win10简单安装spark
win10安装spark
安装步骤分为java, hadoop, scala和 spark四步。
一、Java环境搭建
首先从网站
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载匹配Windows x64的JDK安装文件。之后按流程一步步安装即可。最后修改系统环境变量。
右键我的电脑—属性—-高级系统设置就会看到下面的界面:
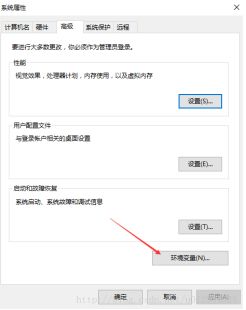
新建JAVA_HOME环境变量,变量值为jdk的安装目录。
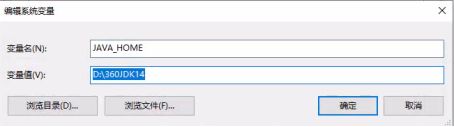
将bin目录添加到PATH环境变量,双击或者点编辑都可。

新建%JAVA_HOME%\bin环境变量,最好将其通过上移到最上,避免有其它冲突的java环境变量。

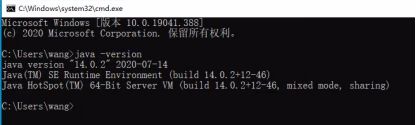
所有变量添加完毕,一路确认后,win+r打开命令行,输入cmd。
输入java -version,看到下面界面,说明已经成功。
二、安装hadoop
安装好JDK之后在
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common
网站上下载hadoop并解压,我解压到了D盘的根目录下,在D:\hadoop-2.8.5\etc\hadoop找到下面4个文件并进行以下修改:
打开D:\hadoop-2.8.5\etc\hadoop\core-site.xml将以下部分复制到configuration中:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
打开D:\hadoop-2.8.5\etc\hadoop\mapred-site.xml将以下部分复制到configuration中:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
打开D:\hadoop-2.8.5\etc\hadoop\yarn-site.xml将以下部分复制到configuration中:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hahoop.mapred.ShuffleHandler</value>
</property>
</configuration>
打开D:\hadoop-2.8.5\etc\hadoop\hdfs-site.xml 将以下部分复制到configuration中:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>
之后修改系统的环境变量,把D:\hadoop-2.8.5\bin;D:\hadoop-2.8.5\sbin加入到环境变量中,并新建变量HADOOP_HOME,其变量值为:D:\hadoop-2.8.5\bin。
此时hadoop安装成功。
打开cmd进入hadoop安装路径并输入以下命令:
D:>cd D:\hadoop-2.8.5\bin
D:\hadoop-2.8.5\bin>hadoop namenode -format
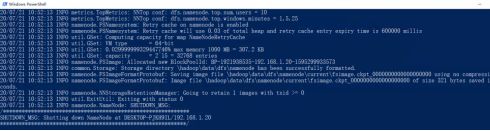
之后进入sbin路径下键入如下命令:
start-all.cmd

此时会弹出四个新的cmd窗口:
在浏览器中输入:http://localhost:8088/cluster可以看到YARN界面:

关闭就使用命令:
stop-all.cmd
三、安装spark
首先登陆
http://spark.apache.org/downloads.html
下载符合本机Hadoop和JDK版本的Spark安装包,我的Hadoop版本是2.8.5因此下载了2.4.6版本的Spark。(spark-2.4.6-bin-hadoop2.7)
下载完成后进行解压在D盘的根目录下,设置环境变量。
首先新建一个环境变量SPARK_HOME,变量名是安装的路径:

之后在Path中添加一个路径即可:
![]()
四、安装scala
进入网站
https://www.scala-lang.org/download
下载Scala的安装包:(scala-2.13.3.msi)
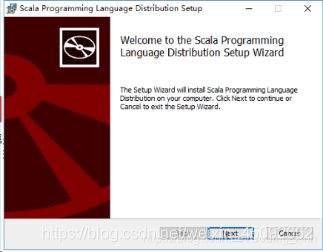
安装过程中没有任何需要更改的地方,只需要摁Next即可。我在中间修改了一下安装位置,因为C盘放不下了。最后安装完毕后会自动新建环境变量。
打开cmd输入scala如果看到如下标识则安装成功。

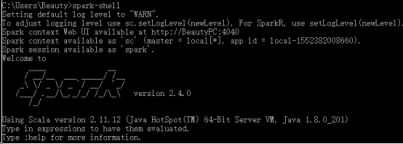
最后打开cmd键入spark-shell出现以下标识则是安装成功:
小插曲:2022年2月17日,此博客被爬虫抄袭了,并且他人还把抄袭的内容设置为付费才能看,现在通过客服已经删除了抄袭者博客,我打开那人博客,几百篇博客全部都是抄袭的,访问量很高,但评论只有3条,只能希望CSDN官方把控下博客质量,这种人的博客居然敢收费???

有用请点个赞!!
本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/weixin_45092662。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。