【论文阅读|ICLR2020】Strategies for Pre-training Graph Neural Networks
代码地址: https://github.com/snap-stanford/pretrain-gnns/
论文地址:https://arxiv.org/abs/1905.12265v2
0 摘要
机器学习的许多应用需要一个模型来对分布上与训练样本不同的测试样本做出准确的预测,而在训练过程中特定任务的标签很少。应对这一挑战的一种有效方法是在数据丰富的相关任务上预训练模型,然后在感兴趣的下游任务上对其进行微调。虽然预训练在许多语言和视觉领域都很有效,但如何有效地在图数据集上使用预训练仍然是一个悬而未决的问题。
本文:
提出了一种新的策略和自监督方法来预训练图神经网络 (GNN)
在单个节点和整个图的级别上预训练一个有表现力的 GNN,以便 GNN 可以同时学习有用的局部和全局表示
在整个图或单个节点级别预训练 GNN 的策略只能提供有限的改进,甚至可能导致许多下游任务的负迁移。我们的策略避免了负迁移并显着提高了下游任务的泛化能力,与非预训练模型相比,ROC-AUC 的绝对改进高达 9.4%,并实现了分子特性预测和蛋白质的最先进性能功能预测。
1 介绍
预训练有可能为以下两个在图数据集上学习的基本挑战提供有吸引力的解决方案:
- 特定任务的标记数据可能极其稀缺
- 来自实际应用的图数据通常包含分布外样本,这意味着训练集中的图在结构上与测试集中的图非常不同。
本文:
- 我们对GNN的预训练策略进行了第一次系统的大规模调查
- 我们为GNN开发了一种有效的预训练策略,并证明了它的有效性及其在困难的迁移学习问题上的分布外泛化能力。关键思想是使用易于访问的节点级信息,并鼓励 GNN 捕获有关节点和边的特定领域知识,以及图级知识
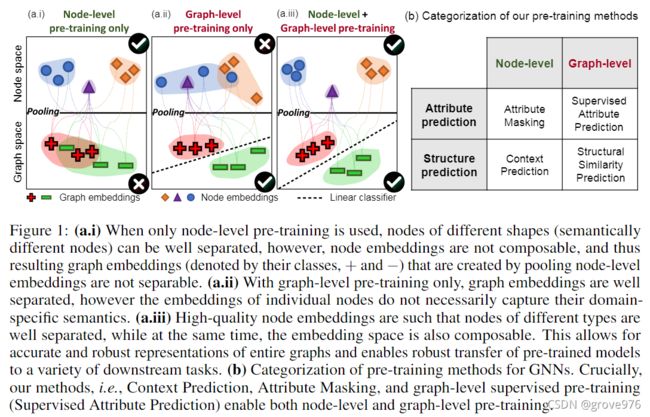
这有助于 GNN 在全局和局部级别学习有用的表示(图 1 (a.iii)),并且对于能够生成稳健且可转移到不同下游的图级表示是至关重要任务(图 1)。我们的策略与那些只利用图层属性(图1(a.ii))或节点层属性(图1(a.i))的策略截然不同
3 图神经网络预训练的策略
我们的预训练策略的技术核心是在单个节点和整个图的层面上预训练一个GNN的概念。这个概念鼓励 GNN 在两个级别捕获特定领域的语义,如图 1 (a.iii) 所示。这与直接但有限的预训练策略形成对比,预训练策略要么仅使用预训练来预测整个图的属性(图 1 (a.ii)),要么仅使用预训练来预测单个节点的属性(图 1 (ai) )).
3.1 节点级别预训练
对于GNN的节点级预训练,我们的方法是使用容易获得的无标签数据来捕捉图中的特定领域知识/规则。这里我们提出了两种自我监督的方法,上下文预测和属性mask。
3.1.1 上下文预测:利用图结构的分布
在上下文预测中,我们使用子图来预测其周围的图结构。我们的目标是预训练 GNN,以便将出现在相似结构上下文中的节点映射到附近的嵌入。
Neighborhood and context graphs
我们将节点的context graph定义为围绕着 v v v的邻域的图结构。由两个超参 r 1 r_1 r1和 r 2 r_2 r2描述,表示距离 v v v在 r 1 r_1 r1跳到 r 2 r_2 r2跳之间的子图
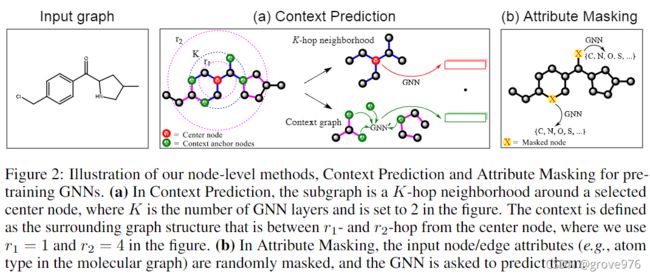
将邻居节点和context graph中节点公共的节点称为context anchor nodes(上下文锚节点),这些锚节点提供了关于邻居系欸但那和context graph之间的关系
Encoding context into a fixed vector using an auxiliary GNN
为了能够进行上下文预测,为context graph编码为固定长度的向量。为此,我们使用了一个辅助GNN,我们将其称为context GNN。对上下文锚节点的嵌入进行取均值,得到固定长度的上下文嵌入。将图 G G G中节点 v v v的上下文嵌入表示为 c v G c_v^G cvG。
Learning via negative sampling
上下文预测的学习目标是对特定领域和特定context grapg是否属于一个节点进行二分类:
σ ( h v ( K ) T c v ′ G ′ ) ≈ 1 { v a n d v ′ a r e t h e s a m e n o d e s } \sigma(h_v^{(K)T} c_{v'}^{G'}) \approx 1 \{ v \ and \ v' \ are \ the \ same \ nodes \} σ(hv(K)Tcv′G′)≈1{v and v′ are the same nodes}
正样本: v ′ = v , G ′ = G v' = v, \ G' = G v′=v, G′=G
负样本:随机选择节点 v ′ v' v′和随机选择图 G ′ G' G′
我们使用1的负采样率(每一个正对一个负对),并使用负对数似然作为损失函数。 预训练后,保留主GNN作为我们的预训练模型
3.1.2 属性掩蔽:利用图的属性分布
在属性掩蔽中,我们旨在通过学习分布在图结构上的节点/边缘属性的规律性来获取领域知识。
Masking node and edges attributes
我们掩蔽节点/边属性,然后让GNN根据邻接结构预测这些属性。具体来说,我们随机掩蔽输入节点/边的属性,例如分子图中的原子类型,用特殊的掩蔽指标来代替它们。然后,我们应用GNNs来获得相应的节点/边嵌入(边嵌入可以将边连接的两个节点的嵌入之和来获得)。最后,在嵌入的基础上应用一个线性模型来预测一个被屏蔽的节点/边缘属性
与Devlin等人(2019)在句子上操作并在标记的全连接图上应用消息传递不同,我们在非全连接图上操作,旨在捕捉分布在不同图结构上的节点/边缘属性的规律性。
此外,我们允许屏蔽边缘属性,超越了屏蔽节点属性的范围。
3.2 图级别预训练
我们的目标是预训练GNN以生成有用的图嵌入,这些图嵌入前面获得的有意义的节点嵌入组成。我们的目标是确保节点和图嵌入都是高质量的,这样图的嵌入才是稳健的,并且可以跨下游任务转移。图级别预训练有两种选择:对整个图的特定领域属性进行预测,对图结构进行预测
3.2.1 有监督的图级别属性预测
由于图级别表示 h G h_G hG直接用于下游预测任务的微调,因此最好能将特定领域的信息直接编码到 h G h_G hG中。
我们通过定义有监督的图级别预测任务,将图级别特定领域的知识注入到我们的预训练嵌入中。我们考虑了一种预训练图表示的实用方法:图级多任务监督预训练,以共同预测单个图的不同监督标签集。为了联合预测许多图属性,其中每个属性对应一个二元分类任务,我们在图表示之上应用线性分类器。
本文预训练的策略是:首先进行节点级别的预训练,然后再进行图级别的预训练。这种方法可以生产更具有可迁移能力的图表示,并且有鲁棒性,可以提高下游任务的性能,不需要专家人为选择有监督的预训练任务。
3.2.2 相似性结构预测
目标是对两个图的结构相似性进行建模。这类任务的建模包括对图的编辑距离进行建模或预测图的结构相似性。然而,找到真实图距离值是一个难题,在大型数据集中,需要考虑平方数的图对。因此,虽然这种类型的预训练也很自然,但它超出了本文的范围,我们将其研究留待以后工作。
3.3 概述:预训练GNN和针对下游任务的微调
总而言之,我们的预训练策略是首先执行节点级自监督预训练,然后是图级多任务监督预训练。在预训练结束后,我们在下游任务对预训练的GNN模型进行微调。我们在图级别表示上添加线性分类器来预测下游的图标签。我们的预训练方法在 GNN 中进行前向计算时产生的计算开销很小。
预训练的时间复杂度
在这里,我们分析了属性屏蔽和上下文预测中处理图的时间复杂性。首先,属性屏蔽的时间复杂度与边/节点的数量呈线性关系,因为它只涉及要屏蔽的节点/边的抽样。其次,上下文预测的时间复杂度对于边/节点的数量也是线性的,因为它涉及对每个图的中心节点进行采样以及提取 K 跳邻域和上下文图。邻域/上下文图的提取由广度优先搜索执行,该搜索最多需要与图中边数相关的线性时间。总之,我们的两种预训练方法的时间复杂度最多与边数呈线性关系,这与 GNN 中的消息传递计算一样有效,因此与使用 GNN 的普通监督学习一样有效。此外,当我们即时转换数据(例如,屏蔽输入节点/边缘特征,对上下文图进行采样)时,几乎没有内存开销。
4 进一步相关工作
关于图内单个节点的无监督表示学习有丰富的文献,大致分为两类。
- 使用基于局部随机游走的目标的方法和重建图的邻接矩阵的方法
- 训练一个节点编码器,使局部节点表示和池化全局图表示之间的互信息最大化
所有这些方法都鼓励附近的节点具有相似的嵌入,最初是为了节点分类和链接预测而提出和评估的。然而,这对于图级预测任务来说可能是次优的,其中捕获局部邻域的结构相似性通常比捕获图中节点的位置信息更重要。
最近的一些工作也探讨了节点嵌入如何跨任务泛化。然而,所有这些方法对不同的子结构使用不同的节点嵌入,并且不共享任何参数。因此,他们本质上是transductive的,不能在数据集之间转移,不能以端到端的方式微调,并且由于数据稀疏而不能捕获大而多样的领域/上下文。
本文的方法通过为GNN的预训练方法来解决所有这些挑战,这些方法使用共享参数来编码图级别以及节点级别的依赖关系和结构。
5 实验
5.1 数据集
数据集预训练
两个领域数据集:
- 化学中的分子特性预测
- 从ZINC15数据库中采样的200万个未标记分子进行节点级别自监督预训练
- 图级别多任务监督预训练采用ChEMBL数据集,包含456K分子和1310中不同的、广泛的生物化学检测
- 生物学中的蛋白质功能预测
- 使用从PPI网络中获得的395K个未标注的蛋白质ego-networks进行节点级别的自监督的预训练。
- 使用88K个标注的蛋白质ego-netowrks进行图级别的多任务的有监督预训练,预测5000个coarse-grained biological functions。