神经网络课程笔记-李沐教程
梯度下降:
通过不断沿着反梯度方向更新参数求解
小批量随机梯度下降是深度学习默认的求解方法
两个重要的超参数
批量大小和学习率
improt random:
random 包主要用来生成随机数
X = torch.normal(0, 1, (num_examples, len(w)))
生成一个矩阵,这个矩阵中的每一个元素都是均值为0、标准差为1的数。矩阵的行数为num_examples,列为len(w)即w向量的长度。其中,(num_examples,len(w))可以替换为一个数,代表生成一个一维向量,这个数就是向量所含元素的个数。
torch.matmul(X, w)
进行矩阵的乘法
y.reshape((-1, 1))
将矩阵y改变形状,这里(a,b)前面的数(a)表示行数,后面的数(b)表示列数。此例中即为将y的行数不变列数变为1。-1作为参数即表示这个维度的大小不发生改变。
d2l.set_figsize()
表示设置绘制图像的大小,可以进行传参,如果没有进行传参则表示使用默认参数
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);
d2l.plt.scatter 函数表示绘制散点图,需要输入两个参数作为横纵坐标。
其中feature[:,(1)]表示feature的所有行、第二列组成的一个向量组。即feature的第二列全部元素。.detach()是一个分割函数,.numpy表示将数组转换成numpy的格式。作为横坐标
同理label.detach().numpy()表示label向量进行转换成numpy的格式输出,作为纵坐标。这句代码表示绘制feature的第二列(即第二个特征)与标签之间的散点图
生成器对象(类)、迭代器对象(类)、可迭代对象(类)
迭代器类型:类中定义了__iter__和__next__两个方法;__iter__方法返回对象本身—self,__next__返回下一个数据,如果没有数据了抛出一个stopIteration的异常。下面是模拟创建的一个迭代器类
迭代器对象通过next取值,如果取值结束则自动抛出StopIteration
for循环内部在循环时,先执行__iter__方法,获取一个迭代器对象,然后不断执行__next__取值(有异常stopIteration则终止循环)

定义一个函数,如果这个函数中存在yield,那么这个函数就是生成器函数。生成器也是一种特殊的迭代器——其符合迭代器的定义

可迭代对象(类)——只含有__iter__方法,不含__next__方法,且__iter__方法返回的是一个迭代器对象;迭代器类(对象)和可迭代类(对象)都可以使用for来进行循环,因为其__iter__方法返回的都是一个迭代器对象。下一步都是调用返回的这个迭代器对象的__next__方法。

一般都是将迭代器类(对象)、可迭代类(对象)进行混合使用: IT()是一个迭代器类,Foo()是一个可迭代类,Foo()的__iter__方法返回的是一个迭代器对象IT。

range()函数其实是返回一个可迭代对象,dir()函数返回的是这个对象包含的方法。V1只含有__iter__,而没有__next__方法,V1.__iter__方法的返回值V2内含有__iter__和__next__方法。说明V2是一个迭代器对象,而V1是一个可迭代对象。可以对V2执行__next__以获取返回值。

实现一个自己的range(),类似于range()内部的实现机制。使用的是可迭代对象和生成器。
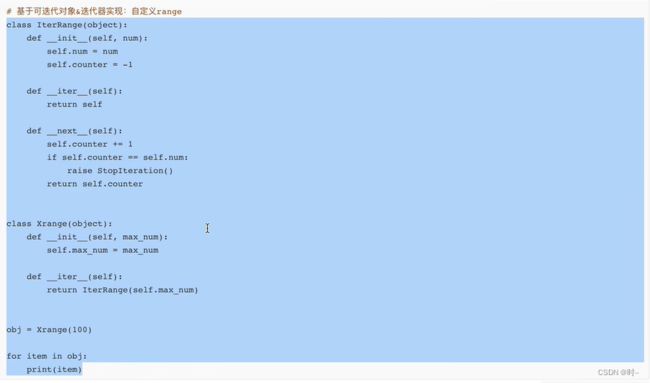
Foo类的__iter__方法返回的是一个生成器对象,下面是使用生成器进行for循环。

使用生成器实现range()

常见的数据类型中:列表\元组、字典、集合等常见的数据类型都是可迭代对象。

可通过判断对象是否属于Iterator和Iterable这两个类,判断是否是 迭代器/可迭代对象
isinstance()是 Python 中的一个内置函数,它用于检查一个对象是否是指定类型的实例。该函数接受两个参数:要检查的对象和要检查的类型。它返回一个布尔值,表示检查的对象是否是指定类型的实例。

indices = list(range(num_examples))
创建一个内容为从0到num_example - 1的列表,保存在变量indices中。
random.shuffle(indices)
将这个列表的排序打乱
列表的用法——indices[i: min(i + batch_size, num_examples)]
[ ]一般用在列表中,列表可以理解为C语言中的数组,只不过列表里面的数据类型不固定,可以由字符串、浮点数、整数组成。上面这句话的意思是:
1、索引indices中的indices[i] 到 indices[i + batch_size - 1]组成一个新的列表(i + indices - 1小于 num_examples - 1)
2、索引indices中的indices[i] 到 indices[num_examples - 1]组成一个新的列表(i + indices - 1大于 num_examples - 1)
requires_grad参数:
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True) 中的require_grand = True:当设置require_grad=True时,这个张量的梯度就会被记录。这意味着我们可以对这个张量执行操作,然后使用.backward()方法来自动计算梯度,并将其保存在.grad属性中。如果我们不设置require_grad=True,则不会记录梯度,无法进行梯度下降训练。
优化算法:
线性回归有解析解但是其他的模型却没有,没有解析解的模型一般使用 小批量随机梯度下降 的算法进行求解。
线性回归的从零开始实现——jupyter中的 8-3 wsy部分包含一些自己所更新的笔记
在这里记录一些用到的函数和方法,具体的每节课都有做笔记
torch.zeros()
PyTorch 中的一个函数,用于创建一个全部元素为 0 的张量(tensor)。
它的参数包括:
- size:张量的形状,由多个整数指定,如 [2, 3] 表示 2x3 的二维张量。
- dtype:张量的数据类型,支持常见的数值类型,如 float32、int64 等。
- device:张量的设备,可以是 CPU 或 GPU,默认为 CPU。
- requires_grad:是否需要求导,默认为 False。
x = torch.zeros(2, 3, dtype=torch.float32, device="cuda")
该代码创建了一个 2x3 的张量,数据类型为 float32,并分配在 CUDA 设备上。
data.DataLoader(dataset, batch_size, shuffle=is_train)
data.DataLoader() 是 PyTorch 中的一个函数,用于将给定的数据集(dataset)按照批次(batch_size)加载。如果设定 shuffle=is_train,则会在训练时(is_train=True)将数据集随机打乱。简单来说,这句代码的作用是将给定的数据集按批次加载,如果在训练时则随机打乱数据集。
detach()函数
detach() 是一个函数,它可以在 TensorFlow 中用来分离给定张量的计算图,使得该张量不再参与计算图中的计算。这意味着,对于被分离的张量,TensorFlow 将不会跟踪它的值,也不会计算它的梯度。
torch.matmul()——eg:torch.matmul(X, w)
torch.matmul 是 PyTorch 中的矩阵乘法函数。它接受两个矩阵作为输入,并返回它们的乘积。在数学表示法中,假设第一个矩阵为 A,第二个矩阵为 B,则它们的乘积为 A * B。它的作用与 Numpy 中的 np.matmul 函数相似。
torch.normal()——eg:torch.normal(0, 0.01, y.shape)
torch.normal() 是 PyTorch 中的一个函数,它可以根据指定的均值和标准差从正态分布中随机抽取张量元素。它的完整语法为:torch.normal(mean=0.0, std=1.0, out=None)其中,mean 表示所抽取的元素的均值,std 表示所抽取的元素的标准差,out 表示所抽取的元素的输出张量。例如,假设我们想从一个均值为 0,标准差为 1的正态分布中抽取 10 个元素。我们可以使用以下代码:x = torch.normal(mean=0.0, std=1.0, size=(10,))这将生成一个包含 10 个元素的张量 x。
l.sum().backward()
这句代码是在进行梯度反向传播,可以将它简单理解为计算一个张量的梯度。具体来说,它包含了三个部分:
- l.sum():这是一个张量操作,表示对 l 中所有元素求和,生成一个标量(scalar)。
- .backward():这是一个自动求导(autograd)函数,它可以根据计算图自动计算梯度。
- l.sum().backward():整个代码表示计算 l 中所有元素的梯度,并将梯度反向传播到 l 的所有直接依赖节点,更新这些节点的梯度值。
这句代码中的 l 是一个PyTorch的张量(tensor),包含多个数字。.sum() 是对 l 中所有数字求和,并将结果作为一个新的张量返回。最后,.backward() 是反向传播的一部分,用于计算张量的梯度。在这句代码中,我们首先将 l 中的所有数字求和,然后调用.backward() 来计算梯度。这个梯度将作为结果被返回,并可以用于训练模型。
nn.Sequential(from torch import nn)
nn.Sequential() 是 PyTorch 深度学习库中的一个函数,它接收一个包含多个神经网络层的序列作为参数,并将它们连接起来,构建一个大的神经网络模型。
net[0].weight.data.normal_(0, 0.01)
将网络的第一个图层的weight参数选中 net[0].weight;使用data.normal_(0,0.1) 方法将这个参数的值替代为均值为0、方差为1的正态分布的随机值。
net[0].bias.data.fill_(0)
同理使用data.fill_(0)将bias参数填充为0。
torch.optim.SGD(net.parameters(), lr=0.03) trainer.zero_grad() trainer.step()
调用封装完全的小批量梯度下降方法,可以用trainer.zero_grad()来讲梯度清零;也可以用trainer.step()来更新参数的值。