Transformer霸榜全景分割任务,南大、港大提出一种通用框架!
来源:机器之心
本文中,来自南大、港大、英伟达等机构的研究者提出了一个使用 transformer 进行端到端全景分割的通用框架,不仅为语义分割与实例分割提供了统一的 mask 预测工作流程,而且使得全景分割 pipeline 更加简洁高效。
语义分割和实例分割是两个重要且相互关联的视觉问题,它们之间的潜在联系使得全景分割可以统一这两个任务。在全景分割中,图像信息被分成两类:Things 和 Stuff。其中 Things 是可数的实例 (例如,人、汽车、自行车),每个实例都有一个惟一的 id,以区别于其他实例。Stuff 是指无定形和不可数的区域 (如天空、草原和雪),没有实例 id。
Things 和 Stuff 之间的差异也导致了不同的处理方式。许多工作只是将全景分割分解为 Things 实例分割任务和 Stuff 语义分割任务。然而,这种分离处理策略会增加模型的复杂性和不必要的工件。虽然一些研究考虑自底向上的实例分割方法,但这种方法仍然保持了类似的分离策略。还有一些方法在处理 Things 和 Stuff 任务时,试图通过在一个统一的框架中来简化全景分割 pipeline 来实现。
来自南京大学、香港大学、英伟达等机构的研究者提出了 Panoptic SegFormer,这是一个使用 Transformer 进行端到端全景分割的通用框架。该方法扩展了 Deformable DETR,并为 Things 和 Stuff 提供了统一的 mask 预测工作流程,使全景分割 pipeline 简洁高效。

论文地址:https://arxiv.org/pdf/2109.03814v1.pdf
该研究使用 ResNet-50 作为网络主干,在 COCO test-dev 拆分中实现了 50.0% 的 PQ,在无需附属条件(bells and whistles)的情况下,结果显著优于 SOTA 方法。此外,使用性能更强的 PVTv2-B5 作为网络主干,Panopoptic SegFormer 在 COCO val 和 test-dev 拆分上以单尺度输入实现了 54.1%PQ 和 54.4%PQ 的新记录。
论文作者之一、英伟达研究院高级研究科学家 Zhiding Yu 表示:「目前,Panoptic SegFormer 在 COCO 2020 全景分割挑战赛中位列第一名。」

COCO 全景分割挑战赛地址:https://competitions.codalab.org/competitions/19507#learn_the_details-overview
方法研究
如图 2 所示,Panoptic SegFormer 由三个关键模块组成:transformer 编码器、位置解码器(location decoder)、掩码解码器(mask decoder)。其中:
(1)transformer 编码器用于细化主干给出的多尺度特征图;
(2)位置解码器用于捕获物体的位置线索;
(3)掩码解码器用于最终分类和分割。

图 2:Panoptic SegFormer 架构。
Transformer 编码器
分割任务中有两个比较重要的因素:高分辨率和多尺度特征图。由于多头注意力层的计算成本很高,以前基于 transformer 的方法只能在编码器中处理低分辨率的特征图,这限制了分割性能。与这些方法不同,该研究使用可变形注意力层来实现 transformer 编码器。由于可变形注意层的计算复杂度较低,因此该研究的编码器可以将位置编码细化为高分辨率和多尺度特征映射。
位置解码器
在全景分割任务中,位置信息在区分具有不同实例 id 的 things 方面起着重要作用。受此启发,该研究设计了一个位置解码器,将 things 和 stuff 位置信息引入到可学习的查询中。
具体来说,给定 N 个随机初始化的查询和由 Transformer 编码器生成的细化特征 token,解码器将输出 N 个位置感知查询。在训练阶段,该研究在位置感知查询之上应用辅助 MLP 头来预测目标物体的中心位置和尺度,并使用位置损失 L_loc 进行监督预测。请注意,MLP 头是一个辅助分支,在推理阶段可以丢弃。
掩码解码器
如图 3 所示,掩码解码器根据给定的查询来预测物体类别和掩码。掩码解码器的查询 Q 是来自位置解码器的位置感知查询,掩码解码器的键 K 和值 V 是来自 transformer 编码器的细化特征 token F。

图 3:掩码解码器架构。
Mask-Wise 推理
全景分割要求为每个像素分配一个类别标签(或空白)和一个实例 id(对于 stuff 忽略 id)。一种常用的后处理方法是启发式过程,它采用类似 NMS 的过程来生成 things 的非重叠实例分割,称之为 mask-wise 策略。
对于 stuff,该研究采用基于启发式过程的 mask-wise 策略来生成非重叠结果,而不是 pixel-wise 策略。此外,该研究平等的对待 things 、stuff ,并通过它们的置信度分数来解决所有掩码之间的重叠,而不是在启发式过程中(things 和 stuff 着两者)倾向于 things,这标志着该研究所用方法与其他方法之间的差异。Mask-Wise 推理过程如下所示:
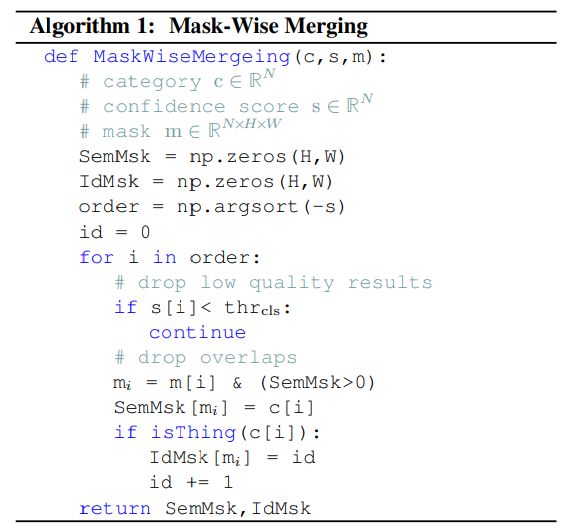
Mask-Wise 推理过程。
实验
该研究在 COCO 上对 Panoptic SegFormer 进行评估,并将其与 SOTA 方法进行比较。实验提供了全景分割的主要结果和一些可视化结果。
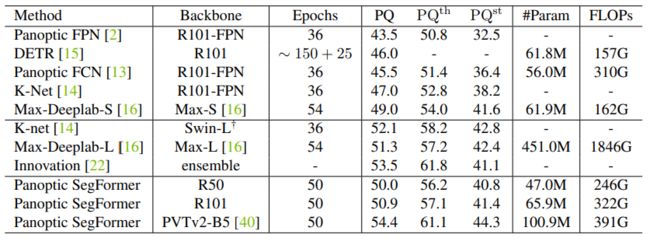
该研究在 COCO val set 和 test-dev set 上进行实验。下表 1 和表 2 报告了 Panoptic SegFormer 与其他 SOTA 方法的对比结果。Panoptic SegFormer 在以 ResNet-50 作为主干和单尺度输入的的情况下,在 COCO val 上获得了 50.0% PQ,并且超过了之前的方法 PanopticFCN 和 DETR ,分别提高了 6.4% PQ 和 6.6% PQ。

表 1:在 COCO val set 上的实验。Panotic SegFormer 在以 ResNet-50 为主干的 COCO val 上实现了 50.0% 的 PQ,超过了之前的方法。
下表 2 中:在 COCO test-dev set 进行实验,以 PVTv2-B5 作为主干,Panoptic SegFormer 在 COCO test-dev 上实现了 54.4% 的 PQ,超越 SOTA 方法 Max-Deeplabe-L 和竞争级方法 Innovation,分别超过 3.1% PQ 和 0.9% PQ,且参数和计算成本更低。
下图 4 显示了在 COCO val set 的一些可视化结果。这些原始图像是高度拥挤或被遮挡的场景,但是 Panoptic SegFormer 仍然可以得到令人信服的结果。

实例分割:下表 3 为在 COCO test-dev set 实例分割结果。为了公平比较,该研究使用 300 个查询进行实例分割,并且只使用 things 数据。以 ResNet-50 作为主干和单尺度输入,Panoptic SegFormer 实现了 41.7 AP,超过了之前的 HTC 和 QueryInst SOTA 方法,且分别超过了 1.6 AP 和 1.1 AP。

下表 4 中展示了模型复杂性和推理效率,得出 Panoptic SegFormer 在可接受的推理速度下,能够实现 SOTA 性能全景分割。

推荐阅读
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
一文总结微软研究院Transformer霸榜模型三部曲!
Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源
加性注意力机制!清华和MSRA提出Fastformer:又快又好的Transformer新变体!
MLP进军下游视觉任务!目标检测与分割领域最新MLP架构研究进展!
周志华教授:如何做研究与写论文?(附完整的PPT全文)
都2021 年了,AI大牛纷纷离职!各家大厂的 AI Lab 现状如何?
常用 Normalization 方法的总结与思考:BN、LN、IN、GN
注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向?
欢迎大家加入DLer-计算机视觉&Transformer群!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

长按识别,邀请您进群!