Spark Shuffle详解
概述
Shuffle,翻译成中文就是洗牌。之所以需要Shuffle,还是因为具有某种共同特征的一类数据需要最终汇聚(aggregate)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。以最简单的Word Count为例,其中数据保存在Node1、Node2和Node3;
经过处理后,这些数据最终会汇聚到Nodea、Nodeb处理,如下图所示。
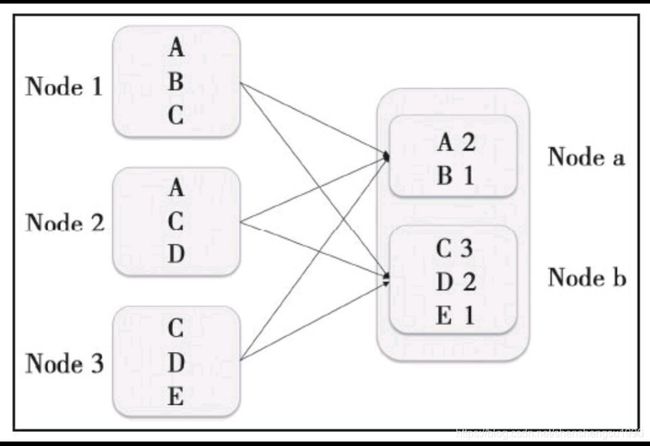
这个数据重新打乱然后汇聚到不同节点的过程就是Shuffle。但是实际上,Shuffle过程可能会非常复杂:
1)数据量会很大,比如单位为TB或PB的数据分散到几百甚至数千、数万台机器上。
2)为了将这个数据汇聚到正确的节点,需要将这些数据放入正确的Partition,因为数据大小已经大于节点的内存,因此这个过程中可能会发生多次硬盘续写。
3)为了节省带宽,这个数据可能需要压缩,如何在压缩率和压缩解压时间中间
做一个比较好的选择?
4)数据需要通过网络传输,因此数据的序列化和反序列化也变得相对复杂。
一般来说,每个Task处理的数据可以完全载入内存(如果不能,可以减小每个Partition的大小),因此Task可以做到在内存中计算。但是对于Shuffle来说,如果不持久化这个中间结果,一旦数据丢失,就需要重新计算依赖的全部RDD,因此有必要持久化这个中间结果。所以这就是为什么Shuffle过程会产生文件的原因。
如果Shuffle过程不落地,①可能会造成内存溢出 ②当某分区丢失时,会重新计算所有父分区数据
Shuffle Write
Shuffle Write,即数据是如何持久化到文件中,以使得下游的Task可以获取到其需要处理的数据的(即Shuffle Read)。在Spark 0.8之前,Shuffle Write是持久化到缓存的,但后来发现实际应用中,shuffle过程带来的数据通常是巨量的,所以经常会发生内存溢出的情况,所以在Spark 0.8以后,Shuffle Write会将数据持久化到硬盘,再之后Shuffle Write不断进行演进优化,但是数据落地到本地文件系统的实现并没有改变。
1)Hash Based Shuffle Write
在Spark 1.0以前,Spark只支持Hash Based Shuffle。因为在很多运算场景中并不需要排序,因此多余的排序只能使性能变差,比如Hadoop的Map Reduce就是这么实现的,也就是Reducer拿到的数据都是已经排好序的。实际上Spark的实现很简单:每个Shuffle Map Task根据key的哈希值,计算出每个key需要写入的Partition然后将数据单独写入一个文件,这个Partition实际上就对应了下游的一个Shuffle Map Task或者Result Task。因此下游的Task在计算时会通过网络(如果该Task与上游的Shuffle Map Task运行在同一个节点上,那么此时就是一个本地的硬盘读写)读取这个文件并进行计算。
Hash Based Shuffle Write存在的问题
由于每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件,因此文件的数量就是:
number(shuffle_map_task)*number(result_task)。
如果Shuffle Map Task是1000,下游的Task是500,那么理论上会产生500000个文件(对于size为0的文件Spark有特殊的处理)。生产环境中Task的数量实际上会更多,因此这个简单的实现会带来以下问题:
1)每个节点可能会同时打开多个文件,每次打开文件都会占用一定内存。假设每个Write Handler的默认需要100KB的内存,那么同时打开这些文件需要50GB的内存,对于一个集群来说,还是有一定的压力的。尤其是如果Shuffle Map Task和下游的Task同时增大10倍,那么整体的内存就增长到5TB。
2)从整体的角度来看,打开多个文件对于系统来说意味着随机读,尤其是每个文件比较小但是数量非常多的情况。而现在机械硬盘在随机读方面的性能特别差,非常容易成为性能的瓶颈。如果集群依赖的是固态硬盘,也许情况会改善很多,但是随机写的性能肯定不如顺序写的。
2)Sort Based Shuffle Write
在Spark 1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager从Hash换成了Sort,对应的实现类分别是org.apache.spark.shuffle.hash.HashShuffleManager和org.apache.spark.shuffle.sort.SortShuffleManager。
那么Sort Based Shuffle“取代”Hash Based Shuffle作为默认选项的原因是什么?
正如前面提到的,Hash Based Shuffle的每个Mapper都需要为每个Reducer写一个文件,供Reducer读取,即需要产生M*R个数量的文件,如果Mapper和Reducer的数量比较大,产生的文件数会非常多。
而Sort Based Shuffle的模式是:每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个Index文件,

Reducer可以通过这个Index文件取得它需要处理的数据。避免产生大量文件的直接收益就是节省了内存的使用和顺序Disk IO带来的低延时。节省内存的使用可以减少GC的风险和频率。而减少文件的数量可以避免同时写多个文件给系统带来的压力。
Sort Based Write实现详解
Shuffle Map Task会按照key相对应的Partition ID进行Sort,其中属于同一个Partition的key不会Sort。因为对于不需要Sort的操作来说,这个Sort是负收益的;要知道之前Spark刚开始使用Hash Based的Shuffle而不是Sort Based就是为了避免Hadoop Map Reduce对于所有计算都会Sort的性能损耗。对于那些需要Sort的运算,比如sortByKey,这个Sort在Spark 1.2.0里还是由Reducer完成的。