7. 后端
- 滤波器后端
- BA与图优化
- Pose Graph
声明:本文是深蓝学院 高翔博士主讲的《SLAM理论与实践》的学习笔记。
早期主要使用滤波器,后来发展到优化为主(滤波器类似计算机视觉中的传统方法 BA类似于DL方法 )。
- 滤波器:计算量少, 计算资源不充足的场景可以考虑。 例如VIO VIO中变量的维数太高了(计算量大), 而且一般是低端器件, 用BA不太合适,一般使用滤波器

- d
早期滤波器怎么来的?
滤波器后端
后端(Backend):从带噪声的数据估计内在状态——状态估计问题 (Estimated the inner state from noisy data) 用u,z推断x,y (x是R,t , y是地图路标点) 
求解方法:
渐进式(Incremental 也叫 recursive)
- 保持当前状态的估计(根据上一时刻估计当前时刻? 预测丢失信息),在加入新信息时(新的观测? 观测获取信息),更新已有的估计(滤波) 。 【有时候不仅仅使用上一帧,而是使用前M帧, 当新的一帧获取之后更新这个Mini-batch内的状态
 这是一种介于滤波和batch之间的做法, 滤波只更新当前帧的状态】
这是一种介于滤波和batch之间的做法, 滤波只更新当前帧的状态】 - 线性系统+高斯噪声=卡尔曼滤波器
 在线性的、高斯噪声系统中卡尔曼滤波器是最优的无偏估计
在线性的、高斯噪声系统中卡尔曼滤波器是最优的无偏估计 - 非线性系统+高斯噪声+线性近似=扩展卡尔曼: (相机模型属于非线性系统)
- 非线性系统+非高斯噪声+非参数化=粒子滤波器 (维度会随着状态变量指数级增长,SLAM中状态变量很多一般无法使用粒子滤波)
- Sliding window filter & multiple state Kalman (MSCKF): 由于EKFZ只维护当前状态的均值方差(近似太多,不太合理),因此在5-7个帧里面做KF
- 保持当前状态的估计(根据上一时刻估计当前时刻? 预测丢失信息),在加入新信息时(新的观测? 观测获取信息),更新已有的估计(滤波) 。 【有时候不仅仅使用上一帧,而是使用前M帧, 当新的一帧获取之后更新这个Mini-batch内的状态
批量式(Batch):给定一定规模的数据,计算该数据下的最优估计(优化)。 例如无人机上面的相机先拍了一个视频和采集了一些传感器数据,希望绘制出城市地图
运动方程和观测方程可以用一个直观的例子理解:
当我们蒙着眼走路时(对应运动方程, 每一次运动都会丢失信息, 例如使用轮式里程计 会存在累计误差):
- 一开始我们知道自己在哪
- 能粗略估计每步的距离,但不确定
- 不确定性随时间累积导致自身的位置不确定性越来越大
某个时刻睁开眼睛时(对应观测方程,每一次观测都会获取新的信息,增加对状态估计的确定性, 例如)
- 能够观测到周围
- 尽管也有不确定性,但比估计步长小很多
- 能够将不确定性保持在一定范围内
每一次运动都会先丢失信息(PREDICTION: 运动方程的估计会有偏差增加噪声,只能确定大致范围,方差增大),然后通过观测增加确定性( UPDATE:因为观测的不确定性较小,可以修正运动估计的误差,方差减小)。

同理,可以用渐进式和批量式两种方式描述这个过程
实际上SLAM的问题还要难一些,它面对的是未知环境, 观测的路标点 事先并不确定位置(不像你在自己家里熟悉某一幅画的具体位置) ,而是一边走一边把路标地图建立出来的。
数学描述
通过数学描述能否看出,滤波器与优化方法之间 的联系与区别。
t = 0 … N 时间内,机器人的位姿为 x0...xn x 0 . . . x n 同时有路标 y1,y2...ym y 1 , y 2 . . . y m : 运动和观测方程记为: 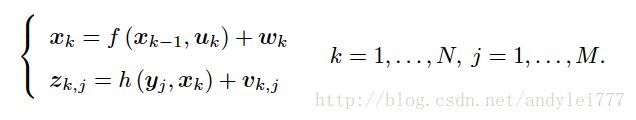
注意:运动和观测都受噪声影响;纯视觉SLAM(比如手持相机)就没有运动方程
推导卡尔曼滤波
我们从贝叶斯滤波器方法来推导卡尔曼滤波
- 用随机变量表示状态(状态主要包括姿态x和路标点位置y, 高斯分布的随机变量包含均值和方差,不确定性体现在随机方差上),估计其概率分布。
- k时刻所有待估计的量组成k时刻状态:

- k时刻观测统一记成 zk z k 方程简化为:
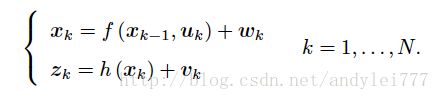
- 根据过去0时刻到k时刻的数据估计当前的状态
 (其中x_0作为初始位置状态已知(一般以相机开机的地方作为坐标系), u是每次运动的观测值(比如轮式里程计观测的 里程), z是路标的观测值(例如路标点的像素坐标) 注意x_k包括姿态和路标点两种状态 )
(其中x_0作为初始位置状态已知(一般以相机开机的地方作为坐标系), u是每次运动的观测值(比如轮式里程计观测的 里程), z是路标的观测值(例如路标点的像素坐标) 注意x_k包括姿态和路标点两种状态 ) - Bayes展开:

- 似然部分可由观测方程( zk=h(xk)+vk z k = h ( x k ) + v k )给出 分布形式 (假设观测方程中 vk∼N(0,Q) v k ∼ N ( 0 , Q ) 则 zk∼N(h(xk),Q) z k ∼ N ( h ( x k ) , Q ) )
- 先验部分可由运动方程给出,推导过程如下: 首先按条件概率展开:
 注意先验部分的组成:
注意先验部分的组成: 分歧:
分歧:
可以假设k时刻状态只和k-1时刻有关(假设了一阶马尔可夫性)
或假设k时刻状态与先前所有时刻均有关(不假设马尔可夫性)。
- 在假设一阶马尔可夫性的情况下(可有运动方程给出分布): 当前运动姿态之与 前一次姿态 xk−1 x k − 1 (前一次位置)、当前运动观测值 uk u k (例如轮式里程计给出的这段时间行驶的里程)有关,与初始状态和路标点观测值无关。 第一项(对应于运动方程):
 。 第二项
。 第二项  形成了一个递归!
形成了一个递归! - 于是,该公式指出了如何从k-1时刻的状态分布递推至k时刻的分布。只是现在我们还没有代入具体的分布形式。 这叫做预测 PREDICTION, 也就是说根据前一状态对当前状态做出的预测 作为先验值。
 (有了先验 再乘以 观测方程给出的似然就得到了修正后的最终结果)
(有了先验 再乘以 观测方程给出的似然就得到了修正后的最终结果)
- 在假设一阶马尔可夫性的情况下(可有运动方程给出分布): 当前运动姿态之与 前一次姿态 xk−1 x k − 1 (前一次位置)、当前运动观测值 uk u k (例如轮式里程计给出的这段时间行驶的里程)有关,与初始状态和路标点观测值无关。 第一项(对应于运动方程):
有了以上结果之后可以带入具体的分布形式。
在线性模型、高斯状态分布下,我们将得到卡尔曼滤波器
卡尔曼滤波器的推导: 运动方程和观测方程采用线性模型。
线性模型和高斯噪声
- 根据运动方程进行预测(得到先验):
如果假设k-1状态的高斯分布(区别先后验) 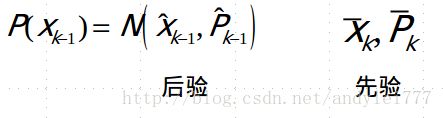
那么预测(k-1时刻后验通过运动方程推算k时刻先验) :  并记成
并记成 ![]() 需要用到高斯分布的线性组合性质。 而且由于假设 xk−1 x k − 1 已知直接可得 P(xk|x0,u1:k,z1:k−1)=P(xk|xk−1,x0,u1:k,z1:k−1)=P(xk|xk−1,uk) P ( x k | x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k | x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k | x k − 1 , u k )
需要用到高斯分布的线性组合性质。 而且由于假设 xk−1 x k − 1 已知直接可得 P(xk|x0,u1:k,z1:k−1)=P(xk|xk−1,x0,u1:k,z1:k−1)=P(xk|xk−1,uk) P ( x k | x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k | x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k | x k − 1 , u k )
? 就不需要求解下面的积分 ?
预备知识:高斯分布的线性变换

根据观测方程,得到似然 :
 为什么不是 P(zk|xk)=N(Ckxk¯¯¯¯¯,CkPk¯¯¯¯¯¯CTk+Q) P ( z k | x k ) = N ( C k x k ¯ , C k P k ¯ C k T + Q ) ? 因为假设x已知?把x_k当常量?
为什么不是 P(zk|xk)=N(Ckxk¯¯¯¯¯,CkPk¯¯¯¯¯¯CTk+Q) P ( z k | x k ) = N ( C k x k ¯ , C k P k ¯ C k T + Q ) ? 因为假设x已知?把x_k当常量?根据前面的Bayes展开:
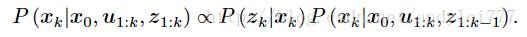 需要计算两个分布的乘积 技巧:已经两侧均是高斯分布,所以
需要计算两个分布的乘积 技巧:已经两侧均是高斯分布,所以  既然都是高斯分布,我们比较指数部分的二次项和一次项部分即可。 指数部分展开 类别于scale形式的 (x−u)2/2σ ( x − u ) 2 / 2 σ :
既然都是高斯分布,我们比较指数部分的二次项和一次项部分即可。 指数部分展开 类别于scale形式的 (x−u)2/2σ ( x − u ) 2 / 2 σ : 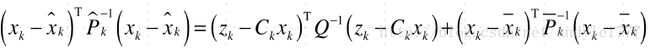 比较 xK x K 的二次和一次项系数,对于二次项,有
比较 xK x K 的二次和一次项系数,对于二次项,有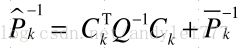 再考虑一次项 比较一次项系数:
再考虑一次项 比较一次项系数: 整理之
整理之  两侧同乘 Pk^ P k ^ 并定义
两侧同乘 Pk^ P k ^ 并定义 得
得 称为卡尔曼滤波的更新式
称为卡尔曼滤波的更新式对先验的均值加上一个修正量(卡尔曼增益×观测误差) 就得到后验的均值。
小结:
 根据SWB恒等式可知其中K与前面的K是等价的。 经典卡尔曼滤波器的五个公式,给出了线性高斯系统的最优无偏估计
根据SWB恒等式可知其中K与前面的K是等价的。 经典卡尔曼滤波器的五个公式,给出了线性高斯系统的最优无偏估计
- 根据运动方程做预测(求先验)
- 根据观测方程做更新(乘似然 等效为 卡尔曼滤波增益进行更新)
卡尔曼滤波器的假设:
- 假设了状态变量和噪声都是高斯分布
- 假设一阶马尔可夫性
在非线性模型、高斯状态分布下,可以在工作点附近线性展开,得到扩展卡尔曼滤波器
Kalman Filter的非线性扩展:EKF
当f,h为非线性函数时
在工作点附近进行一阶Taylor展开:  工作点附近使用线性系统近似
工作点附近使用线性系统近似 
预测部分:
卡尔曼增益: 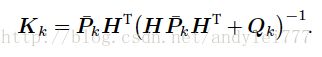
更新部分: 
EKF优点
- 推导简单清楚,f和h都是抽象的非线性函数,适用各种传感器形式
- 易于做多传感器融合
EKF缺点
- 一阶马尔可夫性过于简单(例如:无法有效处理回环情况
 )
) - 可能会发散(要求数据不能有outlier 误匹配)
- 线性化误差
- 需要存储所有状态量的均值和方差,平方增长
还有一个问题是 高斯分布经过线性变换还是高斯分布但是经过非线性变换之后不一定还是高斯,这时候如果仍然使用高斯进行近似可能会出现问题。 这与系统的非线性程度有关
BA与图优化
习题里有一篇有名的综述。
Bundle Adjustment已经在之前介绍过了
事实上BA属于批量式的优化方法
给定很多个相机位姿与观测数据,计算最优的状态估计
定义每个运动/观测方程的误差,并从初始估计开始寻找梯度下降
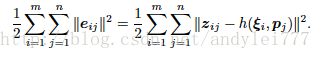 factor graph的优化
factor graph的优化

BA问题与图结构的关系
BA虽然是个纯优化问题,但亦可以用图模型清晰地表述出来
顶点为优化变量,边为运动/观测约束
本身还有一些特殊的结构
特点:
每个观测只关系两个变量,其中一个是相机,一个是路标
纯视觉BA中,不存在相机与相机/路标与路标之间的关联
整个误差函数由许多个这样小的项组成
考虑在位姿 i 处对路标 j 的一次观测 zij: ![]()
根据Gauss-Newton或Levernburg-Marquardt,最终我们会求解 Hx=-b 形式的方程
每一个误差项会对整体线程方程产生贡献:
而误差仅和i,j相关,导致它的雅可比为稀疏矩阵
 示意图
示意图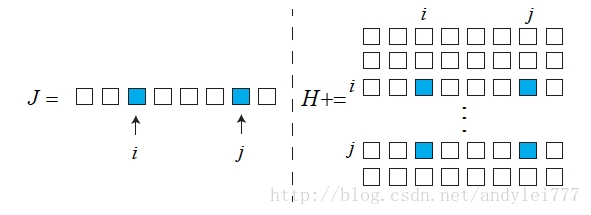
如果对变量做好排序,例如所有相机位姿在前,路标在后,那么 H 有一定的特殊结构:
图模型与H矩阵存在对应关系:图模型中存在边=>H相应地方出现非零块
实际当中的H,路标数量远大于位姿数量(箭头形矩阵或镐子形矩阵)
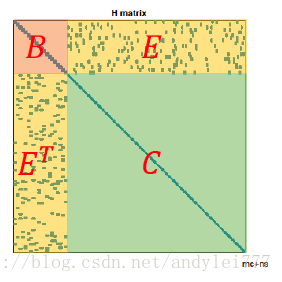
边缘化加速方程求解
利用H的特殊结构,可以大幅加速Hx=-b线性方程的求解。
加速手段又称边缘化(Marginalization)[意义有很多种]
Hx=-b的结构: B:小,对角块;C,大,对角块
E和E转置:与图模型对应,可稠密
因为 C 是对角块,所以可以用C对E进行消元(高斯消元),得到:

从而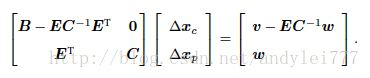
该方程组分为两步来求:
- 求解上半部分,规模较小,得到 Δxc Δ x c
- 将结果代入下半部分,得到 Δxp Δ x p
这个做法称为Marginalization或Schur消元
从消元角度来讲,亦可使用Cholesky等其他消元方式解此稀疏方程
从Marginalization角度来讲,是我们把所有的路标信息边缘化到了相机的信息中
Marginalization(marg):
- 联合分布=边缘分布乘条件分布:

- 上述的做法marg掉了所有的路标点,让概率全跑到相机位姿中,这是为了加速求解 Hx=-b
- 然而,在sliding window等其他做法中,也可以选择边缘化一部分相机/路标,做法同上
- 但是,通常情况下的Marg操作会给H矩阵带来填充(fill-in),使其不再具有稀疏结构;
- 所以,要么刻意选择特定的marg策略,要么仅使用稠密的H求解线性方程,但这样效率会降低
- Marginalization之后,左上角矩阵不再具有稀疏结构:
 但它反映了相机之间的共视关系(Co-visibility) S14/S24处的非零块表示1,4相机,2,4相机看到了同一个路标点
但它反映了相机之间的共视关系(Co-visibility) S14/S24处的非零块表示1,4相机,2,4相机看到了同一个路标点 - Marg操作与FEJ: 在处理Marg时,被Marg的部分要使用First-estimate-Jacobian
否则可能导致整个问题零空间被降维.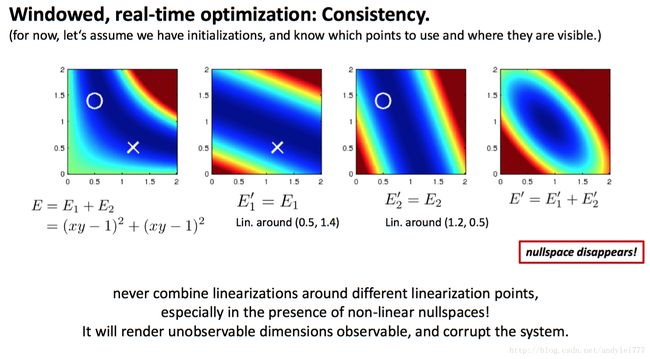
Pose Graph
省掉3D点只对姿态进行优化,然后更新3D点就行。
实际当中BA的计算量很大
- 通常放在单独的后台线程中计算而无法实时
- 主要计算来自于大量的特征点
Pose Graph即是省略了特征点的Bundle Adjustment (减少计算量)

Pose Graph:
- 顶点仅由相机位姿组成
- 边为位姿与位姿间的约束
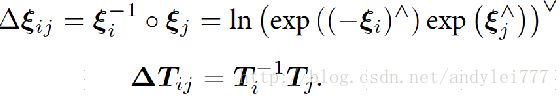
- 不同的观测组成了不同的边
- 误差项

- 误差项关于两个顶点的雅可比:
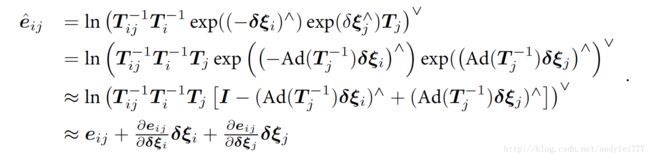

实践:Pose球的例子
仿真的球形轨迹
Odom边和Loop边 