多目标跟踪中的一些后处理方法汇总
多目标跟踪中的一些后处理方法汇总
1.轨迹插值
1.1 线性插值
⚡️ 原理: 对于一段中间突然中断的轨迹(中断的帧数一般得小于20帧,才会进行线性插值),其消失期间的轨迹大致可描述为轨迹消失时的位置与轨迹再次出现时的位置与消失时间的比值,公式可描述为:
z ^ t = z t 1 + t − t 1 t 2 − t 1 ( z t 2 − z t 1 ) , t 1 < t < t 2 \hat{\mathbf{z}}_{t}=\mathbf{z}_{t_{1}}+\frac{t-t_{1}}{t_{2}-t_{1}}\left(\mathbf{z}_{t_{2}}-\mathbf{z}_{t_{1}}\right), t_{1}
其中 z t 1 = [ x 1 , y 1 , x 2 , y 2 ] \mathbf{z}_{t_{1}}=[x_1, y_1, x_2, y_2] zt1=[x1,y1,x2,y2]表示轨迹消失时所在图像中的位置, z t 2 \mathbf{z}_{t_{2}} zt2表示轨迹再次出现时所在图像中的位置, z ^ t \hat{\mathbf{z}}_{t} z^t则表示轨迹消失的中间时刻 t t t由线性插值估计出来的位置。
一般而言要求,中断的轨迹长度不能超过20帧( t 2 − t 1 ≤ 20 t_2 - t_1 \le 20 t2−t1≤20),否则线性插值会带来严重的位置估计误差。
1.2 高斯平滑插值
⚡️ 原理: 假定目标的运动轨迹服从高斯过程,且每个已知的运动位置均会存在观测噪声(观测噪声服从高斯分布),那么其中断时刻 t t t的预测值就可以通过以下等式进行估计:
y ˉ ∗ = K ∗ K − 1 y var ( y ∗ ) = K ∗ ∗ − K ∗ K − 1 K ∗ T \begin{array}{c} \bar{y}_{*}=K_{*} K^{-1} \mathbf{y} \\ \operatorname{var}\left(y_{*}\right)=K_{* *}-K_{*} K^{-1} K_{*}^{\mathrm{T}} \end{array} yˉ∗=K∗K−1yvar(y∗)=K∗∗−K∗K−1K∗T
具体推导过程可参看:高斯过程回归
具体到轨迹的边界框估计方面,一般是以目标的中心点(构建两个高斯过程回归器,目标的 w , h w,h w,h固定)或者左上角点和宽高(宽高也要预测)分别预测坐标的时序位置。此外一般在使用高斯过程回归的时候都输入的观测坐标,不仅有轨迹未中断时刻的位置,也有轨迹中断后又线性补帧估计的位置信息,整合这些所有的信息之后再对某一个中断时刻 t t t的位置进行估计。
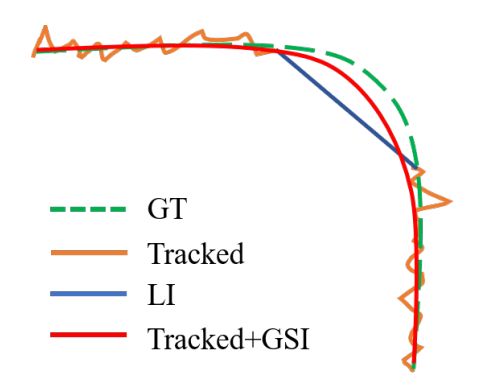
1.3 代码实现
OC-SORT:https://github.com/noahcao/OC_SORT/blob/master/tools/gp_interpolation.py
在
tools目录内有线性插值和高斯平滑插值,GSI只估计目标的中心点,目标宽高恒定。
StrongSORT:https://github.com/dyhBUPT/StrongSORT/blob/master/GSI.py
估计左上角点和宽高
2.轨迹分裂
⚡️ 原理:面对一段身份信息不一致的轨迹序列,采用轨迹的外观特征(主要)或者运动特征(方向、相对位置变化等,次要)将不合理的轨迹序列(通常是存在ID switch)断开成几段身份信息一致的小轨迹段。
一般来说轨迹分裂与缝合都是一起出现的。
2.1 非参数化的方法
这类方法主要是通过计算轨迹前后帧外观特征的相似度的突变时刻找出合理的轨迹断点,或者分析当前帧与之前多帧轨迹外观特征的相似度从而确定当前帧是否存在ID跳变。但是这种非参数化的方法面对目标尺度突然变化时(比如从站着变成蹲着)也会发生较大的相似度下降,引起断点误判。
{ t ∣ Max i = 1 , … , N { cosim ( s t i , s t ) } < T h r s } \{t| \operatorname{Max}_{i=1,\dots,N}\{ \operatorname{cosim}(s_{t_i}, s_t) \} < Thr_s \} {t∣Maxi=1,…,N{cosim(sti,st)}<Thrs}
其中, s t s_t st表示 t t t时刻轨迹的外观特征, cosim \operatorname{cosim} cosim表示外观特征向量之间的余弦相似度。
2.2 参数化的方法
2.2.1 Split and Connect: A Universal Tracklet Booster for Multi-Object Tracking
arXiv: https://arxiv.org/abs/2105.02426
⚡️ 处理流程:文中定义了一个基于特征提取和轨迹断点预测的spliter,具体结构是一个堆叠的一维卷积block+两个全连接,网络的输入是一个T帧轨迹段的bbox和embedding特征向量,shape为 ( 2048 + 4 ) × 1 × T (2048+4)\times 1\times T (2048+4)×1×T;输出为两个 1 × ( T − 1 ) 1\times (T-1) 1×(T−1)的帧间断点概率值阈值向量 m ^ \widehat{\boldsymbol{m}} m 和自适应高斯平滑方差向量 σ ^ \widehat{\boldsymbol{\sigma}} σ 。
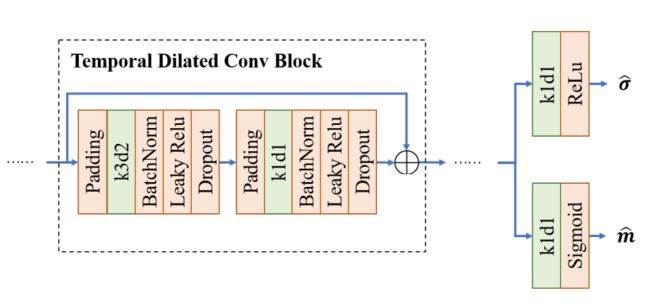

然后使用高斯平滑后的帧间断点标签监督网络进行学习,损失计算公式如下:
L s = ∑ t ( m ^ t − min ( ∑ τ m τ ∗ exp ( − ( τ − t ) 2 σ ~ τ 2 ) , 1 ) ) 2 其中, σ ~ = max ( min ( σ ^ , 10 ) , ϵ ) , ϵ = 0.001 \mathcal{L}_{s}=\sum_{t}\left(\hat{\boldsymbol{m}}_{t}-\min \left(\sum_{\tau} \boldsymbol{m}_{\tau}^{*} \exp \left(-\frac{(\tau-t)^{2}}{\tilde{\boldsymbol{\sigma}}_{\tau}^{2}}\right), 1\right)\right)^{2} \\ 其中,\tilde{\boldsymbol{\sigma}}=\max (\min (\hat{\boldsymbol{\sigma}}, 10), \epsilon), \epsilon=0.001 Ls=t∑(m^t−min(τ∑mτ∗exp(−σ~τ2(τ−t)2),1))2其中,σ~=max(min(σ^,10),ϵ),ϵ=0.001
模型训练的话就是通过一个简单的IoU跟踪器在带有ID信息的、bbox随机抖动的(稍微偏移变换一点儿)的GT框上进行不同关联阈值的关联,得到轨迹,然后根据轨迹中ID信息的变化情况确定轨迹的标签并进行训练。
感觉参数化模型训练的方法效果要比根据直观的相似度阈值进行人工判定要有效且可靠一些,但是可惜的是该方法代码没开源。
3. 轨迹缝合
3.1 非参数化的方法
⚡️ 流程:主要还是通过两个轨迹段外观特征的相似度击中(大于阈值)的次数,以及从轨迹开始与终止的时刻是否合理(一段轨迹的开始时间应该在另一段轨迹终止时间的一定范围内)。
3.1.1 SportsTrack 技术方案
技术方案: https://deeperaction.github.io/results/track3_1st.pdf
GitHub: https://github.com/vghost2008/sportstrack
⚡️ **处理流程:**首先跟踪轨迹的外观特征相似度的方差确定轨迹是stable轨迹还是unstable轨迹,对于stable的两个分别有M帧和N帧的轨迹段,如果出现的时间上合理,则计算两段轨迹的相似度矩阵 simmatrix ∈ R M × N \text{simmatrix} \in R^{M \times N} simmatrix∈RM×N,在 M × N M \times N M×N个相似度值中如果高于阈值的值达到了 ( M × N ) / 2 (M \times N)/2 (M×N)/2个则认为两段轨迹拥有相同的身份id应该予以合并。
3.2 参数化的方法
3.2.1 Split and Connect: A Universal Tracklet Booster for Multi-Object Tracking
arXiv: https://arxiv.org/abs/2105.02426
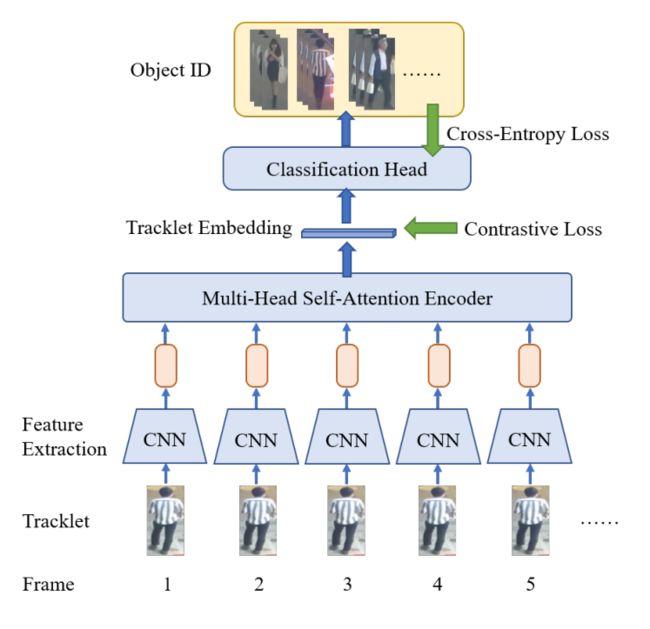
⚡️ 处理流程:使用transformer来聚合得到轨迹段的时序信息,然后通过分类头分类轨迹所属ID,交叉熵损失和triplet loss用于监督模型学出更具判别性的特征。最后去掉分类头,仅用经过transformer编码后的特征作为轨迹的特征嵌入,轨迹段之间使用L2距离(满足合理的轨迹出现和终止时间要求)即可判定是否属于同一段轨迹。
3.2.2 GIAOTracker: A comprehensive framework for MCMOT with global information and optimizing strategies in VisDrone 2021
arXiv: https://arxiv.org/abs/2202.11983
⚡️ 处理流程: 首先使用了一种融合全局加局部外观特征编码的特征提取网络,然后仍然使用Transformer聚合轨迹的时序特征信息(当作轨迹的外观特征表示),特征嵌入的损失方面只用了triplet loss进行监督,训练完成之后使用外观度量+轨迹段间隔度量+轨迹bbox的距离度量(具体如何度量后面两种不同的轨迹距离文章并没有详细介绍,猜测可能是前一段轨迹最后的bbox位置与后一段轨迹开始的Bbox位置之间的距离)判定两段轨迹是否为同一身份ID。
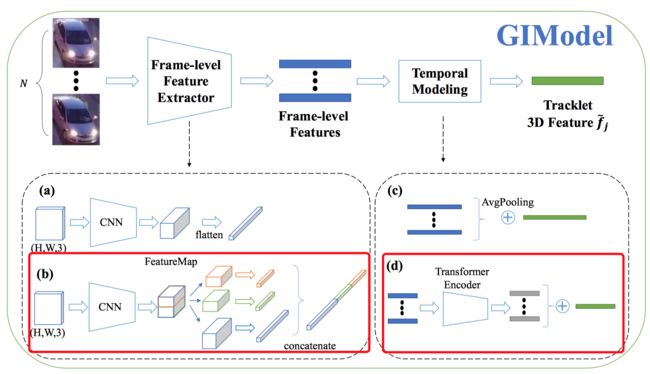
3.2.3 StrongSORT: Make DeepSORT Great Again
arXiv:https://arxiv.org/abs/2202.13514
GitHub: https://github.com/dyhBUPT/StrongSORT
⚡️ 处理流程:和前面的GIAOTracker是同一作者,在这篇文章中作者又提出了新的轨迹缝合策略:直接建模轨迹的出现帧与位置对轨迹进行时序建模。具体而言作者仅用N帧轨迹位置描述一个轨迹段 T ∗ = { f k , x k , y k } k = 1 N T_{*}=\left\{f_{k}, x_{k}, y_{k}\right\}_{k=1}^{N} T∗={fk,xk,yk}k=1N ,其中 f k f_k fk表示目标k次出现时的帧序号, x k , y k x_k, y_k xk,yk分别表示目标k次出现时所在图像的位置。由此形成一个 1 × N × 3 1 \times N \times 3 1×N×3的伪图像,然后运用 7 × 1 7 \times 1 7×1的卷积融合轨迹时序信息,再利用 1 × 3 1 \times 3 1×3的卷积融合不同通道的特征,最后对特征进行全局平均池化以获取该轨迹段的特征表示并与其它时空关系合理(帧间隔不太远,位置间隔不太远)的轨迹段进行concat融入MLP网络评判相似度。
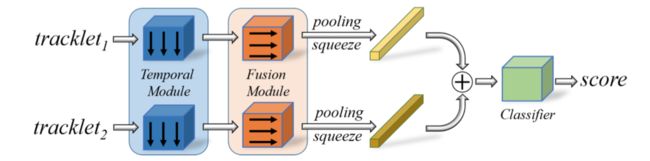
训练数据方面,作者从GT轨迹中以1:3的比例随机筛选截取部分轨迹段当作正负样本,同时引入了时序扰动和空间位置扰动(在帧序号和出现位置加上一定偏差),训练损失为交叉熵损失函数。
4. 模型集成
4.1 融合多个检测器的结果
汇总对个检测器的检测结果,然后使用NMS(或者SoftNMS)进行高度重叠框的滤除,滤除后的检测结果作为当前帧的检测框送入跟踪器。
4.2 Model soup
一种类似EMA机制的模型集成方法,之前的集成学习需要一次前向传播多个不同超参数的模型,得到多个预测结果,然后进行投票,而model soup直接将多个不同超参的模型对应的参数权重进行平均融合,最后得到一个结合不同超参数的模型,只执行一次前向传播。(感觉作用不大)
4.3 融合多个跟踪器的结果
4.3.1 EnsembleMOT: A Step towards Ensemble Learning of Multiple Object Tracking
arXiv: https://arxiv.org/abs/2210.05278
- 提出一种融合多个跟踪器跟踪结果的方法(以前都是融合多个检测器,无法从实例级角度完成轨迹的去重),具体操作是:有两段具有重叠时间段的轨迹 { T i , t i 0 , t i 1 } \left\{T_{i}, t_{i}^{0}, t_{i}^{1}\right\} {Ti,ti0,ti1}和 { T j , t j 0 , t j 1 } \left\{T_{j}, t_{j}^{0}, t_{j}^{1}\right\} {Tj,tj0,tj1},假设 t i 0 ≤ t j 0 ≤ t i 1 ≤ t j 1 t_{i}^{0} \leq t_{j}^{0} \leq t_{i}^{1} \leq t_{j}^{1} ti0≤tj0≤ti1≤tj1,计算重叠时间段内两段轨迹bbox框的IoU( s I o U i , j = { IoU ( b i t , b j t ) } t = t j 0 t = t i 1 s I o U_{i, j}=\left\{\operatorname{IoU}\left(b_{i}^{t}, b_{j}^{t}\right)\right\}_{t=t_{j}^{0}}^{t=t_{i}^{1}} sIoUi,j={IoU(bit,bjt)}t=tj0t=ti1), 并统计IoU超过阈值的帧数 inter i , j = ∣ { i o u > T h r s ∣ i o u ∈ s I o U i , j } ∣ \text { inter }_{i, j}=\left|\{i o u>T h r_{s} \mid i o u \in s I o U_{i, j}\right\}| inter i,j=∣{iou>Thrs∣iou∈sIoUi,j}∣, 最后通过这计算超过阈值帧数所占较短轨迹帧数的比例 stIoU i , j = inter i , j union i , j , union i , j = min ( t i 1 − t i 0 , t j 1 − t j 0 ) \text { stIoU }_{i, j}=\frac{\text { inter }_{i, j}}{\text { union }_{i, j}}, \ \text { union }_{i, j}=\min \left(t_{i}^{1}-t_{i}^{0}, t_{j}^{1}-t_{j}^{0}\right) stIoU i,j= union i,j inter i,j, union i,j=min(ti1−ti0,tj1−tj0),确定两段轨迹的相似度实现轨迹去重。对于确定的身份ID相同的轨迹,在重合时间段使用长轨迹的bbox做为跟踪的位置。
- 提出帧内bbox-level NMS,使用轨迹段长度作为NMS的排序目标,从长轨迹的bbox开始,剔除掉与其IoU大于0.7的较短轨迹的bbox;
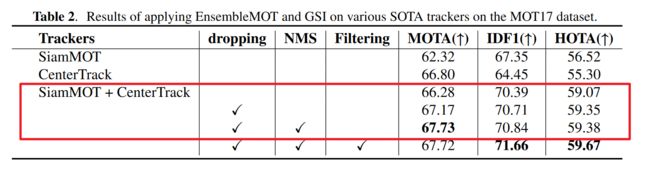
从消融实验来说这两部分还是提升蛮大的(第三行表示使用重叠轨迹段两个bbox的平均值作为跟踪结果)。
5. 相机运动补偿与卡尔曼滤波的一些改进
不算是后处理,可以计算之后存起来或者在线计算
⚡️流程:简单来说就是根据相邻两帧之间的参考对照点(一般是图像中的静止物体)的相关位置关系,解算岀相邻帧之间由于相机视角变换带来的相对位置变化,即求解一个仿射变换矩阵用于补偿因为相机运动的导致卡尔曼滤波不准的情况。下面列岀可以使用的相机运动补偿代码实现:
BoT-SORT:https://github.com/NirAharon/BoT-SORT/blob/main/tracker/gmc.py
融合了ECC, ORB, SIFT等好几种不同的相机运动补偿方式。
StrongSORT:https://github.com/dyhBUPT/StrongSORT/blob/master/others/ecc.py
对卡尔曼滤波的改进在上述两个方法均有涉及,其中StrongSORT依据轨迹置信度确定观测噪声的卡尔曼滤波;BoT-SORT则将预测的状态向量改为了预测轨迹的中心点位置+宽高,具体请参看这两篇论文。
BoT-SORT:https://arxiv.org/abs/2206.14651
StrongSORT: https://arxiv.org/abs/2202.13514