pytorch深度学习实战lesson35
第三十五课 物体检测、边缘框实现、数据集
目标检测,或者叫物体检测,或者叫 object detection,是计算机视觉里面也算是用得最为广泛的一个应用了。虽然开始一直在讲图片分类,但实际在计算机视觉的应用里面,图片分类相对来说用的没那么多。因为你说我给你一张图片,我说这里面有只猫,有只狗。其实在对用户来讲,这个东西好像也不显得那么重要,因为图片里面其实有很多东西。目标检测或者物体检测其实想尝试去看一下这个图片里面有到底有哪些东西。所以我们可以很简单的看一下它跟图片分类的区别。
目录
理论部分
物体检测
实践部分
物体检测
目标检测数据集
理论部分
物体检测

图片分类我们知道,在一张图片里面,我们认为它是有一个主体,我们去把主体找出来,比如左边图片有一只狗,主要就是一只狗了,别的东西都是相对来说比较少小或者是背景就不关心了。但对目标检测来说就会不一样。在上边这张图片里面有两只狗,一只猫,所以我们的任务是我们要去识别里面所有我们感兴趣的物体。比如说我们对猫和狗感兴趣,我们需要把所有的猫和狗给找出来。而且还不仅仅是这样,我们还需要将每个物体的位置给你找出来。我要预测狗的位置,就通过一个方框来表示。所以目标检测当图片更加复杂的时候,它不仅可以进行多个物体的识别,而且能把它的位置给你找出来。所以它在应用场景中用的更多一点。因为我们很有可能想知道一个图片里面到底有哪一些主要的物体。

边缘框是用来表示物体的位置,比如说这只狗的位置,用一个大概的边框把它框在一起,比如蓝框就表示狗的位置的地方,红框就表示猫的位置。
一个边框可以用 4 个数字来定义,比如有两种常用的定义方法,一个是左上的 x 坐标和 y 坐标。另外一个表示方法是可以用另外 4 个数字,一个是我还是一样的用左上的 x 和左上的y。接下来不需要右下的坐标了,用宽和高代替。有了宽和高照样可以得到右下角的坐标。

图片数据集一般来说,每一个类是一个子文件夹,它对应的标号的图片放在子文件夹下面,这是图片分类的数据集,它表示起来比较方便。但目标检测的数据集这一种方法就不能用了,因为一个图片里面可能有多个类,所以不能放在子文件夹里。所以通常来说,目标检测数据集它的标号是要额外存的。一般最简单的办法是每一行表示一个物体,这里面分别有文件名字,物体的类别,它的边缘框坐标。因为一个文件的图片里面可能有多个物体,然后同一个文件名可能会出现多次。假设有 5 个物体,那么文件名会出现 5 次,因为它每一行表示的是一个图片里面的物体。接下来就是标号,也就是物体边框的位置坐标,有4个值。
在目标检测里边一个常见的数据就叫做Coco,它有 80 个物体,每个物体一般来说都是我们日常生活中看到的图片,它的类别数远远的少于Imagenet,它只有 80 个类别,大概有 33 万张图片。它每张图片里面标了多个物体,有150 万个物体。所以 Coco 也是一个很大的数据集了。,也是在学术界是用的非常广泛的一个数据集。

实践部分
物体检测


代码:
#我们收集并标记了一个小型数据集 下载数据集
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
import matplotlib.pyplot as plt
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
#读取香蕉检测数据集
'''通过read_data_bananas函数,我们读取香蕉检测数据集。
该数据集包括一个的CSV文件,内含目标类别标签和位于左上角和右下角的真实边界框坐标。'''
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签。"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir,
'bananas_train' if is_train else 'bananas_val',
'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(
torchvision.io.read_image(
os.path.join(data_dir,
'bananas_train' if is_train else 'bananas_val',
'images', f'{img_name}')))
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
#创建一个自定义 Dataset 实例
'''通过使用read_data_bananas函数读取图像和标签,
以下BananasDataset类别将允许我们创建一个自定义Dataset实例来加载香蕉检测数据集。'''
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集。"""
def __init__(self, is_train):#把所有数据读出来
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (
f' training examples' if is_train else f' validation examples'))
def __getitem__(self, idx):#读第i个样本
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
#为训练集和测试集返回两个数据加载器实例
'''最后,我们定义load_data_bananas函数,来为训练集和测试集返回两个数据加载器实例。
对于测试集,无须按随机顺序读取它。
'''
def load_data_bananas(batch_size):
"""加载香蕉检测数据集。"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
#读取一个小批量,并打印其中的图像和标签的形状
'''让我们读取一个小批量,并打印其中的图像和标签的形状。 图像的小批量的形状为(批量大小、通道数、高度、宽度),
看起来很眼熟:它与我们之前图像分类任务中的相同。
标签的小批量的形状为(批量大小,,5),其中是数据集的任何图像中边界框可能出现的最大数量。
小批量计算虽然高效,但它要求每张图像含有相同数量的边界框,以便放在同一个批量中。 通常来说,图像可能拥有不同数量个边界框;
因此,在达到之前,边界框少于的图像将被非法边界框填充。 这样,每个边界框的标签将被长度为5的数组表示。
数组中的第一个元素是边界框中对象的类别,其中-1表示用于填充的非法边界框。
数组的其余四个元素是边界框左上角和右下角的(,)坐标值(值域在0~1之间)。 对于香蕉数据集而言,由于每张图像上只有一个边界框,因此。'''
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
print(batch[0].shape, batch[1].shape)
#示范
'''让我们展示10幅带有真实边界框的图像。 我们可以看到在所有这些图像中香蕉的旋转角度、大小和位置都有所不同。
当然,这只是一个简单的人工数据集,实践中真实世界的数据集通常要复杂得多。'''
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
plt.show()
目标检测数据集


代码:
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
d2l.set_figsize()
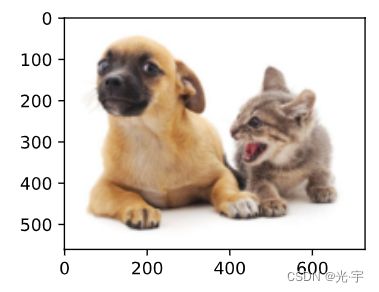
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img)
plt.show()
#定义在这两种表示之间进行转换的函数
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
#定义图像中狗和猫的边界框
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox, cat_bbox))
print(box_center_to_corner(box_corner_to_center(boxes)) == boxes)
#将边界框在图中画出
def bbox_to_rect(bbox, color):
return d2l.plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0],
height=bbox[3] - bbox[1], fill=False,
edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));