论文笔记:FCOS: Fully Convolutional One-Stage Object Detection
一、基本信息
标题:FCOS: Fully Convolutional One-Stage Object Detection
时间:2019
论文领域:目标检测、深度学习
引用格式:Tian Z, Shen C, Chen H, et al. Fcos: Fully convolutional one-stage object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 9627-9636.
二、研究背景
RetinaNet, SSD,YOLOv3, Faster R-CNN 依赖预定义的锚框,FCOS没有依赖这种机制。除了不需要计算锚框重叠外,还能避免敏感的超参数。仅需要最后使用NMS处理,且整体更简单。
基于锚的检测器有一些缺点:
- 检测性能对锚框的大小、长宽比和数量非常敏感
- 预定义的锚定框还会影响检测器的泛化能力
- 太多锚框且绝大多数是负样本,导致训练时正负样本不平衡
- 锚框涉及复杂计算IoU
相关工作
- Anchor-based Detectors
基于滑动窗检测器的思想:
Faster R-CNN, Faster R-CNN, SSD,YOLOv2 - Anchor-free Detectors
YOLOv1预测bbox,只有靠近中心的点被使用但是recall太低
CornerNet检测bbox的一对角,分组,形成最终检测到的bbox。CornerNet需要更复杂的后处理来对属于同一实例的角进行分组。为了分组需要学习额外的距离度量。
DenseBox难以处理重叠bbox,召回率较低。
三、创新点
- 基于FCN,类似语义分割,逐个像素点预测
- 不需要锚框,较少参数,训练时更简单
- 不需要计算IOU
- 比基于锚框的RPN表现更好
- 可以快速应用在其他视觉任务上
Fully Convolutional OneStage Object Detector
如上图左,一个像素属于多个框时,取最小的
回归目标计算公式如下:
l ∗ = x − x 0 ( i ) , t ∗ = y − y 0 ( i ) r ∗ = x 1 ( i ) − x , b ∗ = y 1 ( i ) − y \begin{array}{l} l^{*}=x-x_{0}^{(i)}, t^{*}=y-y_{0}^{(i)} \\ r^{*}=x_{1}^{(i)}-x, \quad b^{*}=y_{1}^{(i)}-y \end{array} l∗=x−x0(i),t∗=y−y0(i)r∗=x1(i)−x,b∗=y1(i)−y
那么4维向量 t = ( l , t , r , b ) \boldsymbol{t}=(l, t, r, b) t=(l,t,r,b)
p是80维分类标签
损失函数
L ( { p x , y } , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y 1 { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) \begin{aligned} L\left(\left\{\boldsymbol{p}_{x, y}\right\},\left\{\boldsymbol{t}_{x, y}\right\}\right) &=\frac{1}{N_{\mathrm{pos}}} \sum_{x, y} L_{\mathrm{cls}}\left(\boldsymbol{p}_{x, y}, c_{x, y}^{*}\right) \\ &+\frac{\lambda}{N_{\mathrm{pos}}} \sum_{x, y} \mathbb{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\mathrm{reg}}\left(\boldsymbol{t}_{x, y}, \boldsymbol{t}_{x, y}^{*}\right) \end{aligned} L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑1{cx,y∗>0}Lreg(tx,y,tx,y∗)
L c l s L_{\mathrm{cls}} Lcls是焦点的损失,用于计算类别
L r e g L_{\mathrm{reg}} Lreg是IOU损失,用于计算BBox
N pos N_{\text {pos }} Npos 是正样本点数目
1 { c i ∗ > 0 } \mathbb{1}\left\{c_{i}^{*}>0\right\} 1{ci∗>0}是类别指示函数
实验中将p>0.05的作为正样本,使用公式1进行边界框预测
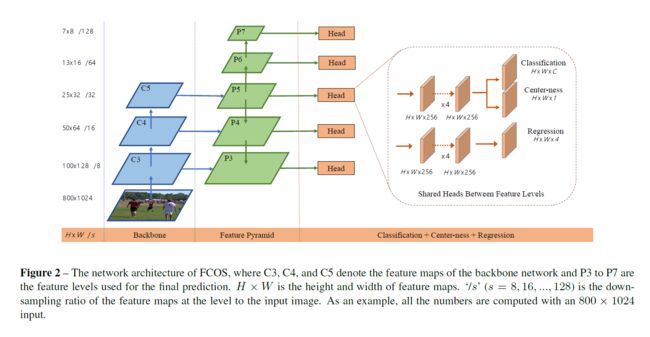
Multilevel Prediction with FPN for FCOS
解决2个问题:
- 大步长(16* 16)导致较低BPR,对于FCOS,不可能因为大的步伐导致对象没有在最终特征地图编中召回一个。BPR不是FCOS主要的问题。而且通过FPN特征金字塔网络可以达到基于锚的最大上限。
- 通过FPN,预测不同尺度下特征图。主干CNNs网络的特征层 C3、C4、C5经过一个1*1的卷积得到P3,P4,P5。P6,P7在P5、P6基础上进行步长为2的卷积(降采样),最终对这五个尺度都做逐像素回归。 m i < max ( l ∗ , t ∗ , r ∗ , b ∗ ) m i − 1 m_{i}<\max \left(l^{*}, t^{*}, r^{*}, b^{*}\right)m_{i-1} mi<max(l∗,t∗,r∗,b∗)mi−1限定特定层检测特定大小的物体(由于大部分重叠发生在尺寸相差较大的物体之间,因此多尺度预测可以在很大程度上缓解目标框重叠情况下的预测性能)
最后提到共享head在不同特征层等级,改进性能。使用 exp ( s i x ) \exp \left(s_{i} x\right) exp(six),其中 s i s_i si能够通自动调整不同层级特征的指数函数的基数,这从经验上提高了检测性能。
Centerness for FCOS
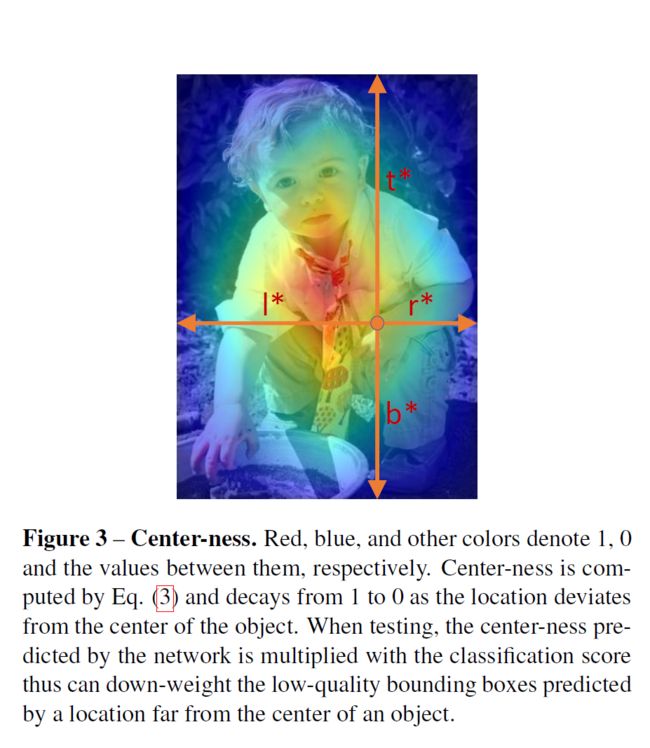
使用了FPN的FCOS仍然与机遇锚的检测器有差距,主要是因为大量低质量的预测BBox远离了实物中心。提出简单有效centernes:
centerness ∗ = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) × min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) \text { centerness }^{*}=\sqrt{\frac{\min \left(l^{*}, r^{*}\right)}{\max \left(l^{*}, r^{*}\right)} \times \frac{\min \left(t^{*}, b^{*}\right)}{\max \left(t^{*}, b^{*}\right)}} centerness ∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
远离中心的min/max分数更小,所以把这项加入到前面提到的损失中,最后后这些盒子经过NMS会被抑制掉,提高检测性能。
如上图3,随着位置偏离物体中心,中心度从1衰减到0。测试时,将网络预测的中心度与分类分数相乘,可以对远离物体中心的位置预测的质量较差的边界盒进行减重。
四、实验结果
主干网络使用ResNet-50和RetinaNet同样的超参数。
BPR(best possible recall)对比:
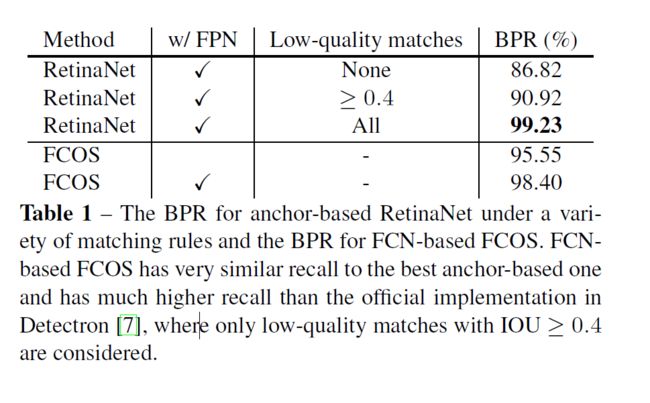
和最好的RetinaNet相差一点点,对于IOU>=0.4的RetinaNet则提示很多。
FPN对比:

有效降低ambiguous区域/样本。
各层对比:
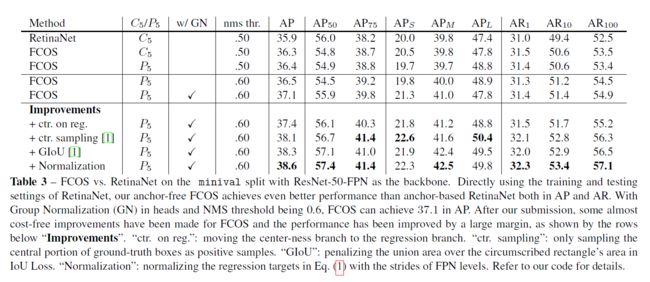
直接使用FCOS可以达到比RetinaNet更好的AP和AR
center-ness对比
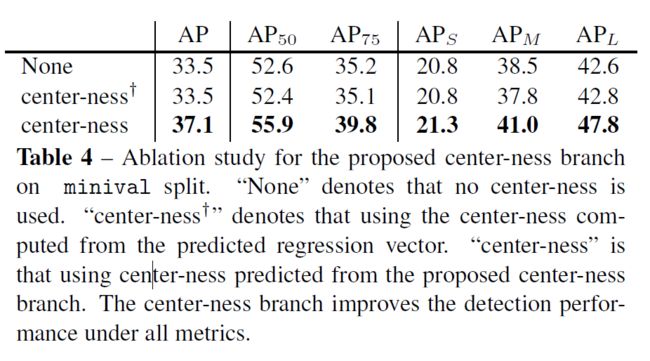
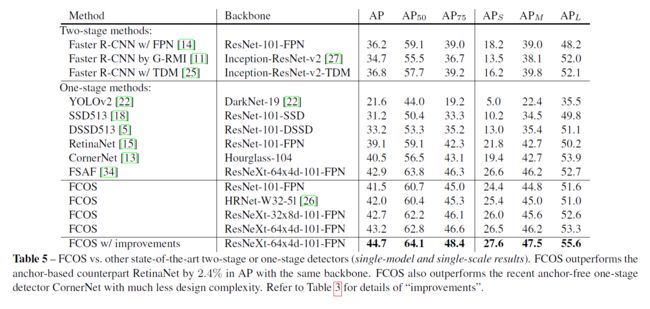
FCOS vs. Anchor-based Detectors
五、结论与思考
作者结论
我们已经提出了一个无锚和无建议的onestage探测器FCOS。实验表明,FCOS比流行的基于锚的onestage检测器(包括RetinaNet、YOLO和SSD)更好,但设计复杂度低得多。FCOS完全避免了所有与锚盒相关的计算和超参数,以逐像素预测的方式解决了目标检测问题,类似于语义分割等稠密预测任务。在单级探测器中,FCOS也达到了最先进的性能。我们还表明,FCOS可以作为快速R-CNN的两级检测器的rpn,并在很大程度上优于其rpn。鉴于其有效性和效率,我们希望FCOS能够成为目前主流的基于锚点的探测器的一种强大而简单的替代方案。我们也相信FCOS可以扩展到解决许多其他的实例级识别任务。
总结
思考
参考
FCOS:Fully Convolutional One-Stage Object Detection--------论文理解