不定期读一篇Paper之SKNet
不定期读一篇Paper之SKNet
前言
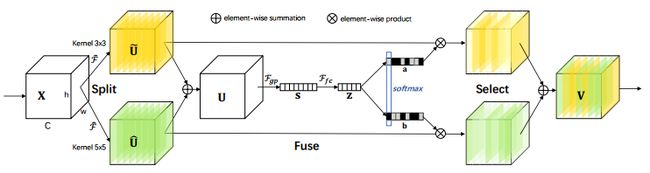
SKNet是SEnet的升级版本,你会在里面看到很多SENet的身影。首先,由于传统的卷积网络在某一层所关注的感受野的大小是相同,所以,SKNe提出关注同一层不同的感受野,并且SKNet提出动态的选择不同的感受野。这里引用作者原话:用multiple scale feature汇总的information来channel-wise地指导如何分配侧重使用哪个kernel的表征。
网络框架
pytorch代码:
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
""" Constructor
Args:
features: input channel dimensionality.
WH: input spatial dimensionality, used for GAP kernel size.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
# 增加不同的感受野
for i in range(M):
self.convs.append(
nn.Sequential(
nn.Conv2d(features,
features,
kernel_size=3 + i * 2,# 3*3 -> 5*5 ->..
stride=stride,
padding=1 + i,
groups=G), nn.BatchNorm2d(features),
nn.ReLU(inplace=False)))
print("D:", d)
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(nn.Linear(d, features))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
# 融合不同的通道
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
# 全局平局池化
fea_s = fea_U.mean(-1).mean(-1)
# M个不同的卷积,有M个不同的全连接
fea_z = self.fc(fea_s)
# select:获得Az、Bz
for i, fc in enumerate(self.fcs):
# fc-->d*c维
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector],
dim=1)
# 计算attention分数
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
上述代码中主要留意softmax的操作,是不同分支的同一channel进行softmax,进而对于属于同一channal不同感受野的特征图进行选择,从而实现对于对不同感受野的选择,代码如下:
# input
# tensor([[[0.8863, 0.7459, 0.1939],
# [0.3261, 0.2417, 0.8906]]])
# 此处只是列举,原理与源代码相似
b = nn.Softmax(dim=1)
b(a)
# output
# tensor([[[0.6365, 0.6234, 0.3325],
# [0.3635, 0.3766, 0.6675]]])
pytroch可视化:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [1, 256, 24, 24] 590,080
BatchNorm2d-2 [1, 256, 24, 24] 512
ReLU-3 [1, 256, 24, 24] 0
Conv2d-4 [1, 256, 24, 24] 1,638,656
BatchNorm2d-5 [1, 256, 24, 24] 512
ReLU-6 [1, 256, 24, 24] 0
Linear-7 [1, 128] 32,896
Linear-8 [1, 256] 33,024
Linear-9 [1, 256] 33,024
Softmax-10 [1, 2, 256] 0
================================================================
实验
暂无(以后会补上)
总结
SKNet中用的很多技巧,比如使用分组卷积来减少参数,使用空洞卷积来增大感受野等,但是最终的实验效果是明显的,所以,这又是一个易于集成的Attetion模块。
参考
论文地址
作者代码(caffe)
SKNet——SENet孪生兄弟篇