图文结合-ViLT
本文介绍一篇图文结合的论文ViLT,论文发布于2021年

论文题目:
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
论文地址:
https://arxiv.org/abs/2102.03334
代码地址:
https://github.com/dandelin/vilt
ViLT以一种统一的方式处理两种模态的信息。其优势在于:
- 使用transformer处理视觉特征,丢弃了原始的单独处理视觉特征的模块,显著优化了运行时间
- 在预训练过程中使用了whole word masking和图像增强技术,进一步提高了下游任务的表现
- 单流模型,使用基于多层transformer结构的交互层,实现不同模态的深层交互
作者认为,早先的图文结合工作,将重心放在图片特征提取与编码上,而且对于文本与图像之间的交互都停留在浅层。这样,也许会在某些任务上取得不错的结果,但是在另一些任务(如NLVR)上的表现则相当差。因此,本文提出的ViLT提出了使得文本和图像在更深层次进行交互的方法。
作者梳理了相关工作的情况,如下图所示:
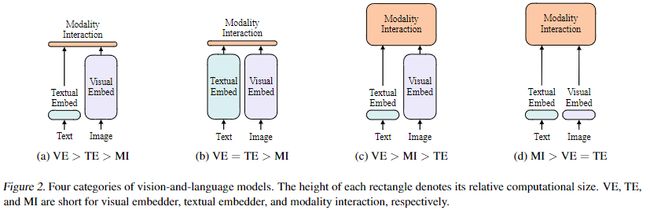
其中, f i g a fig_a figa的典型代表有:VSE(2017)和SCAN(2018); f i g b fig_b figb的典型代表有CLIP(2021); f i g c fig_c figc则是最近图文结合模型选择最多的方式; f i g d fig_d figd是本文提出的模型ViLT的方式。
ViLT是一个单流模型,作者认为双流模型引入了额外参数。在处理视觉特征上,ViLT使用patch projection的方式来代替区域或网格特征。
1、模型结构
ViLT的模型结构如下:
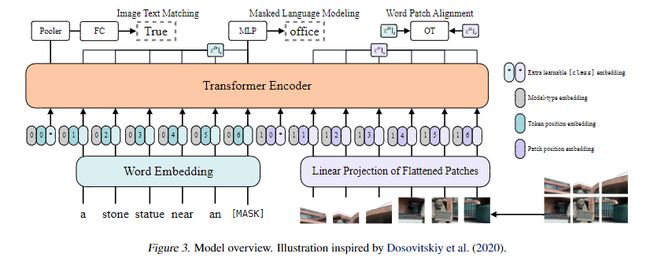
从图中可以看到,文本用0表示,图像用1表示,然后根据各自的位置得到其位置ids,并且,文本的预处理仅一个word embedding,图像的预处理也仅有分patch和linear projection(更具体地,其实是一个卷积层,不过卷积本来也是线性变换,所以说线性层也不错)。最后将concat的向量输入交互层,通过transformer实现模态信息的深层交互。
其中,对于transformer层的参数,作者并没有使用BERT去初始化,而是直接使用ViT初始化,这样在初始化时就可以引入视觉信息,使得即使没有复杂的视觉编码器,也能很好的学习视觉信息。ViT在结构上与BERT的不同在于,BERT的LN在MSA和MLP后面,ViT的LN在它们的前面。
模型的计算流程如下:
t ‾ = [ t c l a s s ; t 1 T ; ⋅ ⋅ ⋅ ; t L T ] + T p o s \overline{t}=[t_{class};t_1T;\cdot\cdot\cdot;t_LT]+T^{pos} t=[tclass;t1T;⋅⋅⋅;tLT]+Tpos
v ‾ = [ v c l a s s ; v 1 V ; ⋅ ⋅ ⋅ ; v N V ] + V p o s \overline{v}=[v_{class};v_1V;\cdot\cdot\cdot;v_NV]+V^{pos} v=[vclass;v1V;⋅⋅⋅;vNV]+Vpos
z 0 = [ t ‾ + t t y p e ; v ‾ + v t y p e ] z^0=[\overline{t}+t^{type};\overline{v}+v^{type}] z0=[t+ttype;v+vtype]
z ^ d = M S A ( L N ( z d − 1 ) ) + z d − 1 \hat{z}^d=MSA(LN(z^{d-1}))+z^{d-1} z^d=MSA(LN(zd−1))+zd−1
z d = M L P ( L N ( z ^ d ) ) + z ^ d z^d=MLP(LN(\hat{z}^d))+\hat{z}^d zd=MLP(LN(z^d))+z^d
p = t a n h ( z 0 D W p o o l ) p=tanh(z^D_0W_{pool}) p=tanh(z0DWpool)
其中MSA表示多头注意力层, t t t表示文本, t ‾ \overline{t} t表示文本的embedding表示,T表示word embedding matrix, T p o s T^{pos} Tpos表示位置向量;v表示分割并flat后的图片,V表示线性层, V p o s V^{pos} Vpos表示图片的位置向量; t t y p e t^{type} ttype与 v t y p e v^{type} vtype表示文本图像的模态类型的embedding向量表示,二者与对应的语义向量表征相加后,进行concat得到对应的输入向量。
其中,图片分包后的embedding求取代码为:
class PatchEmbed(nn.Module):
""" Image to Patch Embedding"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
embed_dim=768,
no_patch_embed_bias=False,
):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=patch_size,
bias=False if no_patch_embed_bias else True,
)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
x = self.proj(x)
return x
transformer模态交互层,一层的代码如下:
class Block(nn.Module):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=False,
qk_scale=None,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop,
)
def forward(self, x, mask=None):
_x, attn = self.attn(self.norm1(x), mask=mask)
x = x + self.drop_path(_x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, attn
从forward的计算过程中可以看出,确实是先进行LN然后进行attn或mlp,其他的结构与bert是一致的,都是12层。
2、预训练任务
ViLT使用的是图文结合常规的预训练任务,ITM和MLM。
(1)ITM
以0.5的概率,用不同的图片随机替换对齐的图片。同时,作者基于单词区域对齐的任务设计了应用于文本+图片的word patch alignment(WPA),用以计算两个子集之间的对齐得分。
(2)MLM
文本常用的预训练任务。
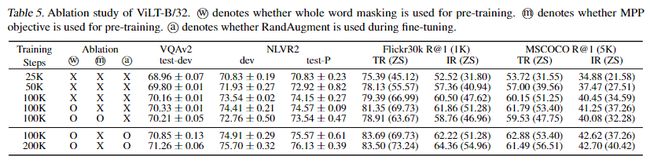
作者预训练时,使用的是whole word masking,同时,在进行微调时,使用了图像增强的手段,除了颜色反转和裁剪,其他的增强技术都进行了实验,这是因为,文本里通常会包含颜色信息(数据集不同会有不同),而裁剪则有可能去掉图片中的重要部分。最后,作者使用的是RandAugment方法(一种插值的方式)对图像进行增强。
作者分别对whole word masking、masked patch prediction以及在微调时是否对图像使用RandAugment的效果进行了消融实验。实验结果如下:
RandAugment的实现如下:
class RandAugment:
def __init__(self, n, m):
self.n = n
self.m = m # [0, 30]
self.augment_list = augment_list()
def __call__(self, img):
ops = random.choices(self.augment_list, k=self.n)
for op, minval, maxval in ops:
val = (float(self.m) / 30) * float(maxval - minval) + minval
img = op(img, val)
return img
其中augment_list()是一个三元组列表,其中的op是一个对图片进行转换的操作。
3、下游任务
ViLT的下游任务有两类,分类和检索。其中分类包括VQA和NLVR,检索就是ITM。
(1)分类
分类的实验结果如下:
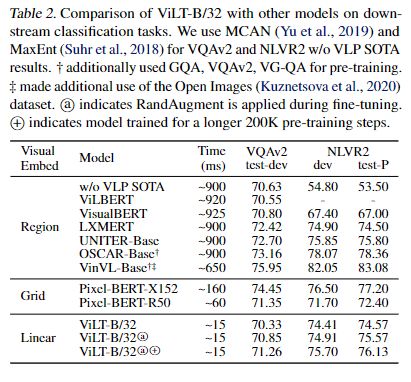
(2)检索
对于检索任务,作者分别做了zeor-shot和non zero-shot的情况,实验结果如下:

可以看到ViLT更多的是在模型结构上的创新,而不是在训练任务上。其通过对图片进行分包以及做卷积的方式实现对图片的编码,在与文本的编码进行concat后通过transformer实现双模态的交互,以实现两者的结合。
ViLT与SOHO有着共同的目的,也就是去掉视觉编码器中的rigion提取结构,以降低模型在推理的延时。但是,ViLT是单流的方式,相比SOHO实现了模态之间更深层次的信息交互,在极快的推理速度下,也保证了在NLVR2等任务上的性能。