TensorFlow搭建CNN实现时间序列预测(风速预测)
目录
- I. 数据集
- II. 特征构造
- III. 一维卷积
- IV. 数据处理
-
- 1. 数据预处理
- 2. 数据集构造
- V. CNN模型
-
- 1. 模型搭建
- 2. 模型训练及表现
- VI. 源码及数据
时间序列预测系列文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch中利用LSTMCell搭建多层LSTM实现时间序列预测
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
- PyTorch时间序列预测系列文章总结(代码使用方法)
- TensorFlow搭建LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量时间序列预测(负荷预测)
- TensorFlow搭建双向LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- TensorFlow搭建ANN实现时间序列预测(风速预测)
- TensorFlow搭建CNN实现时间序列预测(风速预测)
- TensorFlow搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
I. 数据集
数据集为Barcelona某段时间内的气象数据,其中包括温度、湿度以及风速等。本文将利用CNN来对风速进行预测。
II. 特征构造
对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响。因此,我们根据前24个时刻的风速+其余气象数据来预测下一时刻的风速。
III. 一维卷积
我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部操作,通过一定大小的卷积核作用于局部图像区域获取图像的局部信息。图像中不同数据窗口的数据和卷积核做inner product(内积)的操作叫做卷积,其本质是提纯,即提取图像不同频段的特征。
上面这段话不是很好理解,我们举一个简单例子:
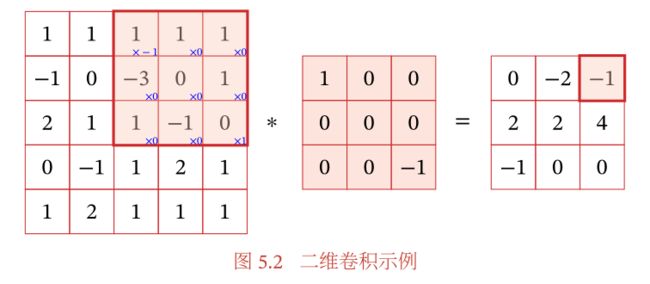
假设最左边的是一个输入图片的某一个通道,为 5 × 5 5 \times5 5×5,中间为一个卷积核的一层, 3 × 3 3 \times3 3×3,我们让卷积核的左上与输入的左上对齐,然后整个卷积核可以往右或者往下移动,假设每次移动一个小方格,那么卷积核实际上走过了一个 3 × 3 3 \times3 3×3的面积,那么具体怎么卷积?比如一开始位于左上角,输入对应为(1, 1, 1;-1, 0, -3;2, 1, 1),而卷积层一直为(1, 0, 0;0, 0, 0;0, 0, -1),让二者做内积运算,即1 * 1+(-1 * 1)= 0,这个0便是结果矩阵的左上角。当卷积核扫过图中阴影部分时,相应的内积为-1,如上图所示。
因此,二维卷积是将一个特征图在width和height两个方向上进行滑动窗口操作,对应位置进行相乘求和。
相比之下,一维卷积通常用于时序预测,一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。 如下图所示:
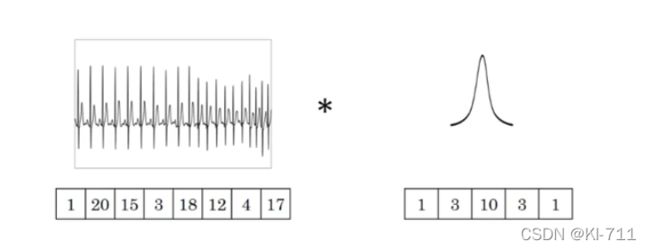
原始时序数为:(1, 20, 15, 3, 18, 12. 4, 17),维度为8。卷积核的维度为5,卷积核为:(1, 3, 10, 3, 1)。那么将卷积核作用与上述原始数据后,数据的维度将变为:8-5+1=4。即卷积核中的五个数先和原始数据中前五个数据做卷积,然后移动,和第二个到第六个数据做卷积,以此类推。
IV. 数据处理
1. 数据预处理
数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一化处理。文本数据如下所示:
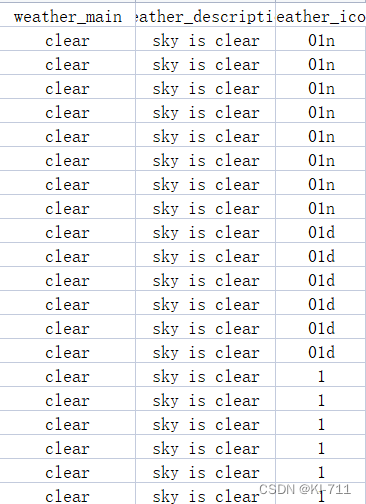
经过转换后,上述各个类别分别被赋予不同的数值,比如"sky is clear"为0,"few clouds"为1。
def load_data():
df = pd.read_csv('Barcelona/Barcelona.csv')
df.drop_duplicates(subset=[df.columns[0]], inplace=True)
df.drop([df.columns[0], df.columns[1]], axis=1, inplace=True)
# weather_main
listType = df['weather_main'].unique()
df.fillna(method='ffill', inplace=True)
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_main'] = df['weather_main'].map(dic)
# weather_description
listType = df['weather_description'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_description'] = df['weather_description'].map(dic)
# weather_icon
listType = df['weather_icon'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_icon'] = df['weather_icon'].map(dic)
# print(df)
return df
2. 数据集构造
利用前24个小时的风速+其他变量来预测下一时刻的风速:
数据被划分为三部分:Dtr、Val以及Dte,Dtr用作训练集,Val用作验证集,Dte用作测试集,模型训练返回的是验证集上表现最优的模型。
V. CNN模型
1. 模型搭建
CNN模型搭建如下:
class CNN(keras.Model):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = Sequential()
self.conv1.add(layers.Conv1D(64, 2, activation='relu'))
self.conv1.add(layers.MaxPool1D(pool_size=2, strides=1))
self.conv2 = Sequential()
self.conv2.add(layers.Conv1D(128, 2, activation='relu'))
self.conv2.add(layers.MaxPool1D(pool_size=2, strides=1))
self.Linear1 = layers.Dense(B * 50, activation='relu')
self.Linear2 = layers.Dense(1)
def call(self, x):
x = self.conv1(x) # (15, 24, 15)--->(15, 22, 64)
# print(x.shape)
x = self.conv2(x) # (15, 22, 64)--->(15, 20, 128)
x = tf.reshape(x, [x.shape[0], -1])
x = self.Linear1(x)
x = self.Linear2(x)
return x
卷积层定义如下:
layers.Conv1D(64, 2, activation='relu')
layers.Conv1D(128, 2, activation='relu')
一维卷积的原始定义为:
tf.keras.layers.Conv1D(
filters, kernel_size, strides=1, padding='valid',
data_format='channels_last', dilation_rate=1, groups=1,
activation=None, use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs
)
这里filters的概念相当于自然语言处理中的embedding,这里输入通道数为15,表示风速+14个环境变量,输出filters设置为64,卷积核大小为2。
原数数据的维度为24,即前24小时的风速+14种气象数据。卷积核大小为2,根据前文公式,原始时序数据经过卷积后维度为:
24 - 2 + 1 = 23
然后经过一个最大池化变成22,然后又是一个卷积层+池化层,变成20。
这里需要注意的是,PyTorch中要求输入数据的shape为(batch_size, input_size, seq_len),而TensorFlow中为(batch_size, seq_len, input_size),也就是说TensorFlow中不需要对原始数据进行维度交换操作。
2. 模型训练及表现
CNN在Dte上的表现如下表所示:
| MAE | RMSE |
|---|---|
| 1.06 | 1.41 |
VI. 源码及数据
后面将陆续公开~