文本预处理方法总结
数据的预处理
项目需要,需要进行词库训练与样本向量化处理,总结后有以下4种方法:
方法1:tf 1.xx版本:
词汇样本的处理:使用tensorflow.contrib.learn模块
vocab_process = learn.preprocessing.VocabularyProcessor(max_document_length)
vocab_process.fit(x_test)
vocab_process.save(path)
训练好的字典模型加载:
vocab_processor = learn.preprocessing.VocabularyProcessor.restore(vocab_path)
输入格式:x_test:[‘’,‘’,‘’,‘’,…] 样本格式,每个样本之间的字符以空格隔开,eg:
x_test = [‘I love you’, ‘me too’]


会增加一个UNK 表示未知字符
新来的样本会依据得到的词库进行索引表示,如上的I me too 得到的结果为[1, 4, 5,0]
输入:x_test = [‘i love you’,‘me you too’,‘you love me’]
训练结果:{‘me’: 4, ‘love’: 2, ‘i’: 1, ‘too’: 5, ‘you’: 3, ‘’: 0}
输出:[1, 2, 3, 0]
[4, 3, 5, 0]
[3, 2, 4, 0]
因为后续需要兼容py27和py38,但是py38只有tf2xx版本,考虑其他方式进行处理,可以使用keras或者纯代码编写,或者word2vec。
方法2: word2vec:
使用gensim.models.word2vec中的 Word2Vec
模型训练:
model = Word2Vec(text,…)
model.save(model_path)
模型加载更新:
model = Word2Vec.load(model_path)
model.build_vocab(text, update= True) 更新词汇表
model.train(text,total_examples=model.corpus_count, epochs=model.iter)
word2vec(sentence,min_count)训练的时候,如果输入列表就不会按字符分割了,训练好之后,使用wv vocab可以查看字典;
Word2Vec([i.split(’ ') for i in x_text],min_count=1).wv.vocab
方法3:keras数据预处理:

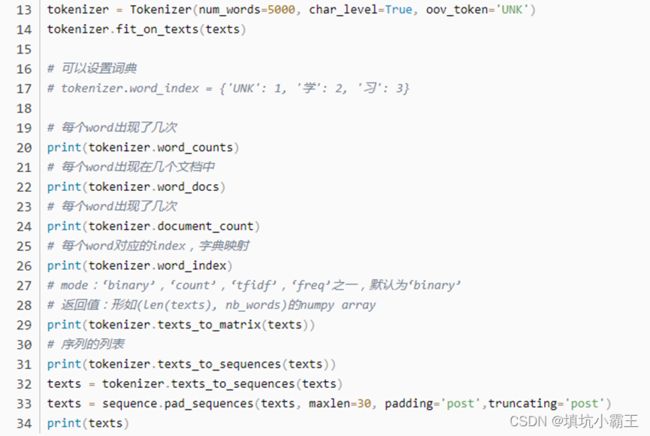
Tokenizer建立的时候,如果想根据字符分割就char_level=true,如果不想就不要填写

text_to_word_sequence(text)按空格分割语料



输入:[‘i love you’,‘me you too’,‘you love me’]
训练结果:{‘me’: 4, ‘love’: 3, ‘i’: 5, ‘too’: 6, ‘you’: 2, ‘UNK’: 1}
输出:[[5, 3, 2], [4, 2, 6], [2, 3, 4]]
想要填充的话使用pad_sequences进行,可以选择填充在前面还是后面;
tips:tf中的数据预处理生成的字典没有根据词频的大小进行排序,但是keras这里是根据词频进行大小排列的;且UNK在tf中的标识是0,在这里是1,填充的时候可以选择填充的值;
方法4:纯代码编写:
统计单词出现的频数后进行排序
import codecs
import collections
import re
from operator import itemgetter
data_path="Lord of the rings.txt" #输入文本
vocab_path="vocab.txt" #单词文本
output_path="train.txt" #语句中相应单词对应的编码数
counter = collections.Counter() #生成空字典,用来统计单词频数
with codecs.open(data_path, "r", "utf-8") as f:
for line in f:
for word in re.split("\W+",line.strip()):
counter[word] += 1
f.close()
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True) #按照单词频数进行由大到小排序
sorted_words = [x[0] for x in sorted_word_to_cnt]
if len(sorted_words) > 10000:
sorted_words = sorted_words[:10000]
with codecs.open(vocab_path, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + '\n')
file_output.close()
with codecs.open(vocab_path, 'r', 'utf-8') as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))}
def get_id(word):
return word_to_id[word]
fin = codecs.open(data_path, 'r', 'utf-8')
fout = codecs.open(output_path, 'w', 'utf-8')
for line in fin:
for words in re.split("\W+",line.strip()):
out_line = " ".join([str(get_id(words))]) + '\n' #寻找单词对应的编码数
fout.write(out_line)
fin.close()
fout.close()