李沐深度学习笔记-04数据操作
前言
1.《动手学深度学习》https://zh-v2.d2l.ai/
2.记事本 https://github.com/d2l-ai/d2l-zh
3.数据操作和数据预处理
N维数组是机器学习和神经网络的主要数据结构
数据操作
数据操作实现
1.首先,要导入torch,他被称为PyTorch,但我们应该导入torch,而不是Pytorch。
张量表示一个数值组成的数组,这个数组可能有多个维度
import torch
x=torch.arange(12) #tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
x.shape #shape属性来访问张量的形状和张量中元素的总数
#torch.Size([12])
x.numel() #12
X=x.reshape(3,4) #要改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数
torch.zeros((2,3,4)) #创建2*3*4的全0三维数组
torch.ones((2,3,4)) #创建2*3*4的全1三维数组
torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]])
#tensor([[2, 1, 4, 3],
# [1, 2, 3, 4],
# [4, 3, 2, 1]])
torch.tensor([[[2,1,4,3],[1,2,3,4],[4,3,2,1]]]).shape #torch.Size([1, 3, 4])
x=torch.tensor([1.0,2,4,8])
y=torch.tensor([2,2,2,2])
x+y,x-y,x*y,x/y,x**y
'''(tensor([ 3., 4., 6., 10.]),
tensor([-1., 0., 2., 6.]),
tensor([ 2., 4., 8., 16.]),
tensor([0.5000, 1.0000, 2.0000, 4.0000]),
tensor([ 1., 4., 16., 64.]))'''
torch.exp(x)
#tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])

torch.cat(X,Y)把这两个元素合并在一起,dim=0,按列堆起来,dim=1,按行并排。
# dim = 0: 代表基于batchSize拼接
# dim = 1: 代表基于通道拼接
# dim = 2: 代表基于高拼接
# dim = 3: 代表基于宽拼接
#接上面
#按元素值进行判定
X==Y
#输出tensor([[False, True, False, True],
# [False, False, False, False],
# [False, False, False, False]])
X.sum() #求和
#tensor(66.)
即使形状不同,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作
a=torch.arange(3).reshape((3,1))
b=torch.arange(2).reshape((1,2))
a,b
#输出(tensor([[0],
# [1],
# [2]]),
# tensor([[0, 1]]))
a+b
#在a和b形状不一样的情况下,但是维度一样,都是二维数组,我们可以把a和b都复制成3*2的矩阵,这样就可以相加了。(广播机制)
#输出tensor([[0, 1],
# [1, 2],
# [2, 3]])
X[-1],X[1:3] #X[-1]取最后一行的元素,X[1:3]取第二三行的元素
X[1,2] #下标为(1,2)的元素
X[0:2,:]=12 #把第一二行的元素赋值为12
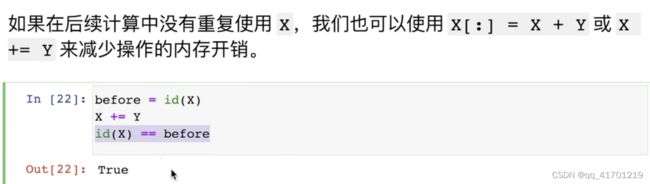
运行一些操作可能会导致为新结果分配内存(对一个很大的矩阵不要对他进行不断地赋值赋值)
before=id(Y)
Y=Y+X
id(Y)==before
#输出False,已经不是原来的地址了
#id告诉你object在python里面唯一的标识号
Z=torch.zeros_like(Y) #Z跟Y的shape和数据类型是一样的,但是所有的元素是0
print('id(Z):',id(Z))
Z[:]=X+Y
print('id(Z):',id(Z))
#输出:id(Z): 2027639512256
#id(Z): 2027639512256

数据预处理实现
创建一个人工数据集,并存储在csv(逗号分隔值)文件
os.makedirs() 方法用于递归创建目录。
如果子目录创建失败或者已经存在,会抛出一个 OSError 的异常
语法格式如下:
os.makedirs(path, mode=0o777)
参数
- path – 需要递归创建的目录,可以是相对或者绝对路径。。
- mode – 权限模式。
返回值
该方法没有返回值。
os.path()
Python os.path() 模块 | 菜鸟教程 (runoob.com)
os.path.join(path1[, path2[, …]]) 把目录和文件名合成一个路径
import os
os.makedirs(os.path.join('D:/term1/Machine learning/LM/data','data'),exist_ok=True)
#在'D:/term1/Machine learning/LM/data'下创建了一个data文件夹
data_file=os.path.join('D:/term1/Machine learning/LM/data','data','house_tiny.csv')
#在上面创建的data文件夹里面创建了一个'house_tiny.csv'文件
#打开文件夹,写入数据
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') #列名
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
#从创建的csv文件中加载原始数据集
import pandas as pd
data=pd.read_csv(data_file)
print(data)
''' NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000'''
#pandas.csv() 函数将逗号分离的值 (csv) 文件读入数据框架
为了处理缺失的数据,典型的方法包括插值和删除,这里我们考虑插值
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
pandas中fillna()方法,能够使用指定的方法填充NA/NaN值。
mean(),均值
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
inputs=inputs.fillna(inputs.mean())
print(inputs)
''' NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN'''
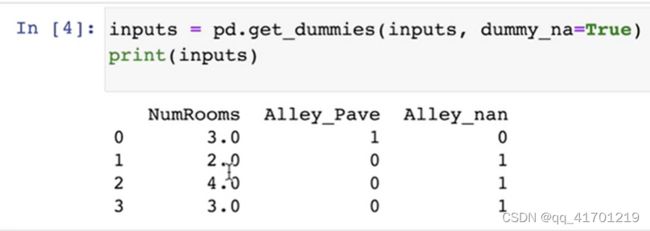
对于inputs中的类别值或离散值,我们将"NaN"视为一个类别
get_dummies 是利用pandas实现one hot encode的方式。