See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
【写在前面】
基于文本的人员检索是基于文本描述来查找查询对象。关键是要学会在视觉-文本模态之间建立一种共同的潜在空间映射。为了实现这一目标,现有的工作利用分割来获得明确的跨模态对齐或利用注意力来探索显著的对齐。这些方法有两个缺点:1)标记跨模态对齐是耗时的。2)**注意力方法可以探索显著的跨模态对齐,但可能会忽略一些微妙和有价值的对。**为了解决这些问题,作者提出了一个隐式视觉-文本(IVT)框架,用于基于文本的人员检索。与以往的模型不同,IVT利用单一网络来学习两种模态的表示,这有助于视觉-文本的交互。为了探索细粒度的对齐,作者进一步提出了两种隐式语义对齐范式:多层次对齐(MLA)和双向掩码建模(BMM)。MLA模块在句子、短语和单词层面探索更精细的匹配,而BMM模块旨在挖掘视觉和文本模态之间更多的语义对齐。作者在公共数据集(包括CUHK- pedes、RSTPReID和ICFG-PEDES)上进行了大量实验,以评估提出的IVT。即使没有明确的身体部分对齐,本文的方法仍然达到最先进的性能。
1. 论文和代码地址

See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
论文地址:https://arxiv.org/abs/2208.08608
代码地址:https://github.com/TencentYoutuResearch/PersonRetrieval-IVT
2. 动机
人的重新识别(re-ID)有很多应用,例如在监控中寻找嫌疑人或丢失的孩子,在超市中跟踪顾客。基于文本的人物检索(text-based person retrieval, TPR)作为人物re-ID的子任务,近年来备受关注。这是因为文本描述很容易访问,并且可以以自然的方式描述更多的细节。比如,警察通常会查看监控录像,并从目击者那里获取证词。文本描述可以提供补充信息,在缺少图像的场景中甚至是至关重要的。
基于文本的人物检索需要对视觉形态和文本形态进行处理,其核心是学习二者之间的共同潜在空间映射。为了实现这一目标,目前的工作首先利用不同的模型来提取特征,即ResNet50用于视觉形态,LSTM或BERT用于文本形态。然后,他们致力于探索视觉-文本部分对的语义对齐。然而,这些方法至少有两个缺点,可能导致次优的跨模态匹配。首先,单独的模型缺乏形式交互。每个模型通常包含很多层,参数很多,仅利用末端的匹配损失很难实现全交互。为了缓解这一问题,一些关于一般图像-文本预训练的研究使用交叉注意进行交互。但是,它们需要对所有可能的图像-文本对进行编码来计算相似度得分,导致推理阶段的时间复杂度为二次元。如何设计一个更适合TPR任务的网络,还需要深入思考。其次,标记视觉文本的部分对,如头部、上身和下身,是耗时的,而且由于文本描述的可变性,一些对可能会缺失。例如,一些文本包含发型和裤子的描述,但其他文本不包含此信息。一些研究者开始探索隐式局部对齐来挖掘部分匹配。为了保证可靠性,通常选择高置信度的局部匹配。但这些部分通常属于容易通过全局对齐挖掘的显著区域,即不带来额外的信息增益。根据作者的观察,**局部语义匹配不仅要看得更细,而且要看得更多。**一些微妙的视觉文本线索,例如发型和衣服上的标志,可能很容易被忽视,但可以作为全球匹配的补充。
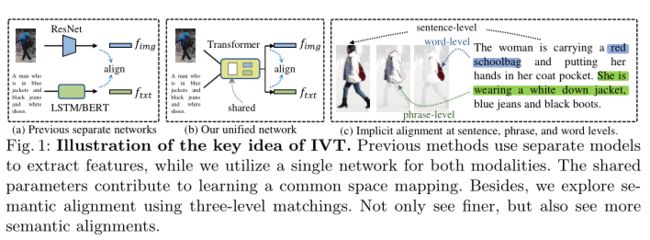
为了解决上述问题,作者首先引入了一个隐式视觉文本(IVT)框架,该框架只使用一个网络就可以学习两种模态的表示(见上图(b))。这得益于Transformer可以对任何可以标记化的模态进行操作。为避免分离模型和交叉注意力模型的缺点,即分离模型缺乏模态交互,交叉注意模型在推理阶段速度较慢。IVT支持单独的特征提取,以确保检索速度,并共享有助于学习公共潜在空间映射的一些参数。为了探索细粒度的模式匹配,作者进一步提出了两种隐式语义对齐范式:多层次对齐(MLA)和双向掩码建模(BMM)。这两种范式不需要额外的手工标记,并且易于实现。具体地说,如上图©所示,MLA旨在通过使用句子、短语和单词级匹配来探索细粒度对齐。BMM与MAE和BEIT有相似的想法,它们都通过随机掩蔽学习更好的表示。不同的是,后两者针对的是单模态的自动编码式重建,而BMM不重建图像,而是侧重于学习跨模态匹配。通过屏蔽一定比例的视觉和文本token,BMM迫使模型挖掘更多有用的匹配线索。提出的两种范式不仅可以看到更好的语义对齐,而且可以看到更多的语义对齐。大量实验证明了TPR任务的有效性。
本文的贡献可以概括为三个方面:
(1)提出了从骨干网的角度解决模态对齐问题,并引入了隐式视觉文本(IVT)框架。这是第一个统一的基于文本的人员检索框架。
(2)提出了两种隐式语义对齐范式,即MLA和BMM,使模型能够挖掘更精细和更精确的语义对齐。
(3)对三个公共数据集进行了广泛的实验和分析。实验结果表明,本文的方法达到了最先进的性能。
3. 方法
3.1 Overview
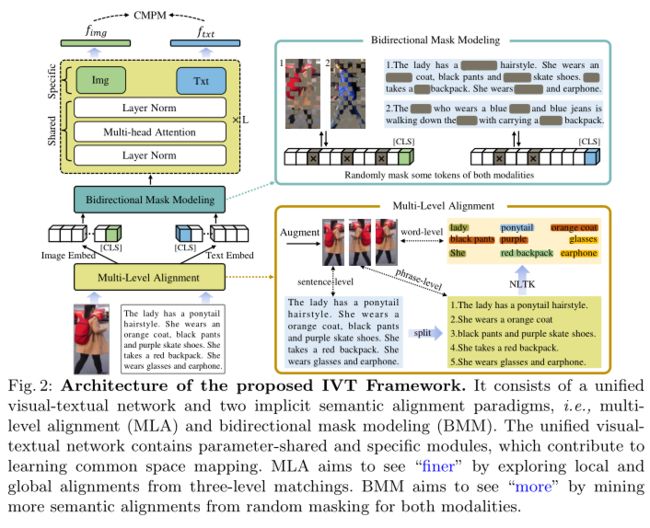
为了解决基于文本的人物检索中的形态对齐问题,作者提出了一个隐式视觉-文本(IVT)框架,如上图所示。它由统一的视觉-文本网络和两种隐式语义对齐范式组成,即多层对齐(MLA)和双向掩码建模(BMM)。IVT的一个关键思想在于使用统一的网络来处理模态对齐。通过共享一些模块,如层归一化和多头注意,统一的网络有助于学习视觉和文本模式之间的共同空间映射。它还可以使用不同的模块学习特定于模态的线索。提出了两种隐式语义对齐范式,即MLA和BMM,以探讨细粒度的语义对齐。不同于以往的手工加工部件或从注意力中选择突出部件的方法,这两种范式不仅可以挖掘出更精细的语义对齐,而且可以挖掘出更多的语义对齐,这是作者提出的IVT的另一个关键思想。
3.2 Unified Visual-Textual Network
Embedding
如上图所示,输入是图像-文本对,从视觉和文本两种方式提供一个人的外观特征。设图像-文本对记为 { x i , t i , y i } ∣ i = 1 N \left.\left\{x_{i}, t_{i}, y_{i}\right\}\right|_{i=1} ^{N} {xi,ti,yi}∣i=1N,其中 x i , t i , y i x_{i}, t_{i}, y_{i} xi,ti,yi分别表示图像,文本和身份标签。N为样本总数。对于输入图像 x i ∈ R H × W × C x_{i} \in \mathbb{R}^{H \times W \times C} xi∈RH×W×C,首先将其分解为 K = H ⋅ W / P 2 K=H \cdot W / P^{2} K=H⋅W/P2个patch,其中P表示patch的大小,然后将其线性投影为patch嵌入 { f k v } ∣ k = 1 K \left.\left\{f_{k}^{v}\right\}\right|_{k=1} ^{K} {fkv}∣k=1K。该操作可以使用一个卷积层来实现。然后在patch嵌入之前添加一个可学习的类token f c l s v f_{c l s}^{v} fclsv,并添加一个可学习的位置嵌入 f p o s v f_{p o s}^{v} fposv和一个类型嵌入 f type v f_{\text {type }}^{v} ftype v。
f v = [ f cls v , f 1 v , … , f K v ] + f p o s v + f type v . \mathbf{f}^{v}=\left[f_{\text {cls }}^{v}, f_{1}^{v}, \ldots, f_{K}^{v}\right]+f_{p o s}^{v}+f_{\text {type }}^{v} . fv=[fcls v,f1v,…,fKv]+fposv+ftype v.
对于输入文本 t i t_{i} ti,它通常由一个或几个句子组成,每个句子有一个单词序列。利用预训练好的单词嵌入,将单词投射到符号向量中:
f t = [ f c l s t , f 1 t , … , f M t , f s e p t ] + f p o s t + f type t \mathbf{f}^{t}=\left[f_{c l s}^{t}, f_{1}^{t}, \ldots, f_{M}^{t}, f_{s e p}^{t}\right]+f_{p o s}^{t}+f_{\text {type }}^{t} ft=[fclst,f1t,…,fMt,fsept]+fpost+ftype t
其中 f c l s t f_{c l s}^{t} fclst和 f s e p t f_{s e p}^{t} fsept表示开始和结束标记。M表示标记化子字单元的长度。 f p o s t f_{p o s}^{t} fpost是位置嵌入, f type t f_{\text {type }}^{t} ftype t是类型嵌入。
Visual-Textual Encoder
目前在TPR任务上的工作使用了独立的模型,这些模型缺乏完整的模态交互。最近一些关于一般图像-文本预训练的研究试图利用交叉注意来实现形态交互。但是交叉注意需要在推理阶段对所有可能的图像-文本对进行编码,导致检索速度非常慢。在此基础上,作者提出将统一的视觉-文本网络用于TPR任务。统一网络检索速度快,支持模式交互。
如上图所示,网络遵循ViT的标准架构,共堆叠L块。在每个块中,两种模态共享层归一化(LN)和多头自注意(MSA),有助于学习视觉和文本模态之间的公共空间映射。这是因为共享参数有助于了解公共数据统计。例如,LN将计算输入token嵌入的平均值和标准差,而共享LN将学习两种模态在统计上的共同值。从数据级的角度来看,这可以被视为一种“形态交互”。由于视觉和文本的模态不同,每个block都有模态相关的前馈层,即上图中的“Img”和“Txt”模块。它们通过切换到可视或文本输入来捕获特定于模态的信息。每个块的完整处理可以表示为:
f i v / t = MSA ( LN ( f i − 1 v / t ) ) + f i − 1 v / t f i v / t = M L P i m g / t x t ( L N ( f i v / t ) ) + f i v / t \begin{aligned} \mathbf{f}_{i}^{v / t} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{f}_{i-1}^{v / t}\right)\right)+\mathbf{f}_{i-1}^{v / t} \\ \mathbf{f}_{i}^{v / t} &=\mathrm{MLP}_{\mathrm{img} / \mathrm{txt}}\left(\mathrm{LN}\left(\mathbf{f}_{i}^{v / t}\right)\right)+\mathbf{f}_{i}^{v / t} \end{aligned} fiv/tfiv/t=MSA(LN(fi−1v/t))+fi−1v/t=MLPimg/txt(LN(fiv/t))+fiv/t
其中LN表示层归一化,MSA表示多头注意。i是块的索引。 f i − 1 v / t \mathbf{f}_{i-1}^{v / t} fi−1v/t是第i个块的视觉或文本输出,也是第i个块的输入。 M L P i m g / t x t \mathrm{MLP}_{\mathrm{img} / \mathrm{txt}} MLPimg/txt表示特定于模态的前馈层。 f i v / t \mathbf{f}_{i}^{v / t} fiv/t是第I个块的输出。
Output
最后一个块的类token作为全局表示,即上图中的 f i m g f_{i m g} fimg和 f t x t f_{txt} ftxt。两个特征向量的维数都为768,输出用LN层进行归一化。
3.3 Implicit Semantic Alignment
Multi-Level Alignment
细粒度对齐已被证明是实现性能改进(如分段属性,stripe-based部分)的关键。这些方法可以看作是显式的部分对齐,即告诉模型哪些视觉文本部分应该对齐。在这项工作中,作者提出了一种隐式对齐方法,即多层次对齐,这是一种直观而有效的方法。
如上图所示,作者对输入图像进行增强,得到水平翻转和随机裁剪三种类型的增强图像。输入文本通常由一个或几个句子组成。作者根据句号和逗号把它们分成更短的句子。这些短句被视为“短语级”表征,描述了人体的部分外观特征。为了挖掘更精细的部分,进一步利用自然语言工具包(NLTK)提取描述特定地方特征的名词和形容词,例如包、衣服或裤子。三个层次的文本描述,即句子层次、短语层次和词汇层次,对应三种增强图像。在每次迭代中随机生成三层图像-文本对。通过这种方式,作者构建了一个从全局到局部逐渐细化的匹配过程,迫使模型挖掘更精细的语义对齐。
本文的方法与以前的工作的主要区别是,作者没有显式地定义视觉语义部分,而是自动地探索由三级文本描述指导的对齐的视觉部分。这是由于以下观察结果启发了本文的TPR框架:
1)以往的显式对齐方法在训练阶段和推理阶段之间缺乏不一致性。在训练过程中,以前的方法利用一种无监督的方式来探索局部对齐,例如,根据相似性选择top-k显著对齐。在推断阶段,每个模态只使用全局嵌入,导致不一致的问题。
2)显式局部对齐使训练变得容易,但在推理阶段使训练变得困难。过于简化的任务设计会导致模型泛化性能下降。虽然不提供视觉部分,而是提供完整的图像,但模型在训练阶段努力挖掘局部对齐,因此在推理阶段由于一致性获得了更好的性能。
Bidirectional Mask Modeling
为了自动挖掘局部对齐,最近的方法]将图像分成条状,并利用注意力选择top-k部分对齐。然而,他们忽略了一个事实,即top-k部分对齐通常是显著的线索,这可能已经被全局对齐挖掘。因此,这些部分带来的信息收益有限。作者认为,**局部对齐不仅应该更精细,而且应该更多样化。**一些微妙的视觉-文本线索可能是全局对齐的补充。
如上图所示,作者提出了一种双向掩码建模(BMM)方法来挖掘更多的语义对齐。对于图像和文本标记,作者随机屏蔽它们中的某些百分比,然后强制视觉输出和文本输出保持一致。通常,掩码token对应于图像或文字的特定patch。如果特定的补丁或单词被屏蔽,该模型将试图从其他补丁或单词中挖掘有用的对齐线索。以上图中的女士为例,如果将“橙色外套”和“黑色裤子”这两个突出的词语蒙住,模特会更加关注其他词语,如马尾发型、红色背包。通过这种方式,可以探索更微妙的视觉-文本对齐。在训练阶段,该方法增加了模型对图像和文本对齐的难度,但有助于模型在推理阶段挖掘更多的语义对齐。
上述方法与随机擦除、MAE和BEIT有相似的想法。然而,随机擦除只mask一个区域。MAE和BEIT的目标是使用一种自编码方式进行图像重建。该算法不重构图像,只关注交叉模态匹配。
3.4 Loss Function
作者利用常用的跨模态投影匹配(CMPM)损失来学习视觉-文本对齐,其定义如下:
L c m p m = 1 B ∑ i = 1 B ∑ j = 1 B ( p i , j ⋅ log p i , j q i , j + ϵ ) , p i , j = exp ( f i T ⋅ f j ) ∑ k = 1 B exp ( f i T ⋅ f k ) , q i , j = y i , j ∑ k = 1 B y i , k , \mathcal{L}_{c m p m}=\frac{1}{B} \sum_{i=1}^{B} \sum_{j=1}^{B}\left(p_{i, j} \cdot \log \frac{p_{i, j}}{q_{i, j}+\epsilon}\right),\\p_{i, j}=\frac{\exp \left(f_{i}^{T} \cdot f_{j}\right)}{\sum_{k=1}^{B} \exp \left(f_{i}^{T} \cdot f_{k}\right)}, \quad q_{i, j}=\frac{y_{i, j}}{\sum_{k=1}^{B} y_{i, k}}, Lcmpm=B1i=1∑Bj=1∑B(pi,j⋅logqi,j+ϵpi,j),pi,j=∑k=1Bexp(fiT⋅fk)exp(fiT⋅fj),qi,j=∑k=1Byi,kyi,j,
其中 p i , j p_{i, j} pi,j为匹配概率。 f i f_{i} fi和 f j f_{j} fj表示不同模态的整体特征。B为mini-batch大小。 q i , j q_{i, j} qi,j表示归一化真匹配概率。 ϵ \epsilon ϵ是一个避免数值问题的小数字。
CMPM损失表示从分布q到p的KL散度。按照以前的工作,从图像到文本和文本到图像两个方向计算匹配损失。损失可以表示为:
L = L c m p m t 2 v + L c m p m v 2 t \mathcal{L}=\mathcal{L}_{c m p m}^{t 2 v}+\mathcal{L}_{c m p m}^{v 2 t} L=Lcmpmt2v+Lcmpmv2t
4.实验
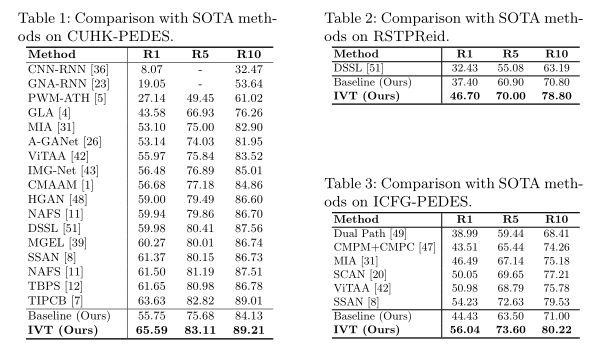
本文方法在三个常见Text-based ReID数据集上的实验结果。
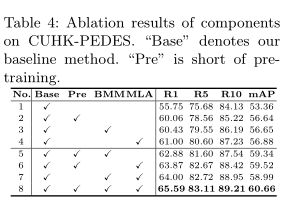
如上表所示,基线在R1和mAP上分别达到55.75%和53.36%。引入MLA模块后,整体性能提升至61.00%和56.88%。
BMM策略在本文的框架中也扮演着重要的角色,如上表所示。通过对比No.1和No.3,可以发现R1和mAP从55.75%、53.36%提高到60.43%、56.65%。
即使没有预先训练,IVT在R1上的准确率也达到了64%(见No.7),超过了目前的SOTA方法,如NAFS (61.50%), TBPS(61.65%)。为了获得更好的泛化特征,作者使用大规模的图像-文本语料库对模型进行预训练。如上表所示,可以发现整体性能也可以显著提高。其中R1和mAP在训练前分别从55.75%、53.36%提高到60.06%、56.64%(见No.1和No.2)。

当比值设置为0.3时,R1和mAP达到峰值。然后随着掩蔽比的继续增大,性能逐渐下降。这是因为掩蔽比太大时,模型无法挖掘足够的语义对齐,从而降低了最终性能。

与基线方法相比,提出的IVT获得了更多的阳性样本。这是因为它可以捕获更细粒度的对齐。

为了更好地理解视觉和文本对齐,作者给出了一些句子级热图的可视化。热图是通过可视化文本[CLS]标记和所有可视化标记之间的相似性来获得的。一般来说,文本描述可以与人体相对应,这表明模型已经学会了视觉和文本模式的语义相关性。
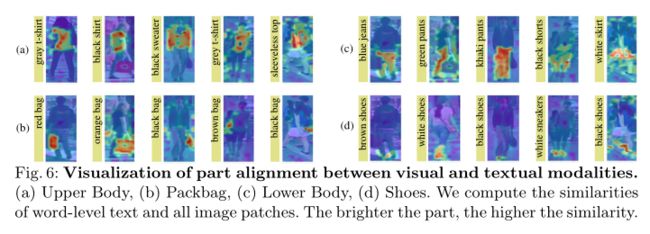
为了验证细粒度对齐的能力,作者进一步进行word级对齐实验。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”