TensorFlow Serving + Docker + Tornado机器学习模型生产级快速部署
点击上方“AI搞事情”关注我们
内容转载自知乎:https://zhuanlan.zhihu.com/p/52096200

Justin ho
〉
本文将会介绍使用TensorFlow Serving + Docker + Tornado来部署机器学习模型到生产环境的方法。在往下看之前,答应我,这么干货的文章先点赞再收藏好吗?
2019-12-12更新:由于tensorflow更新至2.0.0之后,1.x的一些api已经不再使用,本教程使用的部分代码不能在tf 2.0以上的版本运行。如果您想查看最新的教程,可以看我的后一篇文章:
一、简介
当我们训练完一个tensorflow(或keras)模型后,需要把它做成一个服务,让使用者通过某种方式来调用你的模型,而不是直接运行你的代码(因为你的使用者不一定懂怎样安装),这个过程需要把模型部署到服务器上。常用的做法如使用flask、Django、tornado等web框架创建一个服务器app,这个app在启动后就会一直挂在后台,然后等待用户使用客户端POST一个请求上来(例如上传了一张图片的url),app检测到有请求,就会下载这个url的图片,接着调用你的模型,得到推理结果后以json的格式把结果返回给用户。
这个做法对于简单部署来说代码量不多,对于不熟悉web框架的朋友来说随便套用一个模板就能写出来,但是也会有一些明显的缺点:
1. 需要在服务器上重新安装项目所需的所有依赖。
2. 当接收到并发请求的时候,服务器可能要后台启动多个进程进行推理,造成资源紧缺。
3. 不同的模型需要启动不同的服务。
而为了解决第一个问题,Docker是最好的方案。这里举一个不是十分准确但是能帮助理解的例子:Docker在直觉上可以理解成为码头上的“集装箱”,我们把计算机系统比喻成码头,把应用程序比喻成码头上的货物,当集装箱还未被发明的时候,货物在码头上到处乱放,当要挑选某些货物的时候(执行程序),工人们到处乱找彼此干扰(依赖冲突),影响效率。如果把货物装在一个个集装箱里面,那么每个集装箱里面的货物整理就不会影响到其它集装箱。
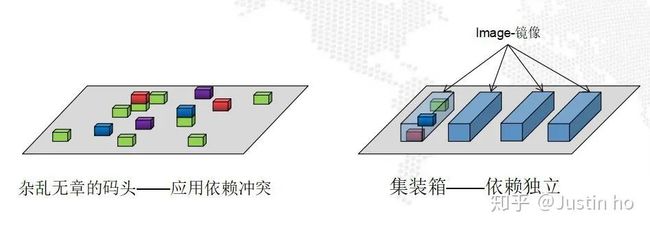
Docker有两个重要概念,分别是image(镜像)和container(容器)。image可以理解成python中的类,container就是类的一个instance(实例)。我们把image pull到本地后,在这个image中启动一个container,然后我们就可以进入这个container里面做我们想做的事,例如配置环境,存放文件等等,这个过程可以形象地理解成我们买了一台新电脑,然后打开电脑装软件。

针对第二个问题,对于使用tensorflow、keras框架进行算法开发的用户来说,TensorFlow Serving(官网)能够很简单的把你的模型挂在服务器后台,然后你只需要写一个客户端把请求发过去,它就会把运算后的结果返回给你。而TensorFlow Serving的最佳使用方式就是使用一个已经编译好TensorFlow Serving功能的docker,你所要做的只是简单的运行这个docker即可。
TensorFlow Serving还支持同时挂载多个模型或者多个版本的模型,只需简单地指定模型名称即可调用相应的模型,无需多写几份代码、运行多个后台服务。因此优势在于:
1. 自动刷新使用新版本模型,无需重启服务。
2. 无需写任何部署代码。
3. 可以同时挂载多个模型。
二、导出你的模型
TensorFlow Serving只需要一个导出的tensorflow或keras模型文件,这个模型文件定义了整个模型的计算图,因此我们首先把一个训练好的模型进行导出,tensorflow模型导出代码例子如下:
with tf.get_default_graph().as_default():
# 定义你的输入输出以及计算图
input_images = tf.placeholder(tf.float32, shape=[None, None, None, 3], name='input_images')
output_result = model(input_images, is_training=False) # 改成你实际的计算图
saver = tf.train.Saver(variable_averages.variables_to_restore())
# 导入你已经训练好的模型.ckpt文件
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
ckpt_state = tf.train.get_checkpoint_state(FLAGS.checkpoint_path)
model_path = os.path.join(FLAGS.checkpoint_path,
os.path.basename(ckpt_state.model_checkpoint_path))
print('Restore from {}'.format(model_path))
saver.restore(sess, model_path)
# 定义导出模型的各项参数
# 定义导出地址
export_path_base = FLAGS.export_model_dir
export_path = os.path.join(
tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(FLAGS.model_version)))
print('Exporting trained model to', export_path)
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# 定义Input tensor info,需要前面定义的input_images
tensor_info_input = tf.saved_model.utils.build_tensor_info(input_images)
# 定义Output tensor info,需要前面定义的output_result
tensor_info_output = tf.saved_model.utils.build_tensor_info(output_result)
# 创建预测签名
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': tensor_info_input},
outputs={'result': tensor_info_output},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict_images': prediction_signature})
# 导出模型
builder.save(as_text=True)
print('Done exporting!')代码中有许多难懂的API,但大概流程都是先定义好模型计算图,然后导入训练好的参数(一般都是ckpt文件),接着创建一个builder,定义好几个导出模型所需的东西,其中最重要的是指定输入输出,build_tensor_info这个方法会指定输入输出所在计算图的节点,最后builder会帮你导出模型。注意上面的代码适用于回归问题,如果是分类问题等,可以参考官方文档中,有关tf.saved_model.signature_constants的METHOD_NAME的介绍。如果你想理解所有API的意义,TensorFlow的《Serving a TensorFlow Model》、《保存和恢复》文章能够帮助你。如果你想马上就能使用,参考上面的代码基本没问题。导出的文件结构如下:

keras的导出代码稍微简单一点,可以参考一下来自《keras、tensorflow serving踩坑记》这篇文章的代码。
如果模型的输出还不是最终的结果,需要进行其它运算,请尽可能把后处理的操作都用tf或者keras的API写进计算图的节点里面,尽量使模型的预测结果就是最终的结果,否则需要在web的代码中对返回的结果进行其它处理。
可以看到,TensorFlow Serving不需要其它环境依赖,只要tensorflow版本对了,导出的模型就能直接在TensorFlow Serving上使用,接收输入,返回输出,无需写任何部署代码。
三、Docker
1. 安装docker
TensorFlow Serving的安装推荐使用docker,所以必须先安装docker。docker安装命令请参考官网页面。
如果你运行安装测试时看到以下语句,证明安装成功:
Hello from Docker!
This message shows that your installation appears to be working correctly.2. 安装nvidia-docker
接着,我们需要安装docker的nvidia插件,nvidia-docker能够使你的应用在GPU上运行,安装nvidia-docker请参考官方页面。
安装命令最后一句是用于验证nvidia-docker是否安装成功,如果你能看见nvidia-smi输出的显卡信息,证明已经安装成功。如果想了解更多Docker的基础知识,可以阅读:Docker Documentation或者Docker -- 从入门到实践这些教程文章。
3. 拉取TensorFlow Serving镜像
TensorFlow Serving已经制作了基于多个tensorflow版本的docker,你可以在TensorFlow Serving Docker Tag这个页面找到你想要的版本。例如你的代码是基于tensorflow 1.11.1的话,那就可以选择“1.11.1”、“1.11.1-devel”、“1.11.1-devel-gpu”、“1.11.1-gpu”,这几个的区别在于,只有版本号不带devel的是cpu版本,是官方封装好的docker,无法对其进行任何修改;带devel的是development版本,你可以进入镜像的容器里面修改配置,然后使用docker的commit命令来保存修改;带gpu的是gpu版本,同样如果不带devel就无法修改里面的配置。

我们这里假设使用最新的非开发版的gpu版本,即:“latest-gpu”,用docker pull命令把镜像拉到本地:
sudo docker pull tensorflow/serving:latest-gpuDocker会把所需的文件下载到本地,下载速度因你的带宽而异,带gpu版本的镜像下载时间会更长一点。如果你想通过阿里云源来加快下载速度,可以参考Docker 镜像加速器-博客-云栖社区-阿里云。pull完成即可使用。如果在这个过程当中发生一些错误无法pull完整,你需要在其它机器上拉取后导出,再导入此机器了,详情请搜索Docker load功能。
四、运行TensorFlow Serving Docker
1. 直接启动
TensorFlow Serving官网有详细的教程,这里总结了一些开箱即用的经验,细节后面可以慢慢阅读官网教程。完成镜像的拉取后,在命令行中输入以下命令即可启动TensorFlow Serving:
sudo nvidia-docker run -p 8500:8500 \
--mount type=bind,source=/home/huzhihao/projects/EAST/models,target=/models \
-t --entrypoint=tensorflow_model_server tensorflow/serving:latest-gpu \
--port=8500 --per_process_gpu_memory_fraction=0.5 \
--enable_batching=true --model_name=east --model_base_path=/models/east_model &这里解释一下各个参数的意义:
-p 8500:8500 :指的是开放8500这个gRPC端口。
--mount type=bind, source=/your/local/model, target=/models:把你导出的本地模型文件夹挂载到docker container的/models这个文件夹,tensorflow serving会从容器内的/models文件夹里面找到你的模型。
-t --entrypoint=tensorflow_model_server tensorflow/serving:latest-gpu:如果使用非devel版的docker,启动docker之后是不能进入容器内部bash环境的,--entrypoint的作用是允许你“间接”进入容器内部,然后调用tensorflow_model_server命令来启动TensorFlow Serving,这样才能输入后面的参数。紧接着指定使用tensorflow/serving:latest-gpu 这个镜像,可以换成你想要的任何版本。
--port=8500:开放8500这个gRPC端口(需要先设置上面entrypoint参数,否则无效。下面参数亦然)
--per_process_gpu_memory_fraction=0.5:只允许模型使用多少百分比的显存,数值在[0, 1]之间。
--enable_batching:允许模型进行批推理,提高GPU使用效率。
--model_name:模型名字,在导出模型的时候设置的名字。
--model_base_path:模型所在容器内的路径,前面的mount已经挂载到了/models文件夹内,这里需要进一步指定到某个模型文件夹,例如/models/east_model指的是使用/models/east_model这个文件夹下面的模型。
更多的tensorflow_model_server参数意义,可以看以下官方介绍:
usage: tensorflow_model_server
Flags:
--port=8500 int32 Port to listen on for gRPC API
--rest_api_port=0 int32 Port to listen on for HTTP/REST API. If set to zero HTTP/REST API will not be exported. This port must be different than the one specified in --port.
--rest_api_num_threads=160 int32 Number of threads for HTTP/REST API processing. If not set, will be auto set based on number of CPUs.
--rest_api_timeout_in_ms=30000 int32 Timeout for HTTP/REST API calls.
--enable_batching=false bool enable batching
--batching_parameters_file="" string If non-empty, read an ascii BatchingParameters protobuf from the supplied file name and use the contained values instead of the defaults.
--model_config_file="" string If non-empty, read an ascii ModelServerConfig protobuf from the supplied file name, and serve the models in that file. This config file can be used to specify multiple models to serve and other advanced parameters including non-default version policy. (If used, --model_name, --model_base_path are ignored.)
--model_name="default" string name of model (ignored if --model_config_file flag is set
--model_base_path="" string path to export (ignored if --model_config_file flag is set, otherwise required)
--file_system_poll_wait_seconds=1 int32 interval in seconds between each poll of the file system for new model version
--flush_filesystem_caches=true bool If true (the default), filesystem caches will be flushed after the initial load of all servables, and after each subsequent individual servable reload (if the number of load threads is 1). This reduces memory consumption of the model server, at the potential cost of cache misses if model files are accessed after servables are loaded.
--tensorflow_session_parallelism=0 int64 Number of threads to use for running a Tensorflow session. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty.
--ssl_config_file="" string If non-empty, read an ascii SSLConfig protobuf from the supplied file name and set up a secure gRPC channel
--platform_config_file="" string If non-empty, read an ascii PlatformConfigMap protobuf from the supplied file name, and use that platform config instead of the Tensorflow platform. (If used, --enable_batching is ignored.)
--per_process_gpu_memory_fraction=0.000000 float Fraction that each process occupies of the GPU memory space the value is between 0.0 and 1.0 (with 0.0 as the default) If 1.0, the server will allocate all the memory when the server starts, If 0.0, Tensorflow will automatically select a value.
--saved_model_tags="serve" string Comma-separated set of tags corresponding to the meta graph def to load from SavedModel.
--grpc_channel_arguments="" string A comma separated list of arguments to be passed to the grpc server. (e.g. grpc.max_connection_age_ms=2000)
--enable_model_warmup=true bool Enables model warmup, which triggers lazy initializations (such as TF optimizations) at load time, to reduce first request latency.
--version=false bool Display version2. 进入devel版镜像的容器内部启动
如果你使用的是devel版本,希望进入容器内部的终端配置自己想要的环境,我们使用以下命令进入容器:
sudo nvidia-docker run -it tensorflow/serving:latest-devel-gpu bash-it的意思是以交互的方式进入容器内部,镜像名后跟一个```bash```指的是进入容器的shell,运行后你就可以像在平常的ubuntu终端那样使用pip、apt等命令来设置你的定制环境了。如果想在容器内部启动TensorFlow Serving,就要运行以下命令:
tensorflow_model_server --port=8500 --rest_api_port=8501 \
--model_name=${MODEL_NAME} --model_base_path=${MODEL_BASE_PATH}/${MODEL_NAME}参数的意义跟上面直接启动章节给出的意义一样,可以看到,如果不进入容器,在命令中加入--entrypoint以及其它参数,就跟上面进入容器使用tensorflow_model_server命令的效果一样!当你想把本地文件夹里面的文件复制到容器内部的某个文件夹内,可以使用docker cp命令:
sudo docker cp /your/local/file YOUR_CONTAINER_ID:/your/container/dir这里的YOUR_CONTAINER_ID可以在你的容器命令行终端里面,root@后面接的一串英文数字组合就是你的container id,如root@dc238c481f14:,“dc238c481f14”就是容器id。
当你一切设置妥当后,此时如果直接exit退出容器会导致你所做的一切改动都会全部消失! 必须先commit一下你的新镜像,保存下来(注意以下命令不要在容器内部的shell执行,新开一个命令行):
sudo docker commit $(sudo docker ps --last 1 -q) YOUR_IMAGE_NAME:VERSION```YOUR_IMAGE_NAME:VERSION```就是你想改的镜像名:版本号了,完成后输入```sudo docker images```就能看到你的新镜像了,此时你就可以容器内部输入```exit```来退出你的容器。
有时候执行了一些挂在后台的tensorflow serving服务,即使你```exit```退出容器或者ctrl+c都不会杀死这个服务,如果你想杀死不想再用的后台应用,输入```sudo docker ps```来查看正在运行的容器,然后```sudo docker kill IMAGE_NAME```就可以杀死服务。
五、Client客户端
TensorFlow Serving启动后,我们需要用一个客户端来发送预测请求,跟以往请求不同的是,TensorFlow Serving使用的是gRPC协议,我们的客户端需要安装使用gRPC的API,以特定的方式进行请求以及接收结果。
安装
pip install tensorflow-serving-apiClient Demo
这里展示核心代码部分,完整的代码可以参看TensorFlow Serving官方mnist client示例。
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
def request_server(img_resized, server_url):
'''
用于向TensorFlow Serving服务请求推理结果的函数。
:param img_resized: 经过预处理的待推理图片数组,numpy array,shape:(h, w, 3)
:param server_url: TensorFlow Serving的地址加端口,str,如:'0.0.0.0:8500'
:return: 模型返回的结果数组,numpy array
'''
# Request.
channel = grpc.insecure_channel(server_url)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = "east" # 模型名称
request.model_spec.signature_name = "predict_images" # 签名名称
# "images"是你导出模型时设置的输入名称
request.inputs["images"].CopyFrom(
tf.contrib.util.make_tensor_proto(img_resized, shape=[1, ] + list(img_resized.shape)))
response = stub.Predict(request, 5.0) # 5 secs timeout
return np.asarray(response.outputs["score"].float_val)TensorFlow Serving返回protobuf格式的结果,不是json,无法使用json来解析结果,你可以打印出变量```response```的值,大概会是这样的格式:
outputs {
key: "score"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
dim {
size: 200
}
dim {
size: 200
}
dim {
size: 5
}
}
float_val: 160.14822387695312
float_val: 112.23966217041016
float_val: 95.28953552246094
float_val: 130.53846740722656
......上面示例中```response.outputs["score"].float_val```会返回一个行向量如```array([160.14822387695312, 112.23966217041016, 95.28953552246094, ......])```,不会保留真实的shape,如果要把它reshape成原来的shape,如上面显示的dim:(1, 200, 200, 5),需要使用```tf.make_ndarray()```:
return tf.make_ndarray(response.outputs["score"])六、Tornado Web服务
TensorFlow模型的计算图,一般输入的类型都是张量,你需要提前把你的图像、文本或者其它数据先进行预处理,转换成张量才能输入到模型当中。而一般来说,这个数据预处理过程不会写进计算图里面,因此当你想使用TensorFlow Serving的时候,需要在客户端上写一大堆数据预处理代码,然后把张量通过gRPC发送到serving,最后接收结果。现实情况是你不可能要求每一个用户都要写一大堆预处理和后处理代码,用户只需使用简单POST一个请求,然后接收最终结果即可。因此,这些预处理和后处理代码必须由一个“中间人”来处理,这个“中间人”就是Web服务。
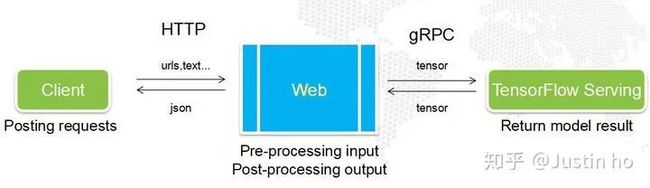
我们使用Tornado框架来搭建我们的Web服务,Tornado是一个支持异步非阻塞的高性能Web框架,可以接收多个用户的并发请求,然后向TensorFlow Serving并发请求结果,并在其中承担所有的数据预处理、后处理任务。
一个典型的Tornado app的伪代码:
class MainHandler(tornado.web.RequestHandler):
async def post(self):
# 从客户端post过来的信息中解析出图片urls
urls = self.request.body.decode()
urls = json.loads(urls)
img = await fetch_urls(urls) # 异步下载图片url函数
img = preprocessing(img) # 预处理图片函数
result = await inference(img) # 调用tfserving预测函数
result = postprocessing(result) # result后处理函数
self.finish(result) # 返回信息给客户端
def make_app():
return tornado.web.Application([
(r"/", MainHandler)
])
if __name__ == '__main__':
app = make_app()
app.listen(8131) # tornado服务端监听端口
tornado.ioloop.IOLoop.current().start()上面这个代码涉及一些自定义的函数这里没有给出,但可以根据上面的注释大概了解Tornado构建的元素以及大致流程。网上大部分教程都是基于5.1.1以下的版本,这类教程用到大量的函数包装器,但包装器的写法在5.1.1版本以后都准备弃用,取而代之的是使用```async```、```await```这类方式来定义异步函数。
建议Tornado初学者直接学习Tornado官网的文档:Tornado Web Server - Tornado 5.1.1 documentation,网上大部分教程都不适合新版(5.1.1以上)的API,会引起混乱,官网提供的异步爬虫:Queue example - a concurrent web spider - Tornado 5.1.1 documentation案例比较实用。如果你还未了解“同步与异步”、“阻塞与非阻塞”这些概念,建议你通过阅读莫烦的多进程多线程:Threading 多线程教程系列 | 莫烦Python、廖雪峰的进程和线程以及异步IO章节了解这些概念,清晰易懂。另外,这里有一个非常棒的github项目,非常标准地使用TensorFlow Serving部署,流程十分清晰,建议大家参考:pakrchen/text-antispam
七、总结
由于TensorFlow Serving、TensorRT Infer Serving等等框架的出现,模型的部署、维护越来越方便,使得工程师更加专注于模型的研究上,大大缩短了研发-部署的流程。
![]()
![]()
![]()
![]()