使用Mindstudio进行Pytorch模型量化压缩
视频教程在模型量化压缩(Pytorch)_哔哩哔哩_bilibili
- MindStudio介绍与安装流程
1.1基本介绍:
MindStudio为用户提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。通过依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。另一方面,MindStudio采用插件化扩展机制,以支持开发者通过开发插件来扩展已有功能。MindStudio的功能包括:
针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio能够进行工程管理、编译、调试、性能分析等全流程开发,能够很大程度提高开发效率。
具体的,MindStudio功能框架如图1所示,目前含有的工具链包括:模型转换工具、模型训练工具、自定义算子开发工具、应用开发工具、工程管理工具、编译工具、流程编排工具、精度比对工具、日志管理工具、性能分析工具、设备管理工具等多种工具。

图1
1.2MindStudio主要功能特性:
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
1.3.安装指南:
使用MindStudio前,首先应确定其使用场景,包括纯开发场景和开发运行场景两种:
- 纯开发场景(分部署形态):在非昇腾AI设备上安装MindStudio和Ascend-cann-toolkit开发套件包。可作为开发环境仅能用于代码开发、编译等不依赖于昇腾设备的开发活动(例如ATC模型转换、算子和推理应用程序的纯代码开发)。如果想运行应用程序或进行模型训练等,需要通过MindStudio远程连接功能连接已部署好运行环境所需软件包的昇腾AI设备。
- 开发运行场景(共部署形态):在昇腾AI设备上安装MindStudio、Ascend-cann-toolkit开发套件包、npu-firmware安装包、npu-driver安装包和AI框架(进行模型训练时需要安装)。作为开发环境,开发人员可以进行普通的工程管理、代码编写、编译、模型转换等功能。同时可作为运行环境,运行应用程序或进行模型训练。
其中,不管哪种场景,都需要安装MindStudio、Ascend-cann-toolkit开发套件包:
- MindStudio:提供图形化开发界面,支持应用开发、调试和模型转换功能,同时还支持网络移植、优化和分析等功能。
- Ascend-cann-toolkit:开发套件包。为开发者提供基于昇腾AI处理器的相关算法开发工具包,旨在帮助开发者进行快速、高效的模型、算子和应用的开发。开发套件包只能安装在Linux服务器上,开发者可以在安装开发套件包后,使用MindStudio开发工具进行快速开发部署。
1.4安装方案:
1.4.1安装方案——Linux
MindStudio和Ascend-cann-toolkit可以使用Linux服务器上原生桌面自带的终端gnome-terminal进行安装,也可以在Windows服务器上通过SSH登录到Linux服务器进行安装。
因为MindStudio是一款GUI程序,所以在Windows服务器上通过SSH登录到Linux服务器进行安装时,需要使用集成了X server的SSH终端(比如MobaXterm,该工具版本需要为v20.2及以上)。
- 纯开发场景(分部署形态):该场景下纯开发环境需要安装MindStudio和Ascend-cann-toolkit,如图2所示。昇腾AI设备上运行环境的安装操作请参见《CANN 软件安装指南》。

图2
- 开发运行场景(共部署形态):该场景下需要安装如图3所示软件包,其中驱动、固件、Ascend-cann-toolkit和AI框架包的安装操作请参见《CANN 软件安装指南》。

图3
1.4.2安装方案——Windows
MindStudio可以单独安装在Windows上。在安装MindStudio前需要在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包,之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功能。
纯开发场景(分部署形态):该场景下在Windows服务器上安装MindStudio,昇腾AI设备上的驱动、固件、Ascend-cann-toolkit和AI框架包的安装操作请参见《CANN 软件安装指南》。
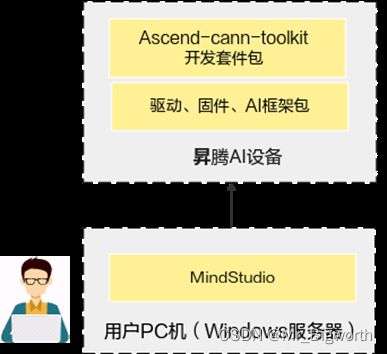
图4
开发运行场景(共部署形态):该场景下在Windows服务器上安装MindStudio,在纯开发环境需要安装Ascend-cann-toolkit,两者建立连接后,形成了集成MindStudio的纯开发环境。昇腾AI设备上运行环境的安装部署操作请参见《CANN 软件安装指南》,此场景运行环境多为端侧、边侧设备如Atlas 500 智能小站和Atlas 200 DK 开发者套件等。

图5
Windows工控机场景:该场景下在Windows服务器上安装MindStudio、驱动、固件和Windows版nnrt,其中驱动、固件和Windows版nnrt需要参见《CANN Windows版用户指南》进行安装。纯开发环境需要安装Ascend-cann-toolkit,与MindStudio连接后基于两者开发的应用程序可在Windows服务器上运行。
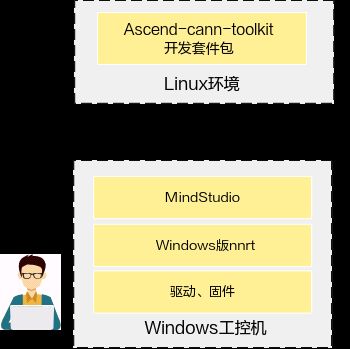
图6
1.5.安装流程:
1.5.1安装流程——Linux

图7
Linux环境下,MindStudio安装流程如图7所示。
- 环境要求:MindStudio安装的环境要求如表1,可对照着判断是否满足条件。
表1 MindStudio环境要求
| 类别 |
限制要求 |
说明 |
| 硬件 |
内存:最小4GB,推荐8GB 磁盘空间:最小6GB |
若Linux宿主机内存为4G,在MindStudio中进行模型转换时,建议Model文件大小不超过350M,如果超过此规格,操作系统可能会因为超过安全内存阈值而工作不稳定。 若Linux宿主机配置升级,比如8G内存,则相应支持的操作对象规格按比例提升。 例如,内存由4G升级到8G,则Model文件建议大小不超过700M。 |
| 系统语言 |
en_US.UTF-8 |
当前仅支持系统语言为英文。 请以任意用户使用locale命令在任意路径下查询编码格式,若系统返回“LANG=en_US.UTF-8”,则表示正确;否则,请以root用户使用“vim /etc/default/locale”命令修改“LANG=en_US.UTF-8”,重启(使用reboot命令)使之生效。 |
| 系统要求 |
操作系统可以通过ssh登录,同时打开ssh的X11Forwarding功能 glibc版本应大于或等于2.27 |
ssh服务的开启和X11Forwarding的配置请参见启动MindStudio时无法显示图形化界面。 对于Docker环境,启动容器时需要映射ssh端口,如 docker run -p {宿主机端口}:{容器内ssh端口} ... 若系统glibc版本小于2.27,请参见启动MindStudio时报glibc版本太低问题处理。 |
| 已验证支持的操作系统 |
Ubuntu 18.04-x86_64 Ubuntu 18.04-aarch64 Ubuntu 20.04-x86_64 Ubuntu 20.04-aarch64 EulerOS 2.8-aarch64 EulerOS 2.10-aarch64 OpenEuler 20.03-x86_64 OpenEuler 20.03-aarch64 CentOS 7.6/8.2-x86_64 CentOS 7.6/8.2-aarch64 银河麒麟OS V10 SP1-aarch64 中标麒麟OS 7.6-aarch64 |
- |
- 准备软件包:软件安装前,请参考表2获取所需软件包和对应的数字签名文件。其中在软件数字签名验证方面,为了防止软件包在传递过程或存储期间被恶意篡改,下载软件包时需下载对应的数字签名文件用于完整性验证。在软件包下载之后,可以参考《OpenPGP签名验证指南》,对从网站下载的软件包进行PGP数字签名校验。如果校验失败,则不要直接使用该软件包,应先联系华为技术支持工程师解决。使用软件包安装/升级之前,也需要按上述过程先验证软件包的数字签名,确保软件包未被篡改过。
表2 软件包
| 软件包 |
说明 |
| MindStudio_{version}_linux.tar.gz |
MindStudio软件包,含有GUI的集成开发环境。 MindStudio安装包解压后包含以下文件:
|
| Ascend-cann-toolkit_{version}_linux-{arch}.run |
Ascend-cann-toolkit开发套件包,包含开发辅助工具和相关开发接口的开发套件包。 如果环境上已安装Ascend-cann-toolkit开发套件包,则无需再次获取。 |
- 准备安装用户:若未安装Ascend-cann-toolkit开发套件包,需要首先检查root用户的umask:
-
- 以root用户登录安装环境。
- 检查root用户的umask值。
- 如果umask不等于0022,请执行如下操作配置,在该文件的最后一行添加umask 0022后保存。
-
接着,创建安装用户,可使用root或非root用户进行安装:
- 若使用root用户安装,可直接开始安装依赖。
- 若使用已存在的非root用户安装,须保证该用户对$HOME目录具有读写以及可执行权限。
- 若使用新的非root用户安装,则需要先创建该用户,则方法如下(请以root用户执行以下命令)。
- 创建用户组和安装用户并设置该用户的$HOME目录:groupadd usergroup,useradd -g usergroup -d /home/username -m username -s /bin/bash。(其中usergroup为用户组,username为用户名)
- 执行以下命令设置非root用户密码:passwd username。
- 安装依赖:安装MindStudio和Ascend-cann-toolkit开发套件包前需要安装相关依赖。具体的依赖列表可参考官方文档。
- 安装MindStudio:在完成了软件包至安装依赖,以及Ascend-cann-toolkit开发套件包的安装后,可以进行MindStudio的安装,其具体的安装步骤如下:
- 使用MindStudio的安装用户上传软件包至待安装环境。
- 解压MindStudio软件包:使用MindStudio的安装用户在软件包所在路径执行如下命令,解压MindStudio_{version}_linux.tar.gz软件包,tar -zxvf MindStudio_{version}_linux.tar.gz,解压后包的内容以及说明请参见表3。
表3 参数说明
| 参数 |
说明 |
| Projects页签(工程管理) |
|
| New Project |
创建新工程,创建后工程保存在“$HOME/AscendProjects”目录。 |
| Open |
打开已有工程。 |
| System Profiler |
进入System Profiling界面。 |
| Get from Version Control… |
用版本控制工具下载代码仓并打开。 |
| Customize页签(定制化个性设置) |
|
| Color theme |
设置颜色主题。 |
| Accessibility |
设置辅助功能,包括设置IDE字体大小和针对红绿色视觉缺陷调整颜色。 |
| Keymap |
设置键盘映射,MindStudio会根据您的环境自动建议预定义的键盘映射,请确保它与您正在使用的操作系统匹配,或者手动选择与您习惯使用的另一个IDE或编辑器中的快捷方式匹配的操作系统。 |
| Import Settings… |
从自定义配置目录导入MindStudio个性化设置。 |
| All Settings… |
进入设置界面。 |
| Plugins页签(插件管理) |
|
| Marketplace |
插件市场,可搜索并下载需要的插件。 |
| Installed |
查看已安装的插件。 |
| Learn MindStudio页签(MindStudio实用帮助) |
|
- 使用MindStudio的安装用户进入软件包解压后的MindStudio/bin目录并启动MindStudio。
- 进入导入设置界面,如图8所示界面。

图8
- 如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功。
图9
1.5.2安装流程——Windows
将MindStudio安装在Windows服务器上时,Windows服务器为本地环境,Linux服务器为远端环境。MindStudio安装流程如图10所示。

图10
- 环境要求:
- 本地环境要求:Windows 10 x86_64操作系统
- 本地安装依赖:Python(版本要求:3.7~3.9),MinGW,Cmake,ACLlib(可选,Windows工控机场景开发Windows应用)
- 配置远端环境:
- 共部署形态远端昇腾AI设备:可参考《CANN 软件安装指南》部署好昇腾AI设备。
- 分部署形态远端纯开发环境:可根据远端Linux服务器的具体系统版本,参见准备安装用户、安装依赖和配置编译环境章节配置MindStudio使用环境。请参考《CANN 软件安装指南》安装Ascend-cann-toolkit开发套件包。
- 准备软件包:软件安装前,请参考表4获取所需软件包和对应的数字签名文件。
表4 软件包
| 软件包 |
说明 |
| MindStudio_{version}_win.zip |
MindStudio免安装压缩包,含有GUI的集成开发环境。 |
| MindStudio_{version}_win.exe |
MindStudio安装包,含有GUI的集成开发环境。 |
- 安装依赖:根据官方流程安装Python依赖,安装MinGW依赖,安装ACLlib包,安装Cmake。
- 安装MindStudio:在完成上述步骤,即可进行MindStudio的安装。
- 双击MindStudio_{version}_win.exe安装包,开始安装MindStudio。
- 进入MindStudio Setup界面,单击“Next”,如图11所示。
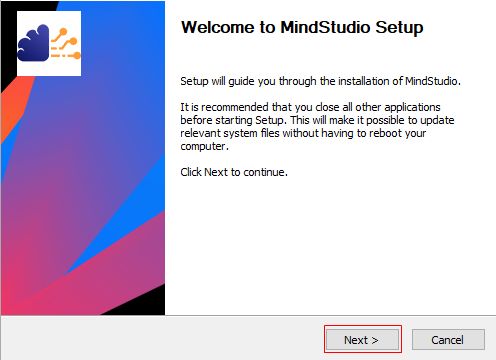
图11
- 选择MindStudio的安装路径后,单击“Next”,如图12所示。
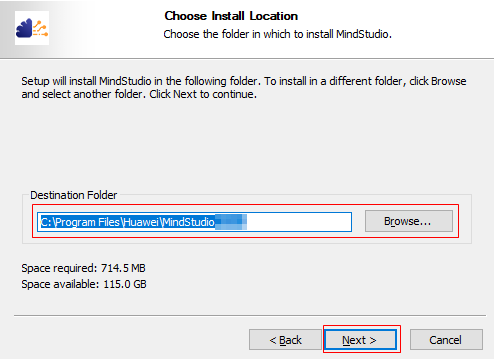
图12
- 用户根据需要勾选安装选项后,单击“Next”,如图13所示。
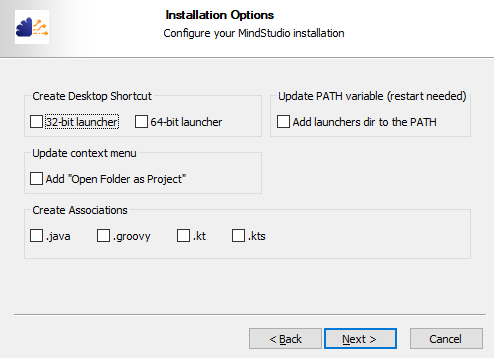
图13
- 选择或创建MindStudio安装路径下的启动菜单文件夹,单击“Install”,如图14所示。
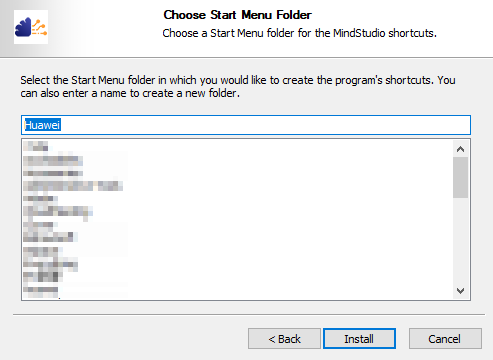
图14
- 开始安装MindStudio,完成后单击“Next”,如图15所示。
图15
- 完成MindStudio安装配置,单击“Finish”,如图16所示。
图16
- 进入MindStudio安装目录的bin文件夹,双击MindStudio应用程序启动MindStudio,导入设置界面,如图17所示界面。

图17
- 如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功,如图18所示。
图18
二.模型量化压缩基本介绍
2.1什么是模型量化
传统意义上的量化即为将连续信号转换为离散信号,在神经网络的量化中,就是把模型参数从浮点数转换成整数的一种模型压缩技术。工业界量化一般指int8,8表示存储一个权重元素所需的位数。把fp32的值经过线性变换转换成int8,网络中耗时的卷积层计算就成了整数的计算,运算量将大大降低,int8使用的比特数只有 fp32的25%,模型推理所占的内存也随之降低。并且一些研究表明,我们训练出的很多大模型的参数都是过多的,有很多冗余参数或者神经元。我们可以将这些冗余的参数和神经元给裁减掉,从而减小模型的体积。网络裁剪的方法有参数裁剪和神经元裁剪。
2.2为什么需要模型量化
理论上来说,深度神经网络模型越深,非线性程度也就越大,相应的对现实问题的表达能力越强,但相应的代价是,训练成本和模型大小的增加。同时,在部署时,大模型预测速度较低且需要更好的硬件支持。但随着深度学习越来越多的参与到产业中,很多情况下,需要将模型在手机端、IoT端部署,这种部署环境受到能耗和设备体积的限制,端侧硬件的计算能力和存储能力相对较弱,突出的诉求主要体现在以下三点:
-
- 首先是速度,比如像人脸闸机、人脸解锁手机等应用,对响应速度比较敏感,需要做到实时响应。
- 其次是存储,比如电网周边环境监测这个应用场景中,要图像目标检测模型部署在可用内存只有200M的监控设备上,且当监控程序运行后,剩余内存会小于30M。
- 最后是耗能,离线翻译这种移动设备内置AI模型的能耗直接决定了它的续航能力。
近年来随着深度学习的快速发展有很多关于量化方法的研究,模型大小不仅仅是内存容量问题,也是内存带宽问题,模型在每次预测时都会使用模型全中,图像相关的应用程序需要实时处理数据,这意味着至少30fps,例如,如果部署ResNet-50来说就需要3GB/s的访问带宽,因此深度学习领域对于解决这一问题投入大量研究资源,其中一个方面就是通过压缩、编码等方式减小网络规模,其中量化是最广泛采用的压缩方法之一。
三.模型量化压缩前期准备
采用基于MindStudio的工具AutoML(Auto Machine Learning)来进行模型自动性能调优中的模型量化,支持对昇腾910或GPU搜索训练,覆盖MindSpore,PyTorch框架,能对CV领域分类、检测和分割等常用模型进行自动性能调优。
业务流程如图所示:
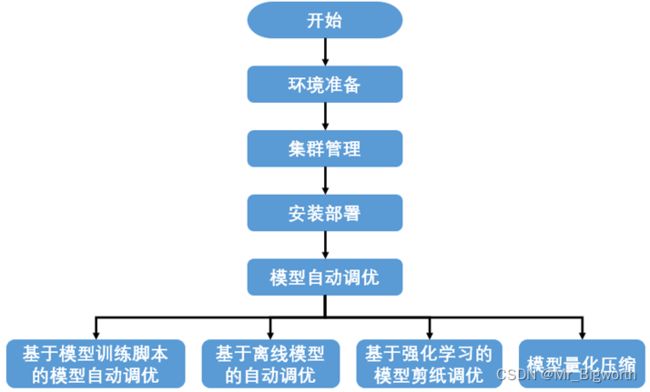
图19
3.1环境准备
获取noah_vega安装whl包,安装地址:地址,下载1.8.3版本的noah_vega-{version}-py3-none-any.whl安装包并放至IDE运行的服务器工作路径中,以便安装部署时选用该路径。
- noah_vega提供安全通信特性,用户在AutoML安装完成后需要参照安全配置说明正确配置vega之后才能以通信安全的方式运行训练任务。如果使用1.8版本的安全特性noah_vega包,启动任务时需要在命令末端增加“-s”参数。
3.1.1Vega的安全配置,包括如下步骤:
①安装OpenSSL:首先要安装OpenSSL 1.1.1,从源码编译安装,或者直接安装编译后的发行包。然后安装OpenSSL的python接口,如下:
pip3 install --user pyOpenSSL==19.0.0
②生成CA证书:执行如下命令生成CA证书
openssl genrsa -out ca.key 4096
openssl req -new -x509 -key ca.key -out ca.crt -subj "/C=
③生成评估服务使用的证书:评估服务支持加密证书和普通证书
在此我们使用普通证书,执行如下脚本,生成评估服务器端和客户端使用的证书的私钥和证书:
openssl genrsa -out server.key 4096
openssl req -new -key server.key -out server.csr -subj "/C=
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -extfile ./openssl.cnf -extensions v3_req
rm server.csr
openssl genrsa -out client.key 4096
openssl req -new -key client.key -out client.csr -extensions v3_ca -subj "/C=
openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -extfile ./openssl.cnf -extensions v3_req
rm client.csr
④生成Dask使用的证书
执行如下脚本,生成Dask服务器端和客户端使用的证书的私钥和证书:
openssl genrsa -out server_dask.key 4096
openssl req -new -key server_dask.key -out server_dask.csr -subj "/C=
openssl x509 -req -in server_dask.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server_dask.crt -extfile ./openssl.cnf -extensions v3_req
rm server_dask.csr
openssl genrsa -out client_dask.key 4096
openssl req -new -key client_dask.key -out client_dask.csr -subj "/C=
openssl x509 -req -in client_dask.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client_dask.crt -extfile ./openssl.cnf -extensions v3_req
rm client_dask.csr
删除CA私钥:
rm ca.key
⑥配置安全配置文件
请在当前用户的主目录下创建.vega目录,并将如上生成的秘钥、证书、加密材料等,拷贝到该目录下,并改变权限:
mkdir ~/.vega
mv * ~/.vega/
chmod 600 ~/.vega/*
在~/.vega目录下创建server.ini和client.ini。
在训练集群中,需要配置~/.vega/server.ini和~/.vega/client.ini:
server.ini:
[security] # 以下文件路径需要修改为绝对路径
ca_cert=<~/.vega/ca.crt>
server_cert_dask=<~/.vega/server_dask.crt>
server_secret_key_dask=<~/.vega/server_dask.key>
client_cert_dask=<~/.vega/client_dask.crt>
client_secret_key_dask=<~/.vega/client_dask.key>
client.ini:
[security] # 以下文件路径需要修改为绝对路径
ca_cert=<~/.vega/ca.crt>
client_cert=<~/.vega/client.crt>
client_secret_key=<~/.vega/client.key>
encrypted_password=<加密后的client端的口令> # 如果使用普通证书, 此项配置为空
key_component_1=<~/.vega/ksmaster_client.dat> # 如果使用普通证书, 此项配置为空
key_component_2=<~/.vega/ksstandby_client.dat> # 如果使用普通证书, 此项配置为空
在评估服务器上,需要配置~/.vega/vega.ini:
[security] # 以下文件路径需要修改为绝对路径
ca_cert=<~/.vega/ca.crt>
server_cert=<~/.vega/server.crt>
server_secret_key=<~/.vega/server.key>
encrypted_password=<加密后的server端的口令> # 如果使用普通证书, 此项配置为空
key_component_1=<~/.vega/ksmaster_server.dat> # 如果使用普通证书, 此项配置为空
key_component_2=<~/.vega/ksstandby_server.dat> # 如果使用普通证书, 此项配置为空
训练服务器:
- 需安装好训练环境。
- python版本为3.6.0或以上的版本,所有训练服务器的python版本需要保持一致。
- pip源可用,确保pip3 install --user --upgrade pip能执行成功。
- 已安装3.13.0版本的protobuf依赖包。
- 已安装sshd。
- 在各个训练服务器上的~/.bashrc文件中配置如下环境变量:
source {Driver包安装路径}/driver/bin/setenv.bash
source {CANN包安装路径}/ascend-toolkit/set_env.sh
source {CANN包安装路径}/tfplugin/set_env.sh
export install_path={CANN包安装路径}/ascend-toolkit/latest
export LD_LIBRARY_PATH=${install_path}/compiler/lib64/:$LD_LIBRARY_PATH
export TBE_IMPL_PATH=${install_path}/opp/op_impl/built-in/ai_core/tbe
export JOB_ID=10087 #该项不建议改动
export DEVICE_ID=0 #单卡训练使用的device_id
#以下为多卡配置,视个人情况修改
export RANK_ID=0
export RANK_SIZE=8
export BATCH_TASK_INDEX=0
export RANK_TABLE_FILE=多卡环境组网信息json文件所在路径 #从多卡环境组网信息json文件中选择要使用的device_id
export NPU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #从多卡环境组网信息json文件中选择要使用的device_id
export TF_CPP_MIN_LOG_LEVEL=3 #该项可控制TF框架本身日志级别的打印,0-DEBUG,1-INFO,2-WARNING,3-ERROR
推理服务器
- 需安装好推理环境
- python版本需为3.6.0或以上的版本。
- pip源可用,确保pip3 install --user --upgrade pip能执行成功。
- 在推理服务器上的~/.bashrc文件中配置如下环境变量:
source {CANN包安装路径}/ascend-toolkit/set_env.sh
export install_path={CANN包安装路径}/ascend-toolkit/latest
export DDK_PATH=${install_path}
export PATH=${install_path}/compiler/bin:${install_path}/compiler/ccec_compiler/bin:${PATH}
export LD_LIBRARY_PATH=${install_path}/lib64:/usr/local/Ascend/driver/lib64:/usr/local/Ascend/driver/lib64/stub:${LD_LIBRARY_PATH}
export PYTHONPATH=${install_path}/python/site-packages:${install_path}/compiler/python/site-packages:${install_path}/compiler/python/site-packages/auto_tune.egg:${install_path}/compiler/python/site-packages/schedule_search.egg:${install_path}/opp/op_impl/built-in/ai_core/tbe:${PYTHONPATH}
export ASCEND_OPP_PATH=${install_path}/opp
export SOC_VERSION=Ascend310
export NPU_HOST_LIB=${install_path}/acllib/lib64/stub/
export JOB_ID=10087 #该项不建议改动
3.2集群管理
创建新集群
①在菜单栏选择“Ascend > AutoML > Cluster Manager”。进入“Cluster Manager”界面。
②单击“+New Cluster”。进入“Add Cluster”界面,如图1所示。界面参数说明如表1所示。
图一
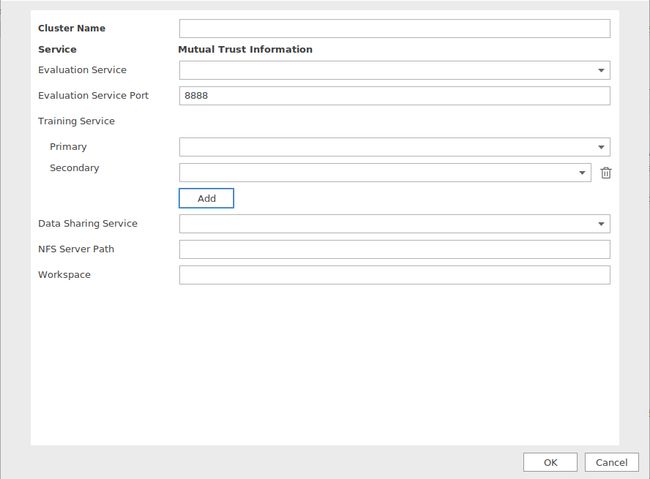
表三
| 参数 |
说明 |
| Cluster Name |
集群名称,在所有集群里具有唯一性。只支持英文字母、数字或者下划线,以英文字母开头,且长度不超过32个字符。例如:Cluster_01。 |
| Evaluation Service |
评估服务,通过下拉框选择已通过SSH配置好的远端环境。 |
| Evaluation Service Port |
评估服务器端口,仅支持输入1~65535之间的数字,默认值为8888。 |
| Training Service |
训练服务器,通过下拉框选择已通过SSH配置好的远端训练环境。 |
| Primary |
训练服务集群主节点,通过下拉框选择已通过SSH配置好的远端训练环境。 |
| Add |
添加训练服务。单击选择此项后,“Secondary”、“Data Sharing Service”和“NFS Server Path”参数才会在界面体现。 |
| Secondary |
训练服务集群从节点,通过下拉框选择已通过SSH配置好的远端训练环境。单击
可以删除从节点。 |
| Data Sharing Service |
数据共享服务器,通过下拉框选择已通过SSH配置好的远端环境。 |
| NFS Server Path |
NFS服务器路径。例如:/home/test/nfs_cache。 |
| Workspace |
所有训练服务器的工作路径。例如:/home/test/nfs_folder。 |
③单击“OK”,完成新集群创建。
删除集群
①在菜单栏选择“Ascend > AutoML > Cluster Manager”。进入“Cluster Manager”界面。
②单击需要删除的集群后方的,如图2所示。
图二

3.3安装部署
①在菜单栏选择“Ascend > AutoML > Install AutoML”。进入“Install AutoML”界面,如图1所示。
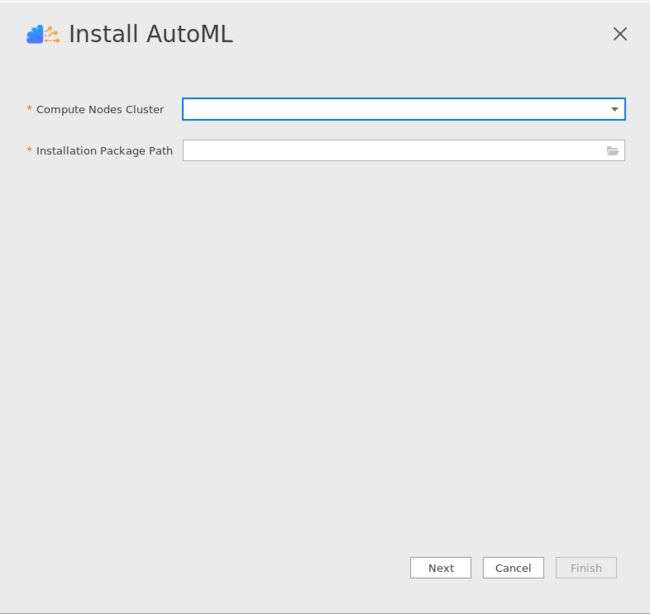
②单击“Next”,进入安装界面,如图2所示。

③显示安装完成后,根据实际情况执行以下步骤。
单机场景:单击“Finish”,完成安装部署。
启动推理服务器
启动任务之前需要编译推理程序并启动推理服务。
①编译推理程序步骤:
i) 安装配置Atlas300环境
首先需要配置Ascend 300环境,然后请安装评估服务,请执行如下命令安装:
pip3 install --user --upgrade evaluate-service
安装完成后,将~/.local/lib/python3.7/site-packages/evaluate_service/hardwares/davin
nci/samples/atlas300拷贝到当前目录,执行如下操作,检查环境是否配置正确:
echo "[INFO] start check the enviroment..."
python3 -c "import te" && echo "[INFO] check te sucess"
python3 -c "import topi" && echo "[INFO] check topi sucess"
atc --version && echo "[INFO] check atc sucess "
echo "[INFO] start compile the example..."
cd ./atlas300/
mkdir -p build/intermediates/host
cd build/intermediates/host
cmake ../../src -DCMAKE_CXX_COMPILER=g++ -DCMAKE_SKIP_RPATH=TRUE
make && echo "[INFO] check the env sucess!"
ii) 编译推理程序
参考地址,下载代码并完成编译。 并把编译后的可执行文件拷贝到~/.local/lib/python3.7/site-packages/evaluate_service/hardwares/davinci/目录下。
iii)启动评估服务
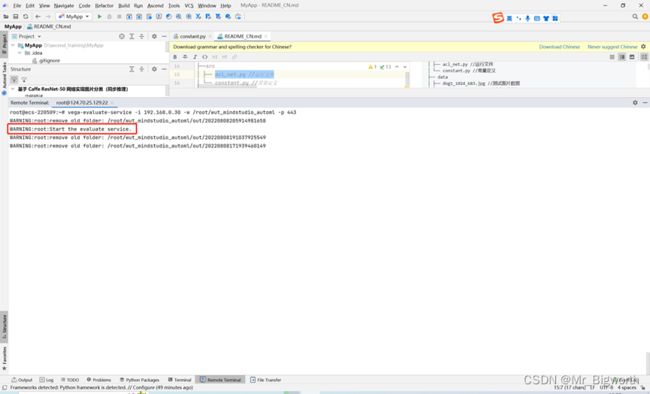
使用如下命令启动评估服务:
vega-evaluate_service-service -i {your_ip_adress} -p {port} -w {your_work_path}
其中:
-i参数指定当前使用的服务器的ip地址
-p参数指定当前使用的服务器的的监听端口,默认值8888
-w参数指定工作路径, 程序运行时的中间文件将存储在该目录下,请使用绝对路径
②启动推理服务
在推理服务器上运行命令vega-evaluate-service -i {your_ip_adress} -w {your_work_path} -p {port}启动。其中-i参数指定当前使用的服务器的ip地址。-w参数指定工作路径,程序运行时的中间文件将存储在该目录下,请使用绝对路径。-p参数指定推理服务器端口,启动推理服务器端口需要与创建集群时指定的端口一致,默认指定8888端口。其他参数的设置可查看该命令的帮助信息,一般情况下建议采用默认值。
四.模型量化压缩操作步骤(以PyTorch框架的ResNet50为例)
4.1前提条件
已下载并安装好Ascend-cann-toolkit包。运行以下命令设置对应环境变量:
source {CANN路径}/ascend-toolkit/set_env.sh
执行以下命令安装fvcore包:
pip3 install fvcore --user
4.2打开配置文件
进入{CANN包安装路径}/ascend-toolkit/latest/tools/ascend_automl/examples/classification /examples/classification/pytorch/quant/路径,打开quant_rl_resnet.yml文件,如下图所示

4.3根据实际情况修改配置以下参数
- local_base_path: /path/of/workdir#工作路径,
- type: ResNet_ModelZoo #该模型的定义方法需参照自定义模型注册
- data_path: /path/of/dataset #数据集路径
- pretrained_model_file: /path/of/pretrain/model/file
#ResNet50预训练权重文件
- remote_host: http://xxx.xxx.xxx.xxx:port/ #远端推理服务器URL,后四位为端口号,需要与创建集群时的端口号一致。如果在推理服务器中执行“vega-config -q sec”的返回值为“True”,请将“http”更改为“https”
4.4模型注册
以resnet50为例,需要在~/Ascend/ascend-toolkit/5.1.RC2/tools/ascend_automl/module_register.py中进行模型注册,添加如下代码
"ascend_automl.core.networks.pytorch.resnet":
{"resnet50": ["ResNet_ModelZoo"],
},
并在~/Ascend/ascend-toolkit/5.1.RC2/tools/ascend_automl/core/networks/pytorch目录下添加模型网络结构文件。
4.5启动模型量化调优任务
执行命令vega quant_rl_resnet.yml -d NPU然后如图所示,成功进行模型量化调优:


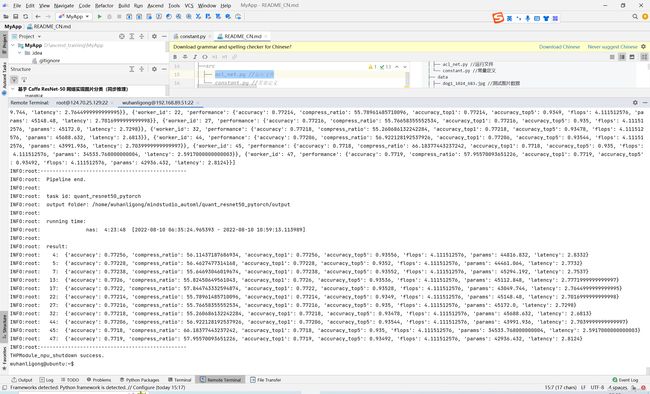
五、FAQ
5.1.出现import error报错时:
Please check the above information for the configurations
Traceback (most recent call last):
File "/usr/local/python3.7.5/lib/python3.7/site-packages/sklearn/__check_build/init.py", line 48, in
from ._check_build import check_build # noqa
ImportError: /usr/local/python3.7.5/lib/python3.7/site-packages/sklearn/__check_build/../../scikit_learn.libs/libgomp-d22c30c5.so.1.0.0: cannot allocate memory in static TLS block
导入环境变量:
export LD_PRELOAD=$LD_PRELOAD:/usr/local/python3.7.5/lib/python3.7/site-packages/scikit_learn.libs/libgomp-d22c30c5.so.1.0.0
六、关于MindStudio更多的内容
如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的[用户手册](https://www.hiascend.com/document/detail/zh/mindstudio/304/progressiveknowledge/index.html),里面模型训练、脚本转换、模型开发、算子开发、精度对比、AI Core Error分析工具、AutoML工具(Beta)、Benchmark工具、专家系统工具等各种使用安装操作的详细介绍。
如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的[昇腾论坛](https://www.huaweicloud.com)进行提问,会有华为内部技术人员对其进行解答,如下图。