云计算-基于hadoop-2.7.7从0开始搭建
云计算-基于hadoop-2.7.7从0开始搭建
文章目录
-
-
- 云计算-基于hadoop-2.7.7从0开始搭建
-
- 一、环境准备
- 二、必备基础知识
-
-
- 一、 Hadoop是什么?用来干嘛的?
- 二、Hadoop 的组成
- 三、关于hadoop集群安装的三种方式对比
- 四、主要名词解释
-
- 三、开始安装hadoop-2.7.7
-
- 初始环境配置
-
- 3. 安装好用的vim VimForCpp
- 6. SSH 配置
- 单机模式安装
-
- 单机模式--官方 Grep 案列
- 单机模式--官方 WordCount 案例
- 伪分布式安装
-
- 伪分布式 WordCount 案例
- 全分布式安装
- 四、HDFS常用命令
- 可能遇到的问题
-
-
- 一、hdfs管理界面50070端口设置后,无法访问情况。
- 二、上传文件出错 "put: Cannot create file/test/xxx.COPYING. Name node is in safe mode."
- 三、hadoop101:9000 failed on connection exception 端口无法访问
- 四、Name node is in safe mode.名称节点处于安全模式
-
-
一、环境准备
-
VMware16.4 https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
-
Centos7.9 https://mirror.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/
-
Xshell7&Xftp7 https://www.xshell.com/zh/free-for-home-school/
-
hadoop-2.7.7 https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
hadoop 其它版本 https://archive.apache.org/dist/hadoop/common/
-
JDK 1.8 https://www.java.com/zh-CN/download/manual.jsp
二、必备基础知识
一、 Hadoop是什么?用来干嘛的?
Hadoop是一个能够对大量数据进行分布式处理的软件框架;是由Apache基金会所开发的 分布式系统基础架构 。Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。我们可以在不了解分布式底层细节的情况下,开发分布式程序并充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
Hadoop的优势
- 高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
- 高容错性: 能够自动将失败的任务重新分配。
Hadoop架构图如下:

参考链接 https://baike.baidu.com/item/Hadoop/3526507 百度百科
二、Hadoop 的组成
-
4个核心 (hadoop 2.x)

ps:虽然上述四个模块构成了Hadoop的核心,不过还有其他几个模块。这些模块包括:Ambari、Avro、Cassandra、Hive、 Pig、Oozie、Flume和Sqoop,它们进一步增强和扩展了Hadoop的功能。
ps:Hadoop 的三个版本
Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
Hadoop3.x时代,在组成上没有变化。
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks 文档较好。
- HDFS 框架概述
① NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块所在的 DataNode 等。作用如下:
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
② DataNode(dn): 在本地文件系统存储文件块数据,以及块数据校验和。作用如下:
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
③ Secondary DataNode(2nn): 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。并非NameNode的热备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。作用如下:
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode。
- Yarn 结构概述

YARN ,是一种资源协调者,是 Hadoop 的资源管理器。
**① ResourceManager(RM):**整个集群资源(内存、CPU等)的老大
(1)处理客户端请求。
(2)监控 NodeManager。
(3)启动或监控 ApplicationMaster。
(4)资源的分配与调度。
② NodeManager(NM): 单个任务运行的老大
(1)管理单个节点上的资源。
(2)处理来自 ResourceManager 的命令。
(3)处理来自 ApplicationMaster 的命令。
(4)资源的分配与调度。
③ ApplicationMaster(AM): 单个节点服务器资源老大
(1)负责数据的切分。
(2)为应用程序申请资源并分配给内部的任务。
(3)任务的监控与容错。
④ Container(容器): 相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、网络等。
Container 是 Yarn 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
- MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 阶段和 Reduce 阶段。
① Map 阶段并行处理输入的数据。
② Reduce 阶段对 Map 结果进行汇总。

- HDFS、YARN、MapReduce三者关系
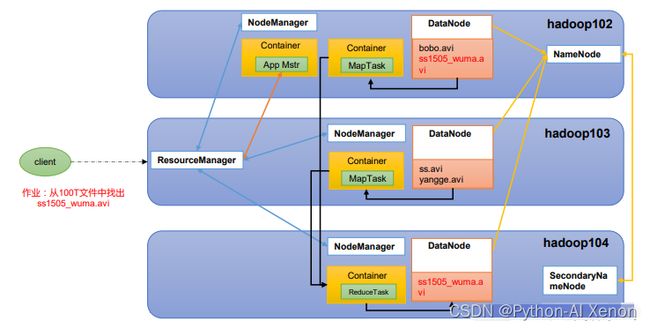
- 大数据技术生态体系

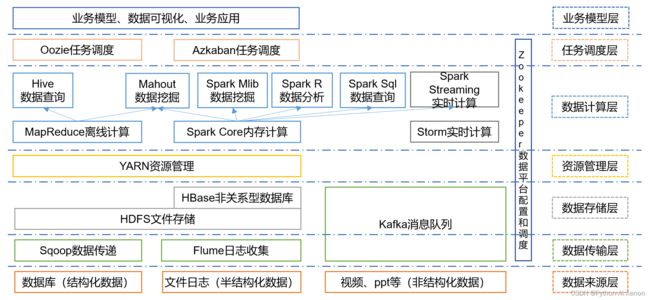
三、关于hadoop集群安装的三种方式对比
1.单机模式( Local/Standalone Mode)
单机模式是Hadoop的默认模式。这种模式在一台单机上运行,没有分布式文件系统HDFS,而是直接读写本地操作系统的文件系统。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。默认情况下,Hadoop处于该模式,用于开发和调试(MapReduce程序的应用逻辑)。
2.伪分布模式(Pseudo-Distributed Mode)
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
3 . 全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。最低要求3个及以上的实体机或者虚拟机组件的机群来实现。
4. 为什么伪分布式要比单机慢?
众所周知MapReduce是基于硬盘的计算引擎,计算一个结果就会存入硬盘,reduce计算时会从硬盘中取出再进行计算,在单机模式下硬盘就是我们的自身的Linux系统,但是分布式的情况下,硬盘是我们的hdfs分布式文件系统,存取数据会有一层映射,故而慢。既然这样的话,那为何还要有分布式文件系统?原因就是大数据时代,单机硬盘存不下大量数据,只能通过分布式存储。
四、主要名词解释
- 集群
集群(Cluster)是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,在单一系统的管理下,共同协作完成同一个任务。集群中每一个计算机叫作节点,每个节点都实现相同的业务,但是每个节点并不是缺一不可的。其主要作用是缓解并发压力和进行单点故障转移。
集群一般被分为三种类型:高可用集群、负载均衡集群和高性能运算集群。
- 分布式系统
分布式系统是将不同功能或不同地点、拥有不同数据的多台计算机通过网络连接起来,由控制系统统一管理,完成大规模信息处理的计算机系统。在分布式文件系统中,一种业务拆分成多个子业务,部署在多台计算机节点上,对外提供服务。其主要作用是大幅度地提高效率,缓解服务器的访问和存储压力。
常见的分布式系统有分布式文件系统、和分布式计算系统。
- 负载均衡
负载均衡(Load Balance)是指将负载(工作任务)进行平衡,分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心。和其他主要任务服务器等,从而协同完成工作任务。负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法用于扩展服务器和网络设备的带宽,加强网络数据处理能力,增加吞吐量,提高网络的可用性和灵活性。负载均衡中每个节点分配到的任务基本均衡。
三、开始安装hadoop-2.7.7
初始环境配置
由于我安装的Centos镜像是CentOS-7-x86_64-Minimal-2009.iso 也就是最小化,所以要配置一些东西,如果已弄好的请忽略这一步。
- 更新 & 升级
yum update -y && yum upgrade -y
- 安装 net-tools.x86_64工具包、ssh服务、jps
yum install openssh-server -y
yum install net-tools.x86_64 -y
#yum install vim -y
yum install java-1.8.0-openjdk-devel.x86_64 -y
3. 安装好用的vim VimForCpp
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
#安装完成后执行下面命令或者重启终端就可以使用啦
source ~/.bashrc
#如需卸载
bash ~/.VimForCpp/uninstall.sh
- 防火墙设置
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 禁止防火墙开机启动
firewall-cmd --state # 查看防火墙状态
- 将当前的liunx时间设置为北京时间
yum install ntp ntpdate ntpdate -u cn.pool.ntp.org
6. SSH 配置
# 1.查看是否安装ssh
yum list installed | grep openssh-server
# 或者
rpm -qa | grep ssh
# 2.安装ssh(未安装情况)
yum install openssh-server
# 3.编辑ssh配置文件,
vim /etc/ssh/sshd_config
# 一般来说只要关闭了防火墙不用配置这步,否则如下设置
Port 22 # 打开22监听端口
ListenAddress 0.0.0.0 # 开发监听所有地址
ListenAddress ::
PermitEmptyPasswords no #开启root用户登录
PasswordAuthentication yes #开启密码登录
# wq 保存退出
# 4.启动ssh服务
service sshd start # 启动ssh服务
ps -e | grep sshd # 查看ssh是否开启
netstat -an | grep 22 # 查看端口状态
systemctl status sshd.service # 查看服务运行状态
# :wq保存退出
# 5.设置开机自启
systemctl enable sshd.service
systemctl list-unit-files | grep sshd # 查看是否加入成功
单机模式安装
- 下载 hadoop-2.7.7 ,这里我直接从官网下载,要是嫌慢也可以先下载好在传进去
# 方法一
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
# 方法二
scp ./hadoop-2.7.7.tar.gz [email protected]:/usr/local/
- 解压到指定目录(目录根据自己习惯自行选择,这里参考很多教程使用的是 /usr/local/)
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/
chmod 777 /usr/local/hadoop-2.7.7 #为该目录提升权限,避免操作失败
- 安装JDK-1.8
yum install java-1.8.0-openjdk -y
安装完成后输入 java -version 查看 如下图所示

- 配置Hadoop和JDK的环境变量
# 1.先找到java的安装路径,这里的/usr/bin/java 是which java后的结果
ll /usr/bin/java
ll /etc/alternatives/java
结果如下图: (这里 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre就是java的真实路径,复制!要用)

# 2.用vim编辑器打开配置文件
vim /etc/profile
# 3.在末尾添加以下内容
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
# :wq 保存退出

# 4.激活环境变量
source /etc/profile
# 5.查看hadoop 版本信息
hadoop version
内容如下表示 Hadoop和JDK均已安装成功

其 目录结构如下:

Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。
非分布式即单 Java 进程,方便进行调试。Hadoop 附带了丰富的例子:
cd /usr/local/hadoop
# 查看示例 可以看到所有例子,包括 Wordcount、join、Grep 等。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
# hadoop:$HADOOP_HOME/bin 下的shell脚本名。
# jar:hadoop脚本需要的command参数。
# jar包是对写好的java类进行了打包,类似ZIP文件
单机模式–官方 Grep 案列
任务:
- 实现正则匹配
统计正则匹配到的字符出现的个数
dfs[a-z.]+ :查询dfs开头的,后面跟1个或1个以上的字母,比如 dfsa; dfsbgfg; dfscuhjhhkjgds
解释:我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式dfs[a-z.]+的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop-2.7.7
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep ./input ./output 'dfs[a-z.]+'
# .bin/hadoop jar :执行一个jar包程序
# share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar :jar包所在的目录
# wordcount :表示执行jar包程序中grep功能
# ./input :输入目录
# ./output :输出目录
# 'dfs[a-z.]+' :正则表达式(以dfs开头的任意字符串)
# 程序成功运行............
cat ./output/* # 查看运行结果
注意:Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会出错,需要先` rm -r ./output `将 ./output 删除。
单机模式–官方 WordCount 案例
- 这个程序可以统计某个文件中,各个单词出现的次数。
注:Wordcount是MapReduce的入门示例程序
Wordcount程序自带的jar包已经放置在hadoop安装目录下的/share/hadoop/mapreduce文件夹中。
- 在hadoop-2.7.7 根路径下创建文件夹
cd /usr/local/hadoop
mkdir wcinput
- 在wcinput文件下创建一个wc.input文件,并输入以下内容
cd /usr/local/hadoop-2.7.7/wcinput
vim wc.input
# 输入以下单词
hello hadoop
hello mapreduce
hello yarn
hello world
- 回到
/usr/local/hadoop-2.7.7下,执行程序
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput wcoutput
# .bin/hadoop jar :执行一个jar包程序
# share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar :jar包所在的目录
# wordcount :表示执行jar包程序中wordcount功能
# wcinput :输入目录
# wcoutput :输出目录
伪分布式安装
- 配置集群,修改 Hadoop 的几个配置文件(/usr/local/hadoop-2.7.7/etc/hadoop 目录下)
# 将主机名称进行重命名方便配置(这里将其重命名为hadoop101),更改后需要重启才会生效
hostnamectl set-hostname hadoop101
# 重启命令为 reboot
# 如不重命名也行 下面文件中的所有hadoop101换成自己主机的IPv4地址即可,不能使用127.0.0.1
vim /etc/hosts # 修改之后删除/etc/hosts文件中的所有内容,并添加
192.168.242.129 hadoop101 # 前面改为自己的ip地址,后面是你上面更改的主机名称
# wq 保存退出
mkdir -p /usr/local/hadoop-2.7.7/tmp /usr/local/hadoop-2.7.7/data /usr/local/hadoop-2.7.7/name #新建文件夹存放产生的文件
cd /usr/local/hadoop-2.7.7/etc/hadoop #切换到配置文件路径执行下面操作

① core-site.xml 核心组件
该文件是 Hadoop 的核心配置文件,其目的是配置 HDFS 地址、端口号,以及临时文件目录。
vim core-site.xml # 打开文件后在<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop101:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop-2.7.7/tmpvalue>
property>
<property>
<name>hadoop.native.libname>
<value>falsevalue>
<description>
hadoop.native.lib false Should native hadoop libraries, if present, be used.
description>
property>
configuration>
② hadoop-env.sh 配置环境变量
vim hadoop-env.sh # 打开文件后更改以下内容
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre
③ hdfs-site.xml 配置文件系统
该文件主要用于配置 HDFS 相关的属性,例如复制因子(即数据块的副本数)、NameNode 和 DataNode 用于存储数据的目录等。在完全分布式模式下,默认数据块副本是 3 份。
vim hdfs-site.xml # 打开文件后在<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.http.addressname>
<value>0.0.0.0:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/hadoop-2.7.7/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/hadoop-2.7.7/datavalue>
property>
configuration>
⭐上面是 HDFS 伪分布式集群的搭建
⭐下面是 Yarn 伪分布式集群的搭建
④ map-site.xml 配置计算框架
该文件是 MapReduce 的核心配置文件,用于指定MapReduce运行时框架。此处应该指定 yarn,另外的可用值还有 local (本地的作业运行器)和 classic(MR1运行模式),默认为 local。
cp mapred-site.xml.template map-site.xml # 先copy模板生成文件
vim map-site.xml # 打开文件后在<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
⑤yarn-site.xml 配置YARN 框架核心
本文件是YARN 框架的核心配置文件,用于配置 YARN 进程及 YARN 的相关属性。
首先需要指定 ResourceManager 守护进程所在主机,默认为0.0.0.0,即当前设备,所以这里我们无需再次指定;其次需要设置 NodeManager 上运行的辅助服务,需配置成 mapreduce_shuffle 才可运行 MapReduce 程序
vim yarn-site.xml # 打开文件后在<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>192.168.242.129value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
⑥yarn-env.sh yarn环境变量配置方法同hadoop-env.sh
⑦ slaves
该文件用于记录 Hadoop 集群所有从节点(HDFS 的 DataNode 和 YARN 的 NodeManager 所在主机)的主机 名,用来配合一键启动脚本启动集群从节点(并且还需要保证关联节点配置了 SSH 免密登录)
cat /root/software/hadoop-2.7.7/etc/hadoop/slaves # 查看该配置文件
可以看到其默认内容为localhost,因为我们搭建的是伪分布式集群,就只有一台主机,所以从节点也需要放在此主机上,所以此配置文件无需修改。

- 启动集群
2.1 单节点逐个启动、关闭
# 1.格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
# 执行格式化指令后,必须出现有“successfully formatted” 信息才表示格式化成功
# 2.启动 NameNode
hadoop-daemon.sh start namenode
# 3.启动 DataNode
hadoop-daemon.sh start datanode
# 4.查看 如找不到jps 请执行 yum install java-1.8.0-openjdk-devel.x86_64 -y
jps
# jps命令是jdk查看当前java进程的工具
## 如需关闭
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode
2.2 一键启动、关闭 (常用)
start-dfs.sh # 启动
stop-dfs.sh # 关闭
-
查看集群
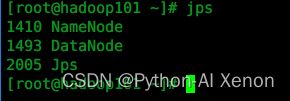
① 查看是否启动成功 输入
jps得到如下图所示表示启动成功

② web 端查看 HDFS 文件系统http://192.168.242.129:50070或者http://localhost:50070…这里192.168.242.129是我的ip地址自己的 IP 地址可以使用ifconfig或者ip addr命令查看,结果类似下面这样:

出现该界面就成功了!
4. yarn 集群测试 (需要保证HDFS集群是启动状态)
start-yarn.sh #启动yarn集群
stop-yarn.sh #关闭yarn集群
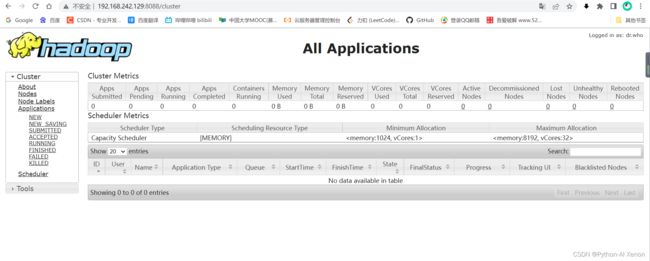
打印结果中多了 2 个进程,分别是 ResourceManager 和 NodeManager,如果出现了这 2 个进程表示进程启动成功。通过UI查看Yarn运行状态
YARN 集群正常启动后,它默认开放了8088 端口,用于监控 YARN 集群。通过 UI 可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。结果如下 : http://192.168.242.129:8088/
伪分布式 WordCount 案例
- 执行``start-dfs.sh` 启动hadoop,jps查看
- 在 Hadoop-2.7.7 目录下使用指令
mkdir wcinput创建wcinput文件夹并在文件夹下面创建文件vim wc.input随便写入几个单词如下图所示:
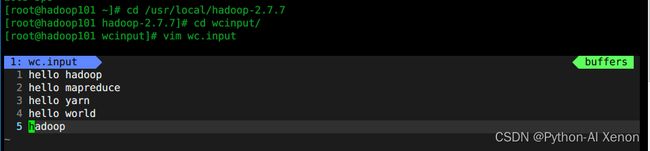
-
使用 HDFS命令创建文件夹
hdfs dfs -mkdir -p /sample/wordcount -
将
wc.input上传到刚刚创建好的文件夹下面hdfs dfs -moveFromLocal ./wordcount/wc.input /sample/wordcount # 查看是否上传成功 hdfs dfs -ls -R / -
执行命令生成生成
wc.output结果文件
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /sample/wordcount/wc.input /sample/wordcount/wc.output
-
查看结果 如下:
hdfs dfs -ls -R / hdfs dfs -cat /sample/wordcount/wc.output/part-r-00000
Web 端查看
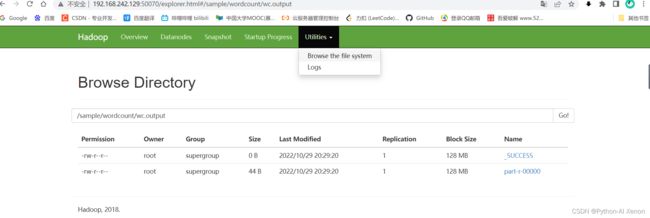
执行成功!❀❀
全分布式安装
敬请期待....
四、HDFS常用命令
-ls 查看hdfs目录下的文件,如 hdfs dfs -ls / 或者 hdfs dfs -ls -R /tmp/
-put 将本地文件上传到hdfs,如hdfs dfs -put <本地文件路径>
-get 将hdfs文件下载到本地,如 hdfs dfs -get
-mkdir 在hdfs 上创建文件夹,如hdfs dfs -mkdir /test
-cp 将hdfs文件或目录复制 如 hdfs dfs -cp /test.txt/a/
-cat 查看hdfs上文件内容 如hdfs dfs -cat /test.txt
-rm hdfs删除某个文件 如hdfs dfs -rm /test/test2.txt
-mv hdfs内部进行文件移动 hdfs dfs -mv /test/test123/ /test/test2/
-chmod 赋予hdfs文件夹权限 如hdfs dfs -chmod -R -777 /
-chown 改变文件的所属用户和用户组 hdfs dfs -chmod [-R] URI[URI …]
可能遇到的问题
一、hdfs管理界面50070端口设置后,无法访问情况。
解决方法:
1)停止当前所有服务 stop-all.sh
2)在 hdfs-site.xml 中,更改开放端口的绑定IP:
<property>
<name>dfs.http.addressname>
<value>0.0.0.0:50070value>
property>
2)检查防火墙状态,firewall-cmd --state
暂时关闭防火墙,systemctl stop firewalld.service。
3)删除之前数据区,比如/usr/local/hadoop-2.7.7/tmp/,特别注意 删除命令
rm -rf /usr/local/hadoop-2.7.7/tmp/*
rm -rf /usr/local/hadoop-2.7.7/name/*
rm -rf /usr/local/hadoop-2.7.7/data/*
一定注意!一定注意!一定注意!
4)重新格式化namenode,执行 hdfs namenode -format
5)重新启动 start-all.sh
二、上传文件出错 “put: Cannot create file/test/xxx.COPYING. Name node is in safe mode.”
解决方法:
离开安全模式再上传文件
hadoop dfsadmin -safemode leave
三、hadoop101:9000 failed on connection exception 端口无法访问
解决方法:
1)关闭Hadoop集群 stop-all.sh
2) 关闭防火墙 service iptables stop && chkconfig iptables off
3)关闭NetworkManager服务 service NetworkManager stop && chkconfig NetworkManager off
4)正确配置vim /etc/hosts ,删除其里面所有内容并写入
5)使用netstat -tlpn 命令检查主节点9000端口是否打开,且允许远程访问
6)重启hadoop集群 start-all.sh
四、Name node is in safe mode.名称节点处于安全模式
解决方法:
hadoop dfsadmin -safemode leave