基于VGG16主干模型的segnet语义分割详解及实例
目录
一. 语义分割的含义
二. SegNet语义分割模型
三. 基于VGG16主干模型的segnet语义分割
四. 检测结果
五.完整代码
一. 语义分割的含义
语义分割是计算机视觉中的基本任务,在语义分割中我们需要将视觉输入分为不同的语义可解释类别,「语义的可解释性」即分类类别在真实世界中是有意义的。例如,我们可能需要区分图像中属于汽车的所有像素,并把这些像素涂成蓝色。
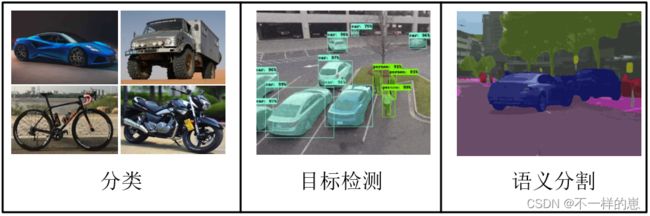
我们将 图像分类,目标检测 和 语义分割 进行对比 可以让我们更好的理解语义分割。
图像分类: 通过 提取特征,输出 待测图片趋向于某个种类
目标检测: 通过 提取特征,输出 待测图片中不同物体的位置与种类
语义分割: 通过 提取特征, 输出 待测图片的每个像素点的种类
二. SegNet语义分割模型
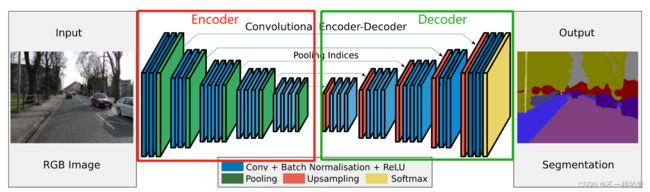
SegNet是一种用于语义分割的深度全卷积神经网络结构,其核心由一个编码器网络和一个对应的解码器网络以及一个像素级分类层组成。
如下图所示, 一般的分类,或者检测的特征提取 是通过卷积提取特征, size不断的缩小, 特征维度不断的增高。如同图中的Encoder部分,最后直接接个激活层得出类别信息。 而 语义分割则是在后面跟上 一个Decoder部分, 将前面提取出的高维特征 Size不断增大, 维度不断减少,最后输出的 层的张量直接是 图片的像素点分类结果。
三. 基于VGG16主干模型的segnet语义分割
如上图所示,语义分割模型 分为 编码模型(主干网络) 和 解码模型,主干模型 可以是VGG, ResNet, Mobile等分类及检测模型 , 解码模型有 segnet, unet, pspnet, deeplab等。
本文代码演示的是基于VGG16的segnet语义分割模型,之后博文里会介绍其他的。完整的模型示意图如下:
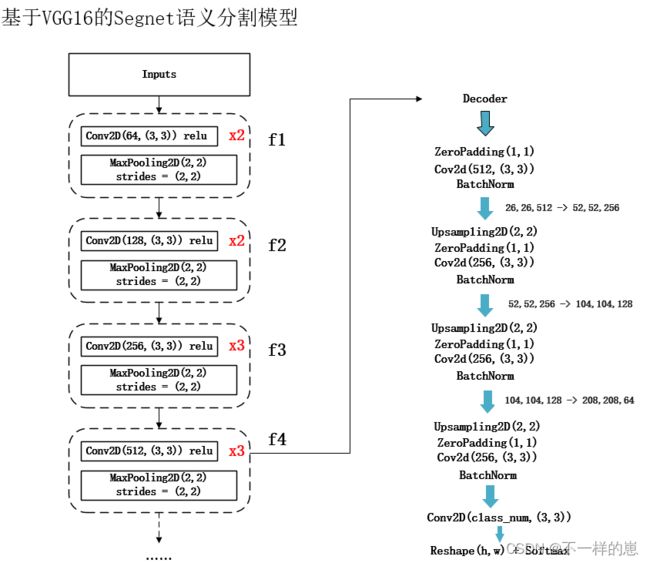
左侧是主干模型VGG16,可以看出主干模型并不是完整的VGG16, 而是从靠后的某层抽取出来的。因为完整的VGG16最后输出的是经过激活层之后的确定了种类的特征信息, 而不是单纯的高维特征信息。
Encoder代码如下:
import tensorflow.keras
import tensorflow.keras.backend as K
from tensorflow.keras.activations import *
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
IMAGE_ORDERING = 'channels_last'
def get_convnet_encoder(input_height=416, input_width=416):
img_input = Input(shape=(input_height, input_width, 3))
# 416,416,3 -> 208,208,64
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
f1 = x
# 208,208,64 -> 104,104,128
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
f2 = x
# 104,104,128 -> 52,52,256
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
f3 = x
# 52,52,256 -> 26,26,512
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
f4 = x
# # 在视频中,这个f5并没有用到
# # 26,26,512 -> 13,13,512
# x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
# x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
# x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
# x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
# f5 = x
return img_input, f4
Decoder部分代码如下:
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from nets.convnet import get_convnet_encoder
def segnet_decoder(feat, classes_num):
# 是否需要重新赋值, feat的原址数据改动是否会造成影响
segnet_out = feat
#26,26,512 -> 26,26,512
segnet_out = ZeroPadding2D((1, 1))(segnet_out)
segnet_out = Conv2D(512, (3, 3), padding='valid')(segnet_out)
segnet_out = BatchNormalization()(segnet_out)
# 26,26,512 -> 52,52,256
segnet_out = UpSampling2D((2, 2))(segnet_out)
segnet_out = ZeroPadding2D((1, 1))(segnet_out)
segnet_out = Conv2D(256, (3, 3), padding='valid')(segnet_out)
segnet_out = BatchNormalization()(segnet_out)
# 52,52,256 -> 104,104,128
segnet_out = UpSampling2D((2, 2))(segnet_out)
segnet_out = ZeroPadding2D((1, 1))(segnet_out)
segnet_out = Conv2D(128, (3, 3), padding='valid')(segnet_out)
segnet_out = BatchNormalization()(segnet_out)
# 104,104,128 -> 208,208,64
segnet_out = UpSampling2D((2, 2))(segnet_out)
segnet_out = ZeroPadding2D((1, 1))(segnet_out)
segnet_out = Conv2D(64, (3, 3), padding='valid')(segnet_out)
segnet_out = BatchNormalization()(segnet_out)
# 208,208,64 -> 208,208,2(classes_num)
segnet_out = Conv2D(classes_num, (3, 3), padding='same')(segnet_out)
return segnet_out
def convnet_segnet(classes_num, input_height=416, input_width=416, encoder=3):
# 从 nets.convent 的 主干网络(vgg部分网络) 导出数据
img_input, convnet_out = get_convnet_encoder(input_height, input_width)
# 将特征传入segnet网络
segnet_out = segnet_decoder(convnet_out, classes_num)
# 将 segnet网络输出的结果进行 reshape(x, -1) , -1表示未知
# 行:x = int(input_height/2) * int(input_width/2) 列:-1
# 注意 这里是 reshape 不是 resize
segnet_out = Reshape((int(input_height/2) * int(input_width/2), -1))(segnet_out)
segnet_out = Softmax()(segnet_out)
model = Model(img_input, segnet_out)
model.model_name = "convent_segnet"
return model
四. 检测结果
用上述的模型检测斑马线, 效果如下
五.完整代码
https://github.com/mcuwangzaiacm/VGG16_SegNet_tf2.0