们的目标。
好的,我们再回去看看preprocess.py读取文件的源码
sent = d['sentence'].strip()
sent = sent.replace(d['head'], ' head ', 1).replace(d['tail'], ' tail ', 1)
这行代码的作用是啥呢?
d是一个字典,d[‘head’]代表的就是具体内容,比如d[‘head’]为长腿叔叔,d[‘tail’]为孔正锡,sent.replace(d[‘head’], ’ head ', 1)的作用就是替换文本’sentence’中第一个出现的字符串’长腿叔叔‘,然后结果为:孔正锡,导演,2005年以一部温馨的爱情电影《head》敲开电影界大门。然后后面的.replace(d[‘tail’], ’ tail ‘, 1)就是在这个基础上继续替换’孔正锡’。最后得到我们的:tail,导演,2005年以一部温馨的爱情电影《head》敲开电影界大门。
好的,现在仔细想想这个逻辑有没有啥问题呢???
有!那就是两个实体包含的情况,就会出错,我找的数据集内容比较多,就出现这样的错误,例如:
中国共产党领导了曾经落后的中国走向了繁荣富强。三元组为(中国,中国共产党,领导)。
head=中国、tail=中国共产党、relation=领导。
那么此时再按照上面的语句,操作如下:
sent.replace(d[‘head’], ’ head ', 1) -> head共产党领导了曾经落后的中国走向了繁荣富强。
然后再继续sent.replace(d[‘tail’], ’ tail ', 1),但是此时的中国共产党这个内容就没有了,于是就报错了!!!!!!
那么怎么修改了,如果语句信息很复杂就另说了,所以我就简单了写了个粗暴的判断方式:
if d['head'] in sent.replace(d['tail'], ' tail ', 1):
sent = sent.replace(d['tail'], ' tail ', 1).replace(d['head'], ' head ', 1)
else:
sent = sent.replace(d['head'], ' head ', 1).replace(d['tail'], ' tail ', 1)
这样就可以了。
但是还有些问题,就是有些数据里面本身就不包含实体的名词,就是所谓的脏数据,所以我又额外添加了个数据清洗函数,把不符合要求的数据打印显示了下。
def clean_data(data):#数据清洗,去除不符合要求的脏乱数据
true_data = []
false_data = []
for d in data:
if is_true_setence(d['sentence'].strip(),d['head'],d['tail']):
true_data.append(d)
else:
false_data.append(d)
logger.info('These data do not meet the requirements....')
for d in false_data:
logger.info(d)
return true_data
完整修复后的preprocess.py文件内容如下:
import os
import logging
from collections import OrderedDict
import re
from typing import List, Dict
from transformers import BertTokenizer
from .serializer import Serializer
from .vocab import Vocab
import sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../")))
from utils import save_pkl, load_csv
from tqdm import tqdm
logger = logging.getLogger(__name__)
__all__ = [
"_handle_pos_limit",
"_add_pos_seq",
"_convert_tokens_into_index",
"_serialize_sentence",
"_lm_serialize",
"_add_relation_data",
"_handle_relation_data",
"preprocess"
]
def _handle_pos_limit(pos: List[int], limit: int) -> List[int]:
"""
处理句子长度,设定句长限制
Args :
pos (List[int]) : 句子对应的List
limit (int) : 限制的数
Return :
[p + limit + 1 for p in pos] (List[int]) : 处理后的结果
"""
for i, p in enumerate(pos):
if p > limit:
pos[i] = limit
if p < -limit:
pos[i] = -limit
return [p + limit + 1 for p in pos]
def _add_pos_seq(train_data: List[Dict], cfg):
"""
增加位置序列
Args :
train_data (List[Dict]) : 数据集合
cfg : 配置文件
"""
for d in tqdm(train_data):
entities_idx = [d['head_idx'], d['tail_idx']
] if d['head_idx'] < d['tail_idx'] else [d['tail_idx'], d['head_idx']]
d['head_pos'] = list(map(lambda i: i - d['head_idx'], list(range(d['seq_len']))))
d['head_pos'] = _handle_pos_limit(d['head_pos'], int(cfg.pos_limit))
d['tail_pos'] = list(map(lambda i: i - d['tail_idx'], list(range(d['seq_len']))))
d['tail_pos'] = _handle_pos_limit(d['tail_pos'], int(cfg.pos_limit))
if cfg.model_name == 'cnn':
if cfg.use_pcnn:
# 当句子无法分隔成三段时,无法使用PCNN
# 比如: [head, ... tail] or [... head, tail, ...] 无法使用统一方式 mask 分段
d['entities_pos'] = [1] * (entities_idx[0] + 1) + [2] * (entities_idx[1] - entities_idx[0] - 1) +\
[3] * (d['seq_len'] - entities_idx[1])
def _convert_tokens_into_index(data: List[Dict], vocab):
"""
将tokens转换成index值
Args :
data (List[Dict]) : 数据集合
vocab (Class) : 词汇表
"""
unk_str = '[UNK]'
unk_idx = vocab.word2idx[unk_str]
for d in data:
d['token2idx'] = [vocab.word2idx.get(i, unk_idx) for i in d['tokens']]
d['seq_len'] = len(d['token2idx'])
def _serialize_sentence(data: List[Dict], serial, cfg):
"""
将句子分词
Args :
data (List[Dict]) : 数据集合
serial (Class): Serializer类
cfg : 配置文件
"""
ans = 0
for d in tqdm(data):
sent = d['sentence'].strip()
if d['head'] in sent.replace(d['tail'], ' tail ', 1):
sent = sent.replace(d['tail'], ' tail ', 1).replace(d['head'], ' head ', 1)
else:
sent = sent.replace(d['head'], ' head ', 1).replace(d['tail'], ' tail ', 1)
d['tokens'] = serial(sent, never_split=['head', 'tail'])
head_idx, tail_idx = d['tokens'].index('head'), d['tokens'].index('tail')
d['head_idx'], d['tail_idx'] = head_idx, tail_idx
if cfg.replace_entity_with_type:
if cfg.replace_entity_with_scope:
d['tokens'][head_idx], d['tokens'][tail_idx] = 'HEAD_' + d['head_type'], 'TAIL_' + d['tail_type']
else:
d['tokens'][head_idx], d['tokens'][tail_idx] = d['head_type'], d['tail_type']
else:
if cfg.replace_entity_with_scope:
d['tokens'][head_idx], d['tokens'][tail_idx] = 'HEAD', 'TAIL'
else:
d['tokens'][head_idx], d['tokens'][tail_idx] = d['head'], d['tail']
def _lm_serialize(data: List[Dict], cfg):
"""
lm模型分词
Args :
data (List[Dict]) : 数据集合
cfg : 配置文件
"""
logger.info('use bert tokenizer...')
tokenizer = BertTokenizer.from_pretrained(cfg.lm_file)
for d in data:
sent = d['sentence'].strip()
sent = sent.replace(d['head'], d['head_type'], 1).replace(d['tail'], d['tail_type'], 1)
sent += '[SEP]' + d['head'] + '[SEP]' + d['tail']
d['token2idx'] = tokenizer.encode(sent, add_special_tokens=True)
d['seq_len'] = len(d['token2idx'])
def _add_relation_data(rels: Dict, data: List) -> None:
"""
增加关系数据
Args :
rels (Dict) : 关系字典集合
data (List) : 所需增加的关系数据
"""
for d in data:
d['rel2idx'] = rels[d['relation']]['index']
d['head_type'] = rels[d['relation']]['head_type']
d['tail_type'] = rels[d['relation']]['tail_type']
def _handle_relation_data(relation_data: List[Dict]) -> Dict:
"""
处理关系数据,每一个关系有index,head_type,tail_type三个属性
Arg :
relation_data (List[Dict]) : 所需要处理的关系数据
Return :
rels (Dict) : 处理之后的结果
"""
rels = OrderedDict()
relation_data = sorted(relation_data, key=lambda i: int(i['index']))
for d in relation_data:
rels[d['relation']] = {
'index': int(d['index']),
'head_type': d['head_type'],
'tail_type': d['tail_type'],
}
return rels
def is_true_setence(setence,head,tail):#判断句子是否符合三元组表示要求
if head not in setence.replace(tail,'',1) and tail not in setence.replace(head,'',1):
return False#舍去
if head not in setence or tail not in setence:
return False
return True
def clean_data(data):#数据清洗,去除不符合要求的脏乱数据
true_data = []
false_data = []
for d in data:
if is_true_setence(d['sentence'].strip(),d['head'],d['tail']):
true_data.append(d)
else:
false_data.append(d)
logger.info('These data do not meet the requirements....')
for d in false_data:
logger.info(d)
return true_data
def preprocess(cfg):
"""
数据预处理阶段
"""
logger.info('===== start preprocess data =====')
train_fp = os.path.join(cfg.cwd, cfg.data_path, 'train.csv')
valid_fp = os.path.join(cfg.cwd, cfg.data_path, 'valid.csv')
test_fp = os.path.join(cfg.cwd, cfg.data_path, 'test.csv')
relation_fp = os.path.join(cfg.cwd, cfg.data_path, 'relation.csv')
logger.info('load raw files...')
train_data = load_csv(train_fp)
valid_data = load_csv(valid_fp)
test_data = load_csv(test_fp)
relation_data = load_csv(relation_fp)
logger.info('clean data...')
train_data = clean_data(train_data)
valid_data = clean_data(valid_data)
test_data = clean_data(test_data)
logger.info('convert relation into index...')
rels = _handle_relation_data(relation_data)
_add_relation_data(rels, train_data)
_add_relation_data(rels, valid_data)
_add_relation_data(rels, test_data)
logger.info('verify whether use pretrained language models...')
if cfg.model_name == 'lm':
logger.info('use pretrained language models serialize sentence...')
_lm_serialize(train_data, cfg)
_lm_serialize(valid_data, cfg)
_lm_serialize(test_data, cfg)
else:
logger.info('serialize sentence into tokens...')
print('cfg.chinese_split = ',cfg.chinese_split)
serializer = Serializer(do_chinese_split=cfg.chinese_split, do_lower_case=True)
serial = serializer.serialize
_serialize_sentence(train_data, serial, cfg)
_serialize_sentence(valid_data, serial, cfg)
_serialize_sentence(test_data, serial, cfg)
logger.info('build vocabulary...')
vocab = Vocab('word')
train_tokens = [d['tokens'] for d in train_data]
valid_tokens = [d['tokens'] for d in valid_data]
test_tokens = [d['tokens'] for d in test_data]
sent_tokens = [*train_tokens, *valid_tokens, *test_tokens]
for sent in sent_tokens:
vocab.add_words(sent)
vocab.trim(min_freq=cfg.min_freq)
logger.info('convert tokens into index...')
_convert_tokens_into_index(train_data, vocab)
_convert_tokens_into_index(valid_data, vocab)
_convert_tokens_into_index(test_data, vocab)
logger.info('build position sequence...')
_add_pos_seq(train_data, cfg)
_add_pos_seq(valid_data, cfg)
_add_pos_seq(test_data, cfg)
logger.info('save data for backup...')
os.makedirs(os.path.join(cfg.cwd, cfg.out_path), exist_ok=True)
train_save_fp = os.path.join(cfg.cwd, cfg.out_path, 'train.pkl')
valid_save_fp = os.path.join(cfg.cwd, cfg.out_path, 'valid.pkl')
test_save_fp = os.path.join(cfg.cwd, cfg.out_path, 'test.pkl')
save_pkl(train_data, train_save_fp)
save_pkl(valid_data, valid_save_fp)
save_pkl(test_data, test_save_fp)
if cfg.model_name != 'lm':
vocab_save_fp = os.path.join(cfg.cwd, cfg.out_path, 'vocab.pkl')
vocab_txt = os.path.join(cfg.cwd, cfg.out_path, 'vocab.txt')
save_pkl(vocab, vocab_save_fp)
logger.info('save vocab in txt file, for watching...')
with open(vocab_txt, 'w', encoding='utf-8') as f:
f.write(os.linesep.join(vocab.word2idx.keys()))
logger.info('===== end preprocess data =====')
然后现在就可以正常的读取数据了。
2.3 读取的数据格式
虽然样例文件的数据格式是这样的:
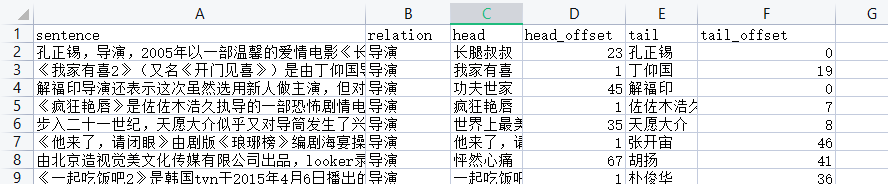
但其实只需要sentence、relation、head、tail就行。head_offset和tail_offset读取数据的文件里面会自动计算。
数据读取好后放在这个文件夹下:DeepKE/example/re/standard/data/origin/
这是读取的原始数据文件夹,原来的样例文件如下。
4个文件,关系表relation.csv、测试文件、验证集文件,训练集文件。
自己把自己带有标签的数据集划分成测试集、验证集、训练集即可。
2.4 模型的参数
请注意下,因为读入新的数据集,关系的数目变了,需要修改模型输出的节点个数。
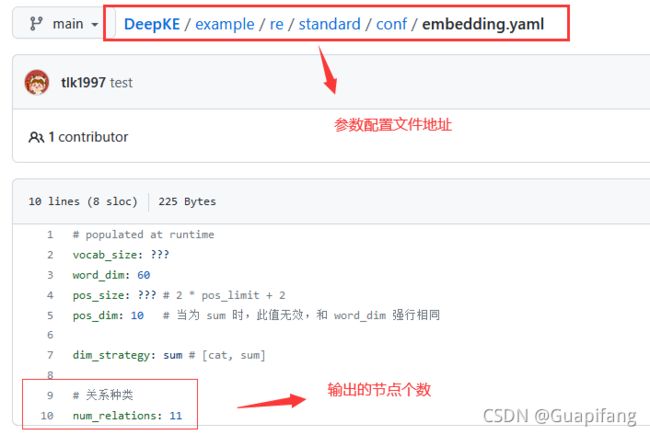 如果你导入的新的数据集有48个节点,就把num_relations修改成48。
如果你导入的新的数据集有48个节点,就把num_relations修改成48。
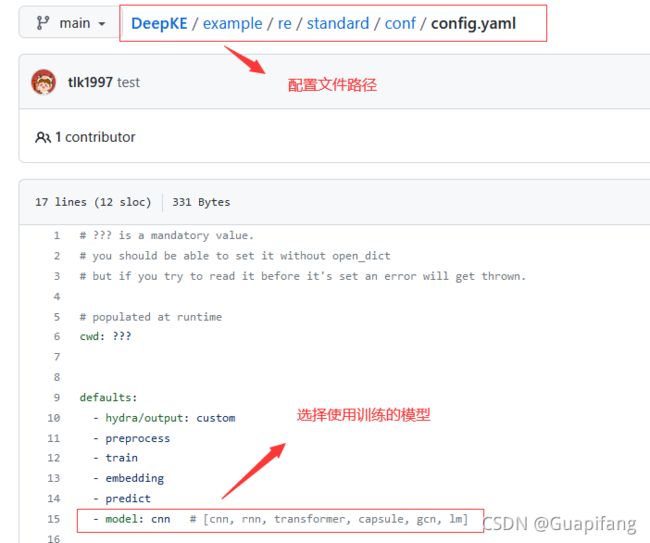
三、训练
配置好后,运行run.py开始训练,结果如下
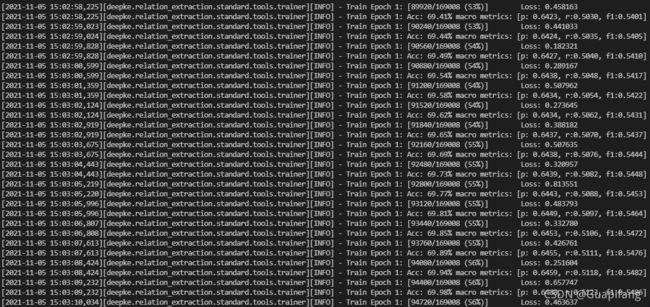
上面这个是调用GCN训练的,其他同学可以调用其他模型训练看看。