Yolov5 网络组件代码
在该路径下yolo.py文件里存放的是网络组件,也就相当于yolo模型的基础
1.autopad 自动扩充
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
# 如果k为int型则整除2。如果k不为整数值(为若干个整数值),则做一个循环
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p这个代码是为same卷积或same池化做自动扩充,致使卷积和池化后的大小不变,在输入的特征图上做0填充,到底填充多少,通过这个函数进行计算。
2.Conv 标准卷积
一个标准的卷积流程 conv2d + bn + swish激活

class Conv(nn.Module): # 标准卷积
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding,
# groups通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x): # 前向传播函数
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x): # 去掉了bn层
return self.act(self.conv(x))这里的参数g:groups,指的是:通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除。
比如输出通道为6,输入通道也为6,假设groups为3,卷积核为 1x1 ; 则卷积核的shape为2x1x1,即把输入通道分成了3份;那么卷积核的个数呢?之前是由输出通道决定的,这里也一样,输出通道为6,那么就有6个卷积核!这里实际上是将卷积核也平分为groups份,在groups份特征图上计算,以输入、输出都为6为例,每个2xhxw的特征图子层就有且仅有2个卷积核,最后相加恰好是6。这里可以起到的作用是不同通道分别计算特征。
3.DWConv深度可分离卷积(并没有使用)
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)这里的深度可分离卷积,主要是将通道按输入输出的最大公约数进行切分,在不同的通道图层上进行特征学习。
4.Bottleneck瓶颈层
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))这里输入的参数
shortcut 是否给bottleneck 结构添加shortcut连接,添加后即为ResNet模块 expansion 结构中的瓶颈部分的通道膨胀率,使用0.5即为变为输入的1/2;
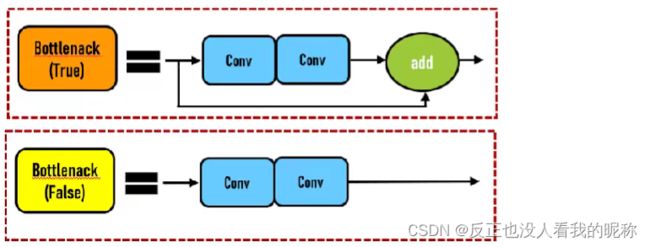
当shortcut为True时添加短接层,当为False时不添加。
5.BottleneckCSP CSP瓶颈层
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))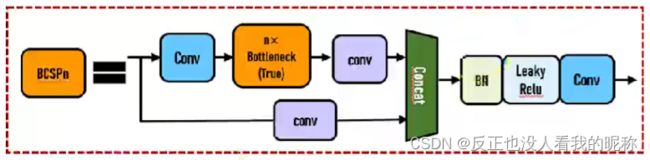
CSP瓶颈层结构在Bottleneck部分存在一个可修改的参数n,标识使用的Bottleneck结构个数!这一条也是我们的主分支,是对残差进行学习的主要结构。
6.SPP 空间金字塔池化
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k]) # 这边可以看到对每一个k都要做池化
def forward(self, x):
x = self.cv1(x) # 直接用1*1的卷积核,也就是图片最下面
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1)) # 对5,9,13进行池化然后和x进行拼接根据代码结合下图可以看出,他在5,9,13这3个维度进行了池化,在forward方法中对3个层面进行了拼接。

7.Focus
他把宽度w和高度h的信息整合到空间c中。
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
# 把数据做了切分,然后拼接,然后进行标准卷积
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))8.Classify
这个组件用于第二级分类,意思就是如果想让检测出的结果再进行一次分类就要用这个,他给的这个方法比较简单,如果需要,我们可以改写。
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
self.flat = nn.Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)