机械臂论文笔记(二)【实时抓取点检测】Real-Time Grasp Detection Using Convolutional Neural Networks
机械臂论文笔记(二)【实时抓取点检测】Real-Time Grasp Detection Using Convolutional Neural Networks
- 摘要
- 一,介绍
- 二,相关工作
- 三,问题描述
- 四,使用神经网络进行抓取检测
- 五,实验和评估
- 六,结果
- 七,讨论
- 八,总结
- 参考:
摘要
Abstract— We present an accurate, real-time approach torobotic grasp detection based on convolutional neural networks.Our network performs single-stage regression to graspable bounding boxes without using standard sliding window or region proposal techniques. The model outperforms state-of-the-art approaches by 14 percentage points and runs at 13 frames per second on a GPU. Our network can simultaneously perform classification so that in a single step it recognizes the object and finds a good grasp rectangle. A modification to this model predicts multiple grasps per object by using a locally constrained prediction mechanism. The locally constrained model performs significantly better, especially on objects that can be grasped in a variety of ways.
我们提出一种准确而且可以达到实时性能要求基于卷积神经网络的,机器人抓取检测方法。我们的抓取方法没有使用常见的滑动窗口或者区域选择技术,我们的网络只是使用single-stage回归去找到可抓取的包围检测框。模型的表现性能比当前最先进的方法也要高出十四个百分点(我想这里应该说的是准确率)。同时可以在单张GPU上能达到每秒十三帧图像的性能。我们的网络可以在对物体进行分类的同时,也可以做到找出可抓取部位的检测矩形框。在这个模型上我们也做了一些修改,使它可以对单个物体上预测多个抓取部位,实现的方法是基于一个局部受限预测机制,基于该机制的模型表现更好,尤其是物体有多个抓取方式的时候。
一,介绍
I. INTRODUCTION
第一部分:介绍
Perception—using the senses (or sensors if you are a robot) to understand your environment—is hard. Visual perception involves mapping pixel values and light information onto a model of the universe to infer your surroundings. General scene understanding requires complex visual tasks such as segmenting a scene into component parts, recognizing what those parts are, and disambiguating between visually similar objects. Due to these complexities, visual perception is a large bottleneck in real robotic systems.
感知器,是一种传感器,或者也可理解为机器人的一些传感器,通过传感器采集得到的数据来对你当前环境进行理解。视觉感知可以让像素值以及光亮的信息建模,从而全局的推断出周围的环境。一般的场景理解需要复杂的视觉任务来完成比方说,将当前的这个场景分割成不同的区域部分,进而识别这些部分是什么。同时,在视觉层面上消除相似的物体,也就是视觉二义性。由于该任务异常复杂,所以对于真实环境下建立的机器人系统,视觉感知也是一个巨大的瓶颈。
General purpose robots need the ability to interact with and manipulate objects in the physical world. Humans see novel objects and know immediately, almost instinctively, how they would grab them to pick them up. Robotic grasp detection lags far behind human performance. We focus on the problem of finding a good grasp given an RGB-D view of the object.
通用目的的机器人在设计时,我们就希望他有能力可以在这个物理世界中对不同的物体进行交互,也就是说操纵他们,人类可以看新物体,可以迅速的理解而且本能地与他们交互,比方人类可以很自然的知道如何去抓取拿起之前没见到的物体。机器人对于检测物体的能力远远落后于人类的表现,我们专注于给机器人RGB-D的图像数据让机器人可以很好地去抓取事物。
We evaluate on the Cornell Grasp Detection Dataset, an extensive dataset with numerous objects and ground-truth labelled grasps (see Figure 1). Recent work on this dataset runs at 13.5 seconds per frame with an accuracy of 75 percent [1] [2]. This translates to a 13.5 second delay between a robot viewing a scene and finding where to move its grasper.
基于康奈尔抓取检测数据集,我们进行算法的评估,同时还有一个更大的有着更多物体和对应抓取标签的数据集(图1)。在该数据上的相关(查看第一和第二个参考文献)工作,可以达到75%的准确率,性能表现则是13.5秒/帧。这期间13.5秒的延迟主要在来自机器人查看该场景并用手去抓住其中的位置。

图1这个是康奈尔大学抓取数据集,该数据集包含了各种物体,每一个物体都有多个抓取标签。抓取标签形式是以2D矩形方框的形式给出的。
The most common approach to grasp detection is a sliding window detection framework. The sliding window approach uses a classifier to determine whether small patches of an image constitute good grasps for an object in that image. This type of system requires applying the classifier to numerous places on the image. Patches that score highly are considered good potential grasps.
最常用的抓取检测方法是通过滑动窗口在单帧图像进行检测。滑动窗口方法,是一种使用分类器来确定图像中的小块是否构成了该图像中的物体潜在可能的抓取部位。
We take a different approach; we apply a single network once to an image and predict grasp coordinates directly. Our network is comparatively large but because we only apply it once to an image we get a massive performance boost.
我们采取与以往不同的方法。我们使用一个神经网络在单张图像上预测抓取的坐标,网络相当大,但由于对单张图像只应用一次。得到了很好的性能提升。
Instead of looking only at local patches our network uses global information in the image to inform its grasp predictions, making it significantly more accurate. Our network achieves 88 percent accuracy and runs at real-time speeds (13 frames per second). This redefines the state-of-the-art for RGB-D grasp detection.
除了考虑局部的图像信息,网络也结合考虑全局的信息来做抓取位置预测。我们的网络达到了88%的准确率以及实时性能,也就是说每秒十三帧图像。我们也重新定义了使用RGB-D实现抓取检测的最新技术。
二,相关工作
II. RELATED WORK
第二部分:相关工作
Significant past work uses 3-D simulations to find good grasps [3] [4] [5] [6] [7]. These approaches are powerful but rely on a full 3-D model and other physical information about an object to find an appropriate grasp. Full object models are often not known a priori. General purpose robots may need to grasp novel objects without first building complex 3-D models of the object.
过去的方法中使用三维模拟去寻找好的抓取位置,其中比较重要的工作有第三个到第七个参考文献,这些方法都是非常有用的,但是是借助全3d模型以及其他关于当前物体的物理信息来找到一个合适的抓取位置。但这种方法并不适用于所有物体,也就是说要抓取的物体不能作为一个先验。通用目的的机器人也许需要抓取新的物体,也就是说他之前并未见到过的物体,没有建立过该物体的3d模型。
Robotic systems increasingly leverage RGB-D sensors and data for tasks like object recognition [8], detection [9] [10], and mapping [11] [12]. RGB-D sensors like the Kinect are cheap, and the extra depth information is invaluable for robots that interact with a 3-D environment.
机器人系统越来越多地利用RGB-D传感器等数据进行诸如物体识别[8],检测[9] [10]和映射[11] [12]等任务。 像Kinect这样的RGB-D传感器很便宜,而且与3-D环境交互的机器人的额外深度信息是无价的。
Recent work on grasp detection focusses on the problem of finding grasps solely from RGB-D data [13]. These techniques rely on machine learning to find the features of a good grasp from data. Visual models of grasps generalize well to novel objects and only require a single view of the object, not a full physical model [14] [2].
抓取检测的最新工作集中在仅从RGB-D数据中获取抓取的问题[13]。 这些技术依靠机器学习来查找特征,从数据中得到好的抓取预测。 抓取视觉模型对于新物体的泛化能力更强,只需单张物体的图像,而不是一个完整的物理模型[14] [2],就能预测出好的抓取位置。
Convolutional networks are a powerful model for learning feature extractors and visual models [15] [16]. Lenz et al. successfully use convolutional networks for grasp detection as a classifier in a sliding window detection pipeline [1]. We address the same problem as Lenz et al. but use a different network architecture and processing pipeline that is capable of higher accuracy at much faster speeds.
卷积网络的学习能里很强,作为特征提取器和视觉模型[15] [16]效果很好。 Lenz et al在滑动窗口检测流程中,成功使用卷积网络进行抓取检测作为分类器[1]。 我们也解决了与Lenz等人相同的问题。 但使用不同的网络架构和处理流程,能够以更快的速度获得更高的精度。
三,问题描述
III. PROBLEM DESCRIPTION
第三部分:问题描述
Given an image of an object we want to find a way to safely pick up and hold that object. We use the five dimensional representation for robotic grasps proposed by Lenz et al. [1]. This representation gives the location and orientation of a parallel plate gripper before it closes on an object. Ground truth grasps are rectangles with a position, size, and orientation:
通过一张图片我们想要找到如何握住这个物体的方法。我们用五个维度的数据表示机器人的抓取,该方法是Lenz et al.提出来的[1]。这种表示方法给出了两组平行的位置和方向信息(一个矩形框),最终的数据可以绘制成一个封闭的图形,也就是刚好能变成一个矩形。真实地抓取是一个有着某种姿态位置,尺寸,和方向的矩形。可用如下数学符号描述:
g = { x , y , θ , h , w } g= \{x,y,\theta,h,w\} g={x,y,θ,h,w}
where (x, y) is the center of the rectangle, θ is the orientation of the rectangle relative to the horizontal axis, h is the height, and w is the width. Figure 2 shows an example of this grasp representation.
其中(x,y)是这个矩形的中心,θ是矩形相对于水平方向的角度,h则是高度(注:这里应该说的是矩形的长),w是矩形宽度,图2展示使用抓取表示的例子。
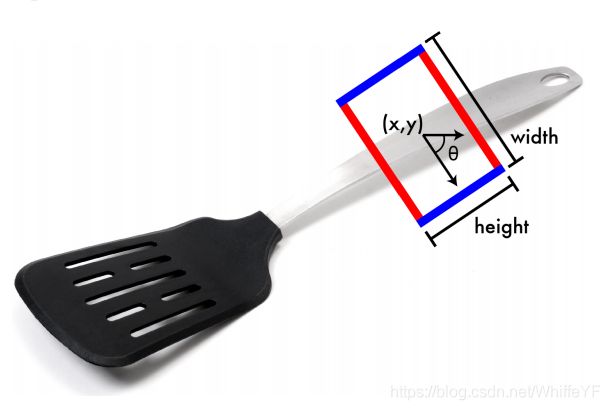
Fig. 2. A five-dimensional grasp representation, with terms for location,size, and orientation. The blue lines demark the size and orientation of the gripper plates. The red lines show the approximate distance between the plates before the grasp is executed.
图2五维度的抓取数据表示,其中包含位置,尺寸,方向等信息。蓝色的线条是尺寸,水平线的方向,红色线条的距离是执行抓取时候的宽度。
This is a simplification of Jiang et al.’s seven-dimensional representation [2]. Instead of finding the full 3-D grasp location and orientation, we implicitly assume that a good 2-D grasp can be projected back to 3-D and executed by a robot viewing the scene. Lenz et al. describe a process to do this and while they don’t evaluate it directly it appears to work well in their experiments [1].
这是七个维度抓取方法(该方法由Jiang et al提出 )的一种简化,我们没有使用完整的物体3d抓取的位置和方向信息,而是假设一个机器人查看这个场景的视角,假设二维图像的抓取,可以映射回到三维数据上。第二个参考文献等人描述了实现这一方法的过程,并且与此同时,他们并没有直接评估该方法,不过在他们的实验中,他们的方法表现很好。
Using a five-dimensional representation makes the problem of grasp detection analogous to object detection in computer vision with the only difference being an added term for gripper orientation.
使用了五个维度的数据表现形式,可以使这个抓取检测任务与计算机视觉的物体检测变得非常相像。有一点不同,就在于加入了抓取的方向。
四,使用神经网络进行抓取检测
IV. GRASP DETECTION WITH NEURAL NETWORKS
第四部分:使用神经网络进行抓取检测
Convolutional neural networks (CNNs) currently outper form other techniques by a large margin in computer vision problems such as classification [15] and detection [16]. CNNs already perform well on grasp detection when applied as a classifier in a sliding-window approach [1].
卷积神经网络比起传统的或者其他的,计算机视觉的模型来说,有着更好的表现效果,尤其是对于分类或者检测问题。卷积神经网络也已经在抓取检测问题当中得到了很好的应用,它作为滑动窗口过程中的一个分类器。
We want to avoid the computational costs of running a small classifier numerous times on small patches of an image. We harness the extensive capacity of a large convolutional network to make global grasp predictions on the full image of an object.
我们想要使用一个小的分类器,多次的在同一张图像上的不同的小块图像上面执行,希望这样可以避免计算量过大的问题。我们利用大卷积网络的大容量,可以使得在整幅图像上进行考虑全局的抓取预测。
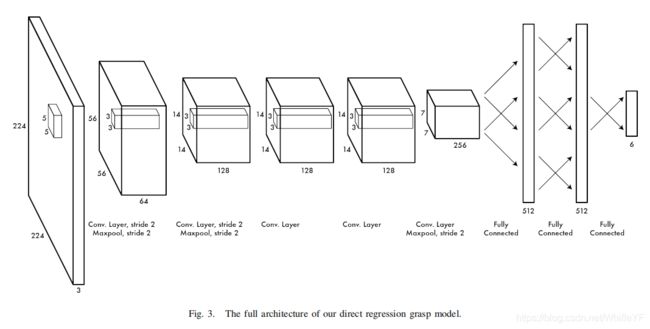
A. Architecture
a. 模型架构
When building our grasp detection system we want to start from a strong foundation. We derive our model from a version of the widely adopted convolutional network proposed by Krizhevsky et al. for object recognition tasks (AlexNet) [15].
当构建一个抓取检测系统,是我们希望从一个比较鲁莽的原始模型开始搭建,我们使用的模型是基于Krizhevsky et al.的物体识别任务的AlexNet卷积网络模型。
Our network has five convolutional layers followed by three fully connected layers. The convolutional layers are interspersed with normalization and maxpooling layers at
various stages. A full description of the architecture can be found in Figure 3.
我们的网络有五个卷积层,紧随其后的是三个全连接层,卷积层的不同层中使用normalization技术,以及maxpooling,关于这个架构的完整描述可以在图3中找到。
B. Direct Regression To Grasps
b. 直接回归抓取
The simplest model we explore is a direct regression from the raw RGB-D image to grasp coordinates. The raw image is given to the model which uses convolutional layers to extract features from the image. The fully connected layers terminate in an output layer with six output neurons corresponding to the coordinates of a grasp. Four of the neurons correspond to location and height. Grasp angles are two-fold rotationally symmetric so we parameterize by using the two additional coordinates: the sine and cosine of twice the angle.
我们发现的最简单模型,是基于对原始的RGBD图像数据直接回归去做坐标抓取。原始图像给卷积层后,卷积层会对原始图像进行特征提取。之后是六个神经元的输出(其中角度信息占2个,所以是6个输出)分别对应抓取的坐标信息等等,其中四个神经元对应着位置和高度信息,抓取的角度信息是双重旋转对称性,所以我们通过两个附加的坐标对角度参数化,也就是两倍角度的正弦和余弦。(Grasp angles are two-fold rotationally symmetric so we parameterize by using the two additional coordinates: the sine and cosine of twice the angle.)
This model assumes the strong prior that every image contains a single graspable object and it only needs to predict a one grasp for that object. This strong assumption may not hold outside of experimental conditions. In practice this model would have to come in a pipeline that first segments the image into pieces that only contain individual objects. The benefit of enforcing this assumption is that instead of classifying many of small patches in a sliding window type approach, we only need to look at a single image and make a global prediction.
这个模型有一个很强的假设,那就是每张图像只包含一个可以抓取的物体,并且对于那个物体,只需要预测一个抓取。这一较强的假设不能考虑到实验条件以外的情况,但是在实际中模型将会以一种流水线的形式执行,第一步对图像进行分割成不同的小块区域,这些小块区域包含了不同的物体。使用这一强假设的好处是不需要使用传统的滑动窗口的方法——对每一个小图像进行分类。我们只需要让模型观察一次图像,并做一个全局的预测就可以了。
During training our model picks a random ground truth grasp every time it sees an object to treat as the single ground truth grasp. Because the grasp changes often, the model does not overfit to a single grasp on an object. We minimize the squared error of the predicted grasp. The end effect is that our model fits to the average of the possible grasps for an object.
在模型训练中,对于看到的物体,每一次只随机选择该物体所有可抓取中的一次真实地抓取信息进行训练。因为抓取也是经常会发生变动的,这样模型就不会在一个物体上过拟合(注:相当于一种防止过拟合的策略,或者可以称为正则策略)。我们对物体抓取的平方误差进行最小化,最终的效果也就是模型对一个物体所有可能抓取的平均情况的一种拟合。
注释:然后直接回归的平均抓取在圆的物体上就表现不好了
C. Regression + Classification
c. 回归+分类
In order to use a grasped object the robot must first recognize the object. By extending our model we show that recognition and grasp detection can be combined into a single, efficient pipeline.
机器人要进行抓取物体的动作,第一步就需要对物体进行辨识。通过对我们模型的扩展,可以对识别和抓取检测的动作流程化。
We modify our architecture from the previous section by adding extra neurons to the output layer that correspond to object categories. We keep the rest of the architecture the same thus our model uses common features from the convolutional layers for both recognition and detection.
我们将上节(直接回归模型)中所提到的模型架构进行修改,在输出层加入了额外的神经元,新加入的神经元对应着物体的类别。剩下的架构与我们先前的模型保持一致,这样我们就可以使用与前文中所述一样的架构,既可以识别也可以检测。
This combined model processes an image in a single pass and predicts both the category of the object in the image and a good grasp for that object. It runs just as fast as the direct regression model because the architecture remains largely unchanged.
结合之后的模型在处理单张图片时,只需要一次正向传播,就可以预测出图像中物体的类别,以及对于该物体的一次抓取动作。因为模型的架构与前文中模型的架构并没有太大的改变, 模型执行速度与直接回归模型相同。
D. MultiGrasp Detection
d. 多抓取检测
注释:直接回归相当于在NxN的path上预测一次
Our third model is a generalization of the first model, we call it MultiGrasp. The preceeding models assume that there is only a single correct grasp per image and try to predict that grasp. MultiGrasp divides the image into an NxN grid and assumes that there is at most one grasp per grid cell. It predicts one grasp per cell and also the likelihood that the predicted grasp would be feasible on the object. For a cell to predict a grasp the center of that grasp must fall within the cell.
我们的第三种模型是对第一种模型的一种泛化,之前的模型都是假设对每张图像只有一个正确的抓取,并且预测那个抓取。而多抓取检测模型是将图像分成了NxN的网格,并且假设每一个网格内预测一个抓取(我的疑问:如何确定N的大小,后来想了想根据单张图像的ground truth label可以做到,但是作者并没有说这个N是固定的还是根据label的信息动态的调整的),并且预测物体上抓取是否可行,即预测抓取在网格中间的可能性。
The output of this model is an NxNx7 prediction. The first channel is a heatmap of how likely a region is to contain a correct grasp. The other six channels contain the predicted grasp coordinates for that region.
模型的输出结果是一个NxNx7的形式。第一个通道是一个热力图,这个热力图描述这个区域是否包含了一个正确抓取的可能。另外六通道包含了这次预测的抓取的坐标等具体信息。
注释:对于热力图的误差反向传播
For experiments on the Cornell dataset we used a 7x7 grid, making the actual output layer 7x7x7 or 343 neurons. Our first model can be seen as a specific case of this model with a grid size of 1x1 where the probability of the grasp existing in the single cell is implicitly one.
在康奈尔数据集上,我们的实验中使用了7×7的网格,输出层的形式是7×7×7(343个神经元)。第一个模型(直接回归模型)可以被视为一个网格尺寸是1×1的例子,各单元内抓取存在的概率是
Training MultiGrasp requires some special considerations. Every time MultiGrasp sees an image it randomly picks up to five grasps to treat as ground truth. It constructs a heatmap with up to five cells marked with ones and the rest filled with zeros. It also calculates which cells those grasps fall into and fills in the appropriate columns of the ground truth with the grasp coordinates. During training we do not backpropagate error for the entire 7x7x7 grid because many of the column entries are blank (if there is no grasp in that cell). Instead we backpropagate error for the entire heatmap channel and also for the specific cells that contain ground truth grasps.
训练多抓取模型需要一些额外考虑,每一次多次抓取需要观察一张图像的随机五个抓取作为真实抓取。热力图的构建是在这5个小格子内标注成1,剩下的格子填补0,此外也需要计算抓取会落在哪些格子,并且把真实抓取的其余具体数据信息填入适当的列中。因为大多数列都是空白的(即网格内没有真实抓取),所以即使有误差对应的7×7×7格子在训练过程也不会进行数值上的反向传播。反而对于整个热力图通道以及含有真实抓取的格子中,才进行误差的回传。
This model has several precursors in object detection literature but is novel in important aspects. Szegedy et al. use deep neural networks to predict binary object masks on images and use the predicted masks to generate bounding boxes [17]. The heatmap that we predict is similar to this object mask but we also predict full bounding boxes and only use the heatmap for weighting our predictions. Our system does not rely on post- processing or heuristics to extract bounding boxes but rather predicts them directly.
我们提出的物体检测模型是基于前人的一些工作的,但在一些重要的层面来说,这个模型也是新颖的。Szegedy et al在一张图像上使用深度神经网络,预测二进制的物体的掩码,并用预测出的掩码生成边界框[17]。我们预测出的热力图和物体掩码的方法非常相似,但是我们也预测完整的边界框,并用热力图去平衡预测的结果(only use the heatmap for weighting our predictions)。我们的整个系统不借助于后端处理或者用启发式的方法去得到边界框,而是直接预测。
Erhan et al. predict multiple bounding boxes and confidence scores associated with those bounding boxes [18]. This approach is most similar to our own, we also predict multiple bounding boxes and weight them by a confidence score. The key difference is the we enforce structure on our predictions so that each cell can only make local predictions for its region of the image.
Erhan et al提出的多边界框预测以及对应打分[18],该方法和我们的方法非常相似,我们也是预测多个边界框和对应分数来,最重要的不同在于我们的预测结构——每个单元格只对其图像局部区域预测。
五,实验和评估
V. EXPERIMENTS AND EVALUATION
Ⅴ.实验和评估
The Cornell Grasping Dataset [19] contains 885 images of 240 distinct objects and labelled ground truth grasps. Each image has multiple labelled grasps corresponding to different possible ways to grab the object. The dataset is specifically designed for parallel plate grippers. The labels are comprehensive and varied in terms of orientation, location, and scale but they are by no means exhaustive of every possible grasp. Instead they are meant to be diverse examples of particularly good grasps.
康奈尔抓取数据集包含了240种不同的物体,共计885张图片。它们都被标记了真实的抓取标记,每一张图片都包含多个抓取标记,对应抓取该物体的不同方式,这个数据集是专门为机器人的平行板夹机器手设计的。这些标记在方向、位置和抓取规模方面都是全面且多样的,但并不是详尽无遗的。只是包含了不同样式的恰当合适的抓取。
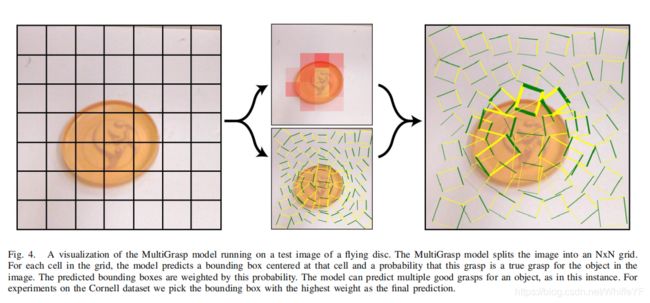
图4. 多抓取模型在测试图像(飞碟)上的可视化。多抓取模型将一幅完整的图像切分成NxN的网格,对于每一个网格,模型在网格的中心预测是否有抓取包围边界框的概率。可视化时是以该边界框的粗细来表示它的概率。例如,模型选择概率最高的值的边界框作为最终抓取。
A. Grasp Detection
A. 抓取检测
Previous work uses two different metrics when evaluating grasps on the Cornell dataset. The point metric looks at the distance from the center of the predicted grasp to the center of each of the ground truth grasps. If any of these distances is less than some threshold, the grasp is considered a success.
之前的工作是用两种不同的方法在康奈尔数据集上进行抓取工作的评估。点测量的评估方法是在计算距离,计算预测的抓取的中心距离真实抓取的中心的距离,如果这些距离中任意一个小于某一个阈值,那么这次抓取就被被视为一次成功抓取。
There are a number of issues with this metric, most notably that it does not consider grasp angle or size. Furthermore, past work does not disclose what values they use for the threshold which makes it impossible to compare new results to old ones. For these reasons we do not evaluate on the point metric.
然而对于这种测量方法也有很多的问题。因为它没有考虑到抓取的角度或者大小,进一步说之前的工作也并没有说明采取的阈值是多少,这也是为什么我们没有采用这种点来测量进行评估的方法。
The second metric considers full grasp rectangles during evaluation. The rectangle metric considers a grasp to be correct if both:
第二种测量方法考虑的是一个完整的抓取矩形,一次成功抓取需要保证以下是正确的:
1) The grasp angle is within 3 0 ◦ 30^◦ 30◦ of the ground truth grasp.
1)预测抓取角度与真实抓取的角度在30度以内
2) The Jaccard index of the predicted grasp and the ground truth is greater than 25 percent.
预测抓取比真实抓取的Jaccord index大25%
Where the Jaccard index is given by:
其中,计算公式如下:
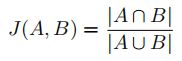
The rectangle metric discriminates between good and bad grasps better than the point metric. It is similar to the metrics used in object detection although the threshold on the Jaccard index is lower (25 percent instead of a more standard 50 percent in computer vision) because the ground truth grasps are not exhaustive. A rectangle with the correct orientation that only overlaps by 25 percent with one of the ground truth grasps is still often a good grasp. We perform all of our experiments using the rectangle metric.
矩形测量方法在对于好的和不好的抓取时,它的效果要比点测量的估计方法要更好一些,这种测量方法相比相似的物体检测的评估方法,设定的Jaccord index是25%,还是比较低的。这里的25%,并不是计算机视觉中更标准常见的50%。这也是因为真实的抓取并不是非常详尽的缘故导致的。如果预测的矩形框与实际正确抓取的方向有25%的重叠,那么我们也认为这次预测的抓取仍是一个好的抓取结果。我们在所有的实验中都使用了矩形测量评估的方法。
Like prior work we use five-fold cross validation for our experimental results. We do two different splits of the data:
与之前的工作一样,我们在实验的结果计算上也使用了五折交叉验证集。我们使用两种不同的方法对数据进行split。
1) Image-wise splitting splits images randomly.
2) Object-wise splitting splits object instances randomly, putting all images of the same object into the same cross-validation split.
1)逐图片split,将图片随机split。
2)逐个物体split,对一个问题事例随机分开,将所有图像中相同的物体分到相同的交叉验证集的split中。
Image-wise splitting tests how well the model can generalize to new positions for objects it has seen previously. Object wise splitting goes further, testing how well the network can generalize to novel objects. In practice, both splitting techniques give comparable performance. This may be due to the similarity between different objects in the dataset (e.g. there are multiple sunglasses of slightly different shapes and colors).
逐图像的split在测试的时候可以验证模型的泛化能力(对于见过的物体但不同角度的时候);逐个物体的split在做交叉验证可以更进一步地测试网络对于新物体的泛化能力。在实际应用中,上述的两种方法具有一定的等价性,可能是由于数据集中的一些物体具有一定的相似性。(例如不同的太阳镜在形状和颜色上也只是稍许不同)
B. Object Classification
B. 物体分类
We manually classify the images in the Cornell Grasping Dataset into 16 distinct categories, with categories like “bottle”, “shoe”, and “sporting equipment”. The dataset is not evenly distributed between categories but every category has enough examples in the dataset to be meaningful. The least represented category has 20 images in the dataset while the most represented has 156.
我们人工地对康奈尔抓取数据集的图像分成了十六种不同的类别,比方说有瓶子,鞋子,运动器械等等。康奈尔原始数据集中各种类的图像张数的分布差距很大,即每类样本数量并不是相同的,但是每一种类别的图像都有足够的数目表示本身的含义。图像张数最小的那个种类只有20张,但最多图像的种类有156张。
We train and test our combined regression + classification model using these class labels. At test time the combined model simultaneously predicts the best grasp and the object category. We report classification accuracy on the same cross-validation splits as above.
我们使用这些类别标记训练并测试了结合了回归和分类的模型。在测试时间上,结合后的回归分类模型可以预测最佳抓取的同时预测物体种类。我们在上述相同的交叉验证的分割方法中,已经报告了分类的准确率。
C. Pretraining
C. 预训练
Before training our network on grasps we pretrain on the ImageNet classification task [20]. Our experience backed by current literature suggests that pretraining large convolutional neural networks greatly improves training time and helps avoid overfitting [21] [22].
在抓取数据集上训练我们的网络之前,我们先在ImageNet的分类任务上进行了预先的训练[20]。现有文献中的经验表明,通过对大的卷积神经网络进行预训练,可以大大减少训练时间,有助于避免过拟合[21][22]。
Krizevsky et al. designed AlexNet for standard RGB images. Low-cost stereo vision systems like the Kinect make RGB-D data increasingly ubiquitous in robotic systems. To use AlexNet with RGB-D data we simply replace the blue channel in the image with the depth information. We could instead modify the architecture to have another input channel but then we would not be able to pretrain the full network.
Krizevsky et al.设计了针对标准RGB图像的AlexNet,像Kinect这样的低成本立体视觉系统可以使RGB-D数据在机器人系统中不断增加。但是如果要使用AlexNet和RGB-D数据,我们只需要用深度信息替换图像中原本的蓝色通道,这样修改后的架构可以具有另一个输入通道,但是无法预训练完整的网络。
Pretraining is crucial when there is limited domain-specific data (like labeled RGB-D grasps). Through pretraining the network finds useful, generalizable filters that often translate well to the specific application [22]. Even in this case where the data format actually changes we still find that the pretrained filters perform well. This may be because good visual filters (like oriented edges) are also good filters in depth space.
当领域数据很限时,预训练是非常重要的。通过对模型进行预先训练,可以使网络找到更有用,更具泛化能力的滤波器,这样可以更好的将原始数据转化为特定应用[22]。即使在数据格式和实际的输入有变化的情况下,仍然发现预训练的滤波器的性能还不错,这可能是因为训练过的视觉滤波器也是深度空间中好的滤波器。
D. Training
D. 训练
We undertake a similar training regimen for each of the models we tested. For each fold of cross-validation, we train each model for 25 epochs. We use a learning rate of 0.0005 across all layers and a weight decay of 0.001. In the hidden layers between fully connected layers we use dropout with a probability of 0.5 as an added form of regularization.
我们针对每个城市的模型进行类似的训练方案。对于交叉验证的每个折叠,每个模型都是用25个epoch,学习率0.0005,权重衰减0.001,在全链接层的隐含层中,使用0.5的dropout概率作为正则化的附加形式。
For training and testing our models we use the cuda-convnet2 package running on an nVidia Tesla K20 GPU. GPUs offer great benefits in terms of computational power and our timing results depend on using a GPU as part of our pipeline. While GPUs are far from a mainstay in robotic platforms, they are becoming increasingly popular due to their utility in vision tasks.
在对模型进行训练和测试时候,我们使用Tesla K20显卡和cuda-convet2包计算。GPU提供了强大的计算能力,其运算到时间也是我们整个流程的一部分。虽然这GPU在机器人平台方面不是主流,但由于其在视觉任务中的实用性,它越来越受欢迎。
E. Data Preprocessing
E. 数据预处理
We perform a minimal amount of preprocessing on the data before feeding it to the network. As discussed previously, the depth information is substituted into the blue channel of the image. The depth information is normalized to fall between 0 and 255. Some pixels lack depth information because they are occluded in the stereo image; we substitute 0 for these pixel values. We then approximately mean-center the image by globally subtracting 144.
在数据给网络之前,我们需要对数据进行少量的预处理操作,如前文中所述深度信息,被放入了图像中的蓝色通道,深度信息同时也被重新映射在0到255之间,由于一些像素缺少深度信息,他们被遮挡在立体图像中,所以用0来代替这些像素值,之后再对每张图像减去像素平均中心(approximately mean-center the image)144。
When preparing data for training we perform extensive data augmentation by randomly translating and rotating the image. We take a center crop of 320x320 pixels, randomly translate it by up to 50 pixels in both the x and y direction, and rotate it by a random amount. This image is then resized to 224x224 to fit the input layer of our architecture. We generate 3000 training examples per original image. For test images we simply take the center 320x320 crop and resize it without translation or rotation.
在这之后我们对数据平移和旋转,从而扩增图像数据。我们取出原始图像中心320×320像素大小的区域。在xx和yy方向上,将其旋转50个像素,并再旋转一个随机像素数。之后把图像重新缩放成224×224的大小,这样就可以适用于网络的输入层。对于原始图像,我们生成了三千个训练样本(比例是1:3000),在测试图像上,我们只是简单取出原始图像中心的320×320区域,并缩放到网络的输入尺寸,没有平移和旋转操作。
六,结果
VI. RESULTS
Ⅵ. 结果
Across the board our models outperform the current state-of-the-art both in terms of accuracy and speed. In Table I we compare our results to previous work using their self-reported scores for the rectangle metric accuracy.
我们的模型无论是在准确性还是速度方面,是目前最先进的。
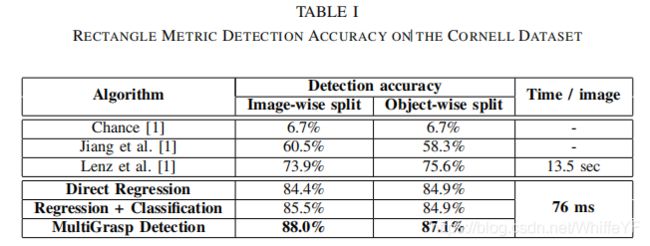
The direct regression model sets a new baseline for performance in grasp detection. It achieves around 85 percent accuracy in both image-wise and object-wise splits, ten percentage points higher than the previous best. At test time the direct regression model runs in 76 milliseconds per batch, with a batch size of 128 images. While this amounts to processing more than 1,600 images per second, latency matters more than throughput in grasp detection so we report the per batch number as 13 fps. The main source of this speedup is the transition from a scanning window classifier based approach to our single-pass model and our usage of GPU hardware to accelerate computation. 76 milliseconds per frame is certainly achievable on a CPU because it would require only 1/128th of the floating point operations required for processing a full batch on a GPU.
我们将结果和以前的工作使用矩形度量法得到的准确率相比较。直接回归模型在抓取检测任务中,得到了一个新的基准线,在逐个图像和逐个物体的交叉验证上达到了大约85%的准确率,比之前版本的最高准确率要高出十个百分点。在测试时,也就是计算一次正向的直接回归模型,对于每一个批次的处理在76毫秒,每一个批次(batchsize)有128张图像。也就是说,每秒钟会处理超过1600张的图像,延迟在整个抓取检测的过程所占用的时间非常的多,以至于每一秒钟只能处理13帧(每次使用1张图像和128张所需要的时间相同)。得到加速的主要是由原本的扫描滑动窗口的分类模型,转换为我们的单次传播模型,并且使用GPU硬件进行计算加速。对于在GPU上的一个完整的批次计算,这里只需要原本1/128的浮点计算操作,CPU无疑至少需要76毫秒(这里没太理解这句话,76 milliseconds per frame is certainly achievable on a CPU because it would require only 1/128th of the floating point operations required for processing a full batch on a GPU)。
The direct regression model is trained using a different random ground truth grasp every time it sees an image.Due to this it learns to predict the average ground truth grasp for a given object. Predicting average grasps works well with certain types of objects, such as long, thin objects like markers or rolling pins. This model fails mainly in cases where average grasps do not translate to viable grasps on the object, for instance with circular objects like flying discs. Figure 5 shows some examples of correct and incorrect grasps that the direct regression model predicts.
在直接回归模型的训练过程当中,我们每一次针对每张图像都是用随机的真实抓取,而不是该图像的所有真实抓取。因为这个缘故,所以模型学到的预测是物体的一个平均真实抓取。对于某些种类的物体预测平均抓取非常有效,例如,形状上比较长且细的物体如马克笔。该模型大多数失败的主要原因是平均抓取并不能转换成一种切实可行的抓取,例如一些圆形的物体,如飞碟。图5展示了一些正确和不正确的抓取,这些都是使用直接回归模型进行预测的。


图5 直接回归模型的正确(顶部)和不正确(底部)示例。一些不正确的抓取(例如罐头开瓶器)可能实际上是可行的,而其他的(例如碗)显然是不可行的。
The combined regression + classification model shows that we can extend our base detection model to simultaneously perform classification without sacrificing detection accuracy; see Table II for classification results. Our model can correctly predict the category of an object it has previously seen 9 out of 10 times. When shown novel objects our model predicts the correct category more than 60 percent of the time. By comparison, predicting the most common class would give an accuracy of 17.7 percent.
结合了回归和分类的模型展示了在检测模型的基础之上,还可在不牺牲检测精度的同时进行分类;表2是该模型的分类结果。当我们的模型已经看到该物体9次或10次时,他就可以正确地预测出物体的类别,但是当给出一个新的物体时,准确率只有60%。相比最常见的类别占总数据集的比例来说,用占比最多的类别进行预测,准确率有17.7%。
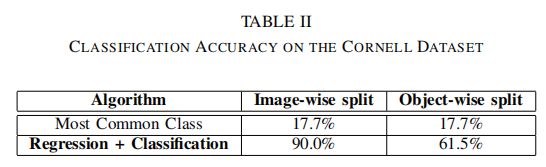
表2. 在康奈尔数据集上的分类准确率
Even with the added classification task the combined model maintains high detection accuracy. It has identical performance on the object-wise split and actually performs slightly better on the image-wise split. This model establishes a strong baseline for combined grasp detection and object classification on the Cornell dataset.
即使加入了分类任务结合之后的模型,仍然保持高检测准确率。之前逐对象的交叉验证集上有同样的性能,比之前逐图像交叉验证事后的性能还要稍微好一些,这个结合了抓取检测和物体分类后的模型,在康奈尔数据集上建立了更好的性能基准线。
The MultiGrasp model outperforms our baseline direct regression model by a significant margin. For most objects MultiGrasp gives very similar results to the direct regression model. However, MultiGrasp does not have the same problem with bad average grasps that the direct regression model has which accounts for most of the error reduction. Figure 6 shows examples of MultiGrasp outperforming the direct regression model and examples where both models fail.
多抓取模型要比直接回归模型的基准线要好一大截。多抓取模型在对于大多数物体与直接回归模型得到的结果非常相似,然而多抓取模型并没有直接回归模型的较差的平均抓取的问题(这也是为什么多抓取模型能够减少大多数错误的原因)。图6展示了多抓取模型比直接回归模型要好的几个例子,以及在这两个模型上都出现失败的例子。
MultiGrasp has a very similar architecture to the direct regression model and operates at the same real-time speeds. With a grasp detection accuracy of 88 percent and a processing rate of 13 frames per second, MultiGrasp redefines the state-of-the-art in robotic grasp detection.
多次抓取模型与直接回归模型有相似的架构,以及相似的实时处理速度。多抓取模型在机器人抓取检测方面保持世界领先,检测准确率为88%,性能为13帧/秒。
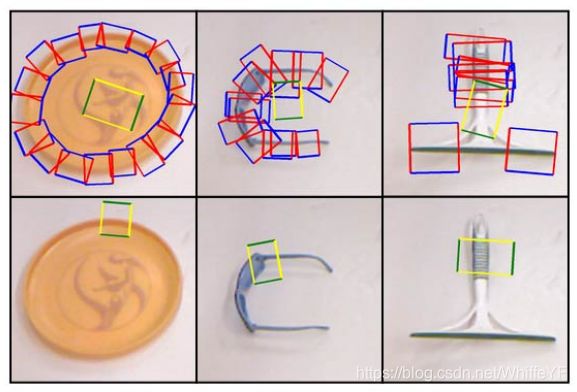


图6 直接回归模型和MultiGrasp的性能比较。前两行显示了直接回归模型由于平均效应而失败的示例,但MultiGrasp预测了可行的掌握。底部的两行显示了两个模型都无法预测好抓握的示例。直接回归模型图像上的蓝色和红色展示出真实的抓握。
七,讨论
VII. DISCUSSION
Ⅶ. 讨论
We show that robot perception can be both fast and highly accurate. GPUs provide a large speed boost for visual systems, especially systems based on convolutional neural networks. CNNs continue to dominate other techniques in visual tasks, making GPUs an important component in any high performance robotic system. However, GPUs are most vital during model training and are optimized for throughput, not latency. At test time a CPU could run our model in far less than a second per image, making it viable in real-time robotics applications.
我们提出了在保证速度和高准确率下的模型。计算显卡提供了强大的计算能力,尤其是基于卷积神经网络的。在视觉任务上,卷积神经网络一直在统治着相关的技术。这也是计算显卡成为任何高性能机器人系统的一个重要组件的原因。计算显卡在模型训练中非常重要以及整个过程中都有优化,然而却有着很大的延迟。在测试时,CPU可以少于一秒的处理单张图像,这可以使机器人应用实时化。
Model consideration is important for achieving high performance. We take advantage of a strong constraint on the data so that our model only needs a single pass over an image to make an accurate grasp prediction.
从模型层面上考虑对实现高性能来说是非常重要。为了图像在模型中单次上处理就可以完成准确的抓取预测,我们对数据进行强约束。
Our direct regression model uses global information about the image to make its prediction, unlike sliding-window approaches. Sliding window classifiers only see small, local patches thus they can not effectively decide between good grasps and are more easily fooled by false positives. Lenz et al. report very high recognition accuracy for their classifier (94%) yet it still falls victim to this false positive paradox and its detection accuracy is much lower as a result. In this respect, global models have a large advantage over models that only see local information.
与滑动窗口的方法不同,直接回归模型使用了图像上的全局信息进行预测。滑动窗口分类器只能看到较小的局部的图像,因此他们不能在一堆候选抓取结果中做出有效的决定,而且很容易被假阳性的样本所迷惑。Lenz et al.报告他们的分类器有很高的识别率,(94%) ,然而对于假阳性样本来说,其检测精度要低很多,在这一方面与只能看到局部信息的模型相比,考虑全局的模型具有很大的优势。
Global models also have their downside. Notably our direct regression model often tries to split the difference between a few good grasps and ends up with a bad grasp. A sliding window approach would never make the mistake of predicting a grasp in the center of a circular object like a flying disc.
考虑全局的模型也有其缺点,值得注意的是,直接回归模型通常会在几个好的抓取之间进行差异化(注:这里我理解不是差异化,而是平均化),很最后预测出不正确的抓取,然而滑动窗口方法永远不会造成在圆形物体上预测中心位置的错误抓取,比方飞盘。
Our MultiGrasp model combines the strongest aspects of global and local models. It sees the entire image and can effectively find the best grasp and ignore false positives. However, because each cell can only make a local prediction, it avoids the trap of predicting a bad grasp that falls between several good ones.
我们的多抓取模型结合了只考虑全局和局部信息这两种模型的优势。他会观察整幅图像并找到最佳抓取,并忽略假阳性样本,然而因为图像上每个单元格会做局部预测,这也可以避免陷入不好抓取的预测陷阱。
The local prediction model also has the ability to predict multiple grasps per image. We are unable to quantitatively evaluate the model in this respect because no current dataset has an appropriate evaluation for multiple grasps in an image.In the future we hope to evaluate this model in a full detection task, either for multiple grasps in an image or on a more standard object detection dataset.
考虑局部的模型也有在单幅图像上预测多个抓取的能力。因为目前没有哪些数据集可以对单张图像预测多抓取的合适评估,所以我们没能给出一种定量评估该模型的方法。在未来,我们希望在一个完整的检测任务中评估这个模型,无论是对图像的多次抓取,还是对一个更标准的对象检测数据集。
One further consideration is the importance of pretraining when building large convolutional neural networks. Without pretraining on ImageNet, our models quickly overfit to the training data without learning meaningful representations of good grasps. Interestingly, pretraining worked even across domains and across feature types. We use features tuned for the blue channel of an image on depth information instead and still get good results. Importantly, we get much better results using these features on the depth channel than using them on the original RGB images.
另一个重点考虑是在于构建大规模卷积神经网络时,预训练的重要性。如果没有在ImageNet数据集上进行预训练,模型很快的会在训练数据集上过拟合,更不会学习出好的抓取的特征表示。有趣的是,预训练在不同的领域以及特征类型上都有效果。我们对原本的模型中的蓝色通道,用深度信息将其替换,仍然得到了不错的结果。重要的是,使用深度信息的通道比起原本只用三种颜色的图像通道来说,得到了更好的结果。
八,总结
VIII. CONCLUSION
Ⅷ. 总结
We present a fast, accurate system for predicting robotic grasps of objects in RGB-D images. Our models improve the state-of-the-art and run more than 150 times faster than previous methods. We show that grasp detection and object classification can be combined without sacrificing accuracy or performance. Our MultiGrasp model gets the best known performance on the Cornell Grasping Dataset by combining global information with a local prediction procedure.
我们提出了一种快速,高准确的系统,用来预测机器人处理RGB-D的图像数据进行物体抓取。模型达到世界领先水平,并比先前的方法提高了150倍。我们也展现了在不损失精度和性能的前提下,可以将抓取检测和物体分类的模型进行结合。多抓取模型在康奈尔抓取数据集上,通过结合全局的信息,可以进行局部预测,并达到当前已知的最佳性能。
参考:
【论文链接】:Real-Time Grasp Detection Using Convolutional Neural Networks
【知乎】:Real-Time Grasp Detection Using Convolutional Neural Networks
【复现代码】:grasp_regression