电商销售数据分析(2021/07/27)
如题,本次案例分析某电商平台的销售数据。本次案例的特点是,数据量比较大,原始数据存在比较多的问题,所以数据处理的过程比较典型。
还是按照原先的数据分析流程,概览数据-->数据处理-->数据分析
概览数据
概览数据重点关注,数据的标识问题,了解数据字段,大概观察下数据的问题。
1.数据的标识有订单标识和row_id, 订单标识有重复的问题,业务原因是一个订单买了三件商品,数据就给展开了。其中row_id是数据的唯一标识。
2.数据字段主要描述国际贸易的电商交易,其字段含义。。。

3.postalcode存在大量空值,需要处理
数据处理
脏数据的理解和处理
我们知道数据按照数据来源不同可以分为,一方数据,二方数据,三方数据。通常情况下,一方数据和二方数据脏数据会相对偏少,使用起来也比较方便。
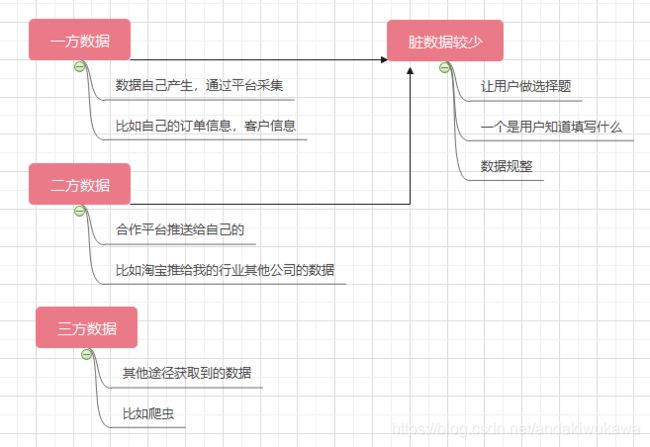
我们之前提到过脏数据可以分为三类,异常值,缺失值,重复值。分类不同处理方式不同。
| 脏数据类型 | 优先处理方式 | 次级处理方式 |
| 异常值 | 修正 | 删除 |
| 缺失值 | 补充 | 删除 |
| 重复值 | 删除 |
下面这个图也可以更清晰的理解:总之就是重要的数据不要自己补,会影响数据真实性,不重要的数据缺失就缺吧。

数据处理流程
数据处理流程可以细分为:读取数据-->提取业务数据-->数据清洗-->数据规整,其中提取业务数据和数据清洗是结合着一起做的。以下是实例。
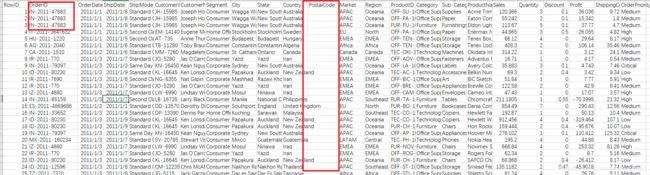
读取数据51101 rows × 24 columns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('dataset.csv',encoding='ISO-8859-1')
data
data.shape整个数据清洗的流程一般情况下是
先处理 重复值(标识),同步处理异常值,空值,处理完成后再次处理重复值
这么做的原因是,在处理异常值和空值的时候可能会涉及到用整列数据计算填补,重复值的存在导致无法填补。
处理类型:重复值处理,标识数据
处理重复值--->找出唯一标识--->去重
data.shape
data.RowID.unique().size
data[data.RowID.duplicated()]
data.drop(index=data[data.RowID.duplicated()].index,inplace=True)
data.info处理类型:计算时间数据,计算判断脏数据,Series类型转换
根据业务判断我们需要通过 发货时间shipdata 减去 下单时间orderdata 提取 物流时间interval。且这两个数据存在脏数据,有的发货时间比订单时间还要早。
先将两列数据都转换成日期格式
两者相减计算成秒数,提取脏数据
处理脏数据
将相减结果作为新的数据项
data['ShipDate']=pd.to_datetime(data['ShipDate'])
data['OrderDate']=pd.to_datetime(data['OrderDate'])
data['interval']=(data['ShipDate']-data['OrderDate']).dt.total_seconds()
data[data['interval']<0]
data.drop(index=data[data['interval']<0].index,inplace=True)
data
data['interval']=(data['ShipDate']-data['OrderDate'])
data['interval']通过data.info()查看这几列中存在空值。
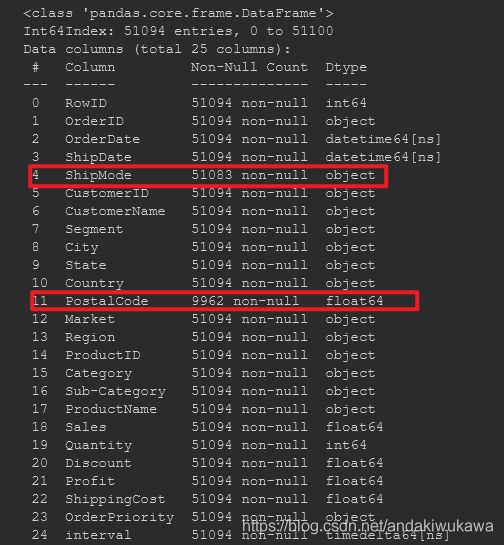
对其中shipmode进行处理,我们考虑填补的方式
处理类型:缺失值填补
首先我们回归数据判断这个数据是字符串还是数值型的,它是字符串类型的我们可以考虑用众数或是前一个后一个进行填补。如果是数值类型的我们可以用平均数,中位数,等进行填补。与业务确认后我们使用众数进行填补。
data[data['ShipMode'].isnull()]
data.ShipMode.mode()
data['ShipMode'].fillna(value=data.ShipMode.mode()[0],inplace=True)
data.info()处理类型:丢弃整列
PostalCode这列数据缺失值多且不重要,选择直接丢弃
data.drop(columns=['PostalCode'],inplace=True)
data.info()处理类型:脏数据判断,按条件替换,平均值填补空值
Discount这列数据并不是几折含义应给是减掉百分比的价格(与业务确定),Discount字段中有>1和<1的脏数据问题。
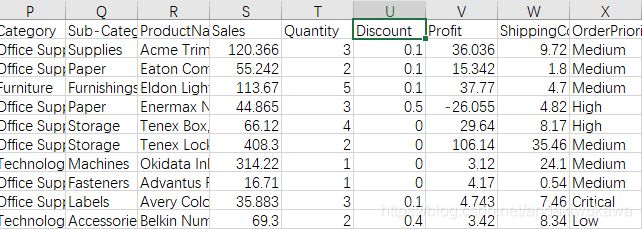
将脏数据变成 null---> 对null 进行填补(用的是平均值)
data[data.Discount>1]
data[data.Discount<0]
data['Discount']=data['Discount'].mask(data['Discount']>1,None)
data[data.Discount>1]
data[data['Discount'].notnull()].Discount.sum()/\
data[data['Discount'].notnull()].size
mean_Discount=round(data[data['Discount'].notnull()].Discount.sum()/\
data[data['Discount'].notnull()].size,2)
mean_Discount
data['Discount'].fillna(value=mean_Discount,inplace=True)
data.info()数据规整:按照维度拆分一些字段
处理类型:拆分时间
将订单日期OrderDate,拆分成年、月、日、季度,并作为新字段,供后面分析使用
data['order-year'] = data['OrderDate'].dt.year
data['order-year']
data['order-month']=data['OrderDate'].dt.month
data['order-month']
data['quarter']=data['OrderDate'].dt.to_period('Q')
data.quarter
result = data[['OrderDate','order-year','order-month','quarter']].head()
result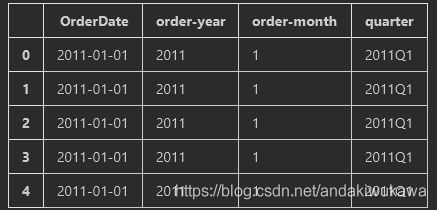
至此数据处理完成。
数据分析
分析类型:双轴图
通过销售额-->衡量企业经营情况--->对比销售额增长--->使用柱状图
销售额增长率-->体现资本的扩张情况
每年增长率=(本年销售额-去年销售额)/去年销售额
每年增长率=当年销售额/去年销售额-1。
# 先求销售额
sales_year = data.groupby(by='order-year')['Sales'].sum()
sales_year
# 求销售额增长率
sales_rate_12 = sales_year[2012]/sales_year[2011] -1
sales_rate_13 = sales_year[2013]/sales_year[2012] -1
sales_rate_14 = sales_year[2014]/sales_year[2013] -1
print(sales_rate_12,sales_rate_13,sales_rate_14)
# 将增长率整理成格式
sale_rate_12_label = "%.2f%%"%(sales_rate_12*100)
sale_rate_13_label = "%.2f%%"%(sales_rate_13*100)
sale_rate_14_label = '%.2f%%'%(sales_rate_14*100)
# 将三列数据整理成df,传入plot作图使用
sales_rate_df = pd.DataFrame(
{'sales_all':sales_year,
'sales_rate':[0,sales_rate_12,sales_rate_13,sales_rate_14],
'sales_rate_label':['0.00%',sale_rate_12_label,sale_rate_13_label,sale_rate_14_label]}
)
sales_rate_df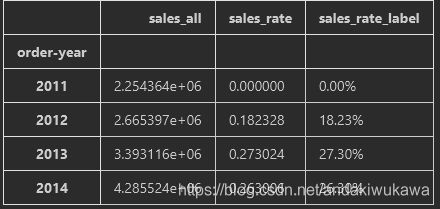
画图,关键步骤ax1和ax2共享x轴
# 设置字体,解决汉字问题
mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.style.use('ggplot')
# 创建作图用的df
sales_rate_df = pd.DataFrame(
{'sales_all':sales_year,
'sales_rate':[0,sales_rate_12,sales_rate_13,sales_rate_14],
'sales_rate_label':['0.00%',sale_rate_12_label,sale_rate_13_label,sale_rate_14_label]}
)
print(sales_rate_df)
# 将行列数据定义成series对象方便作图直接调用
y1 = sales_rate_df['sales_all']
y2 = sales_rate_df['sales_rate']
# y3 = sales_rate_df['sales_rate_label']
x = [str(value) for value in sales_rate_df.index.tolist()]
fig =plt.figure()
ax1 = fig.add_subplot(1,1,1)
# 关键步骤ax1和ax2共享x轴
ax2 = ax1.twinx()
ax1.bar(x,y1,color='blue')
ax2.plot(x,y2,color='red',marker='*')
ax1.set_xlabel('年份')
ax1.set_ylabel('销售额')
ax2.set_ylabel('增长率')
ax1.set_title('销售额与增长率')
plt.savefig('销售额与增长率.png')
plt.show()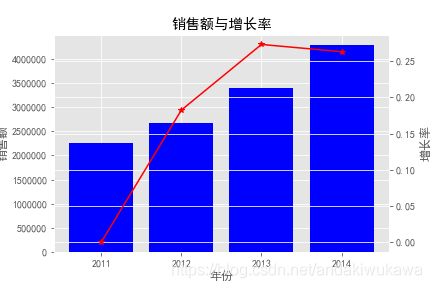
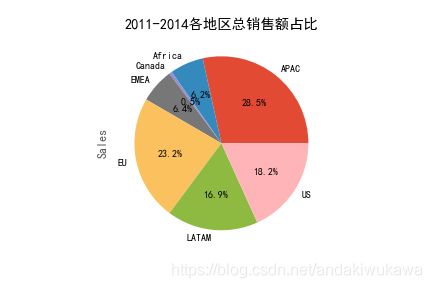
分析类型:饼图
分析2011-2014各地区销售额与总销售额之间的占比关系
sales_area = data.groupby(by='Market')['Sales'].sum()
print(sales_area)
sales_area.plot(kind='pie',
autopct='%1.1f%%',
title='2011-2014各地区总销售额占比')
plt.savefig('2011-2014各地区总销售额占比.png')
plt.show()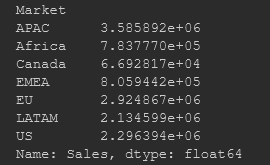
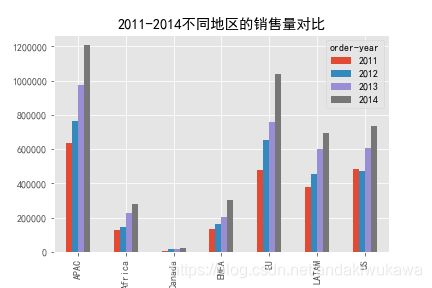
分析类型:多分类柱状图
将每个地区每年的销售额Sales,分门别类展示出来,绘制条形图。
sales_area_year = data.groupby(by=['Market','order-year'])['Sales'].sum()
sales_area_year
# 这货是个series
type(sales_area_year)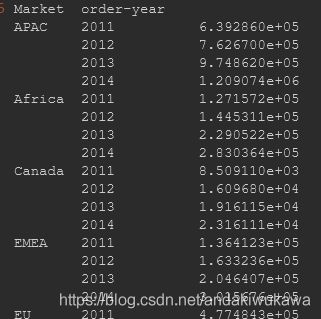
# 把series的数据转换成列数据,这还是个多层索引
sales_area_year=sales_area_year.reset_index(level=[0,1])
sales_area_year
# 透视重新整理数据
sales_area_year = pd.pivot_table(sales_area_year,
index='Market',#默认x坐标
columns='order-year',#默认子柱状图
values='Sales')#默认y坐标
sales_area_year
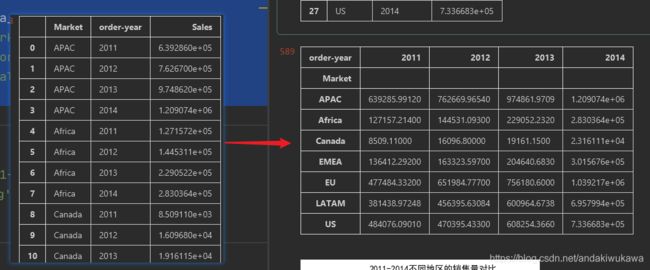
sales_area_year.plot(kind='bar',title='2011-2014不同地区的销售量对比')
plt.savefig('2011-2014不同地区的销售量对比.png')
plt.show()分析类型:多分类柱状图
将每个地区不同类型的产品的销售额Sales,分门别类展示出来,绘制条形图。
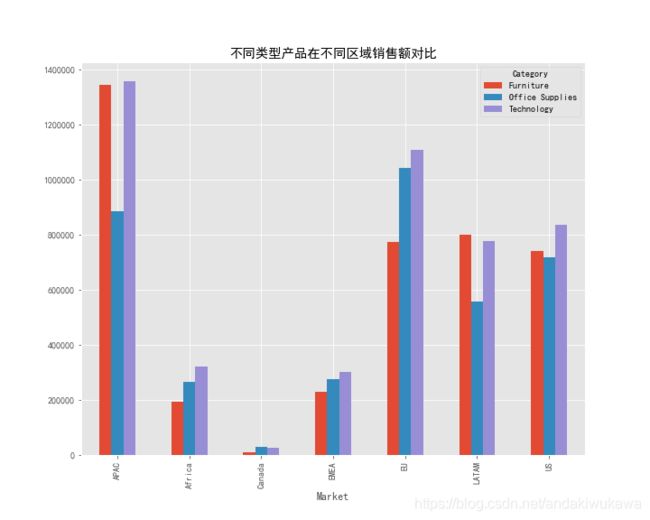
category_area_sales = data.groupby(by=['Market','Category'])['Sales'].sum()
category_area_sales
category_area_sales = category_area_sales.reset_index(level=[0,1])
category_area_sales
category_area_sales = pd.pivot_table(
category_area_sales,
index='Market',
columns='Category',
values='Sales'
)
category_area_sales
category_area_sales.plot(
kind ='bar',
title='不同类型产品在不同区域销售额对比',
figsize=(10,8)
)
plt.savefig('不同类型产品在不同区域销售额对比.png')分析类型:多分类折线图
分析每年销售额变化与月份的关系
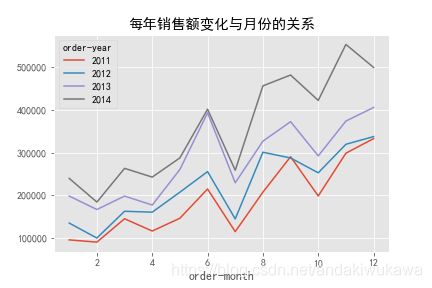
year_month_sales = data.groupby(by=['order-year','order-month'])['Sales'].sum()
year_month_sales
year_month_sales=year_month_sales.reset_index(level=[0,1])
year_month_sales
year_month_sales = pd.pivot_table(
year_month_sales,
index='order-month',
columns='order-year',
values='Sales'
)
year_month_sales
year_month_sales.plot(title='每年销售额变化与月份的关系')
plt.savefig('每年销售额变化与月份的关系.png')分析类型:丢弃重复值统计新增
我们分析每年用户增长与月份之间的关系。图中明显看出来一开始用户增长明显,后续阳痿了。
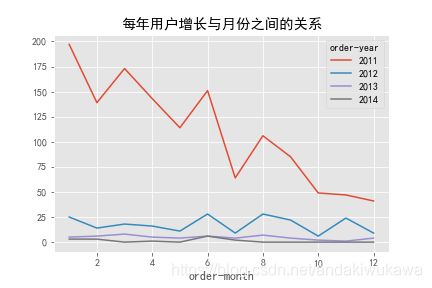
通过丢弃重复值drop_duplicates可以实现,默认参数keep='first',保留用户出现的第一次。
通过分组聚合size统计每年新出现的的用户的个数。
data_customer = data.copy()
data_customer = data_customer.drop_duplicates(subset=['CustomerID'])
data_customer#1590条数据
由于涉及到丢弃数据,我们先用copy()做一下备份,对于这种对象类的数据做备份用copy不要用等于,因为储存机制不同,copy方法更省资源。
customer_year_month_count = data_customer.groupby(by=['order-year','order-month']).size()
customer_year_month_count
customer_year_month_count = customer_year_month_count.reset_index(level=[0,1])
customer_year_month_count
customer_year_month_count = pd.pivot_table(
customer_year_month_count,
index='order-month',
columns='order-year',
values=0,
fill_value=0
)
customer_year_month_count
customer_year_month_count.plot(title='每年用户增长与月份之间的关系')
plt.savefig('每年用户增长与月份之间的关系.png')分析类型:RFM模型分析,给用户打标签

RFM是常用的对用户分析的手法,RFM模型的形式有均值、评分、对应算法,本次案例通过均值的形式。
其中通常情况如图展示,不同情况受到商品特征等因素影响,比如装修这种一锤子的买卖,和用户的交易时间相关不大。根据三种字段,每种字段两种情况,我们可以把用户分成八类。
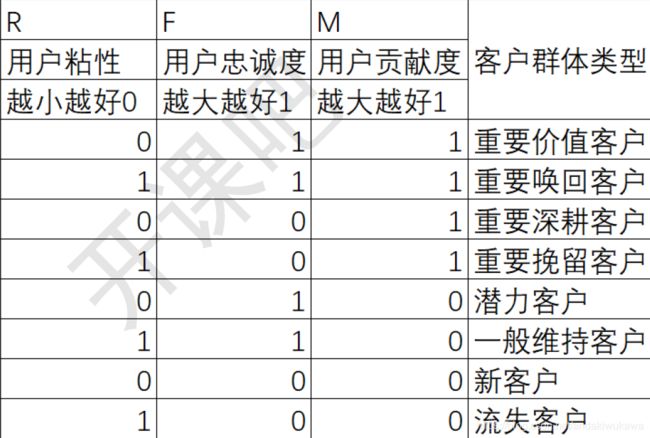
基于这个分类我们对14年的用户进行打标签分析。
取出14年相关的数据和字段---->设置用户id为索引(分析的对象是用户)
data_14 =data[data['order-year']==2014]
data_14=data_14[['CustomerID','OrderDate','Sales']]
data_14
customer_df = data_14.copy()
customer_df.set_index('CustomerID',drop=True,inplace=True)
customer_df计算购买次数----->添加order字段----->用于count或者sum----->透视数据
customer_df['Orders'] = 1
customer_df
rfm_df = customer_df.pivot_table(
index=['CustomerID'],
values=['OrderDate','Orders','Sales'],
aggfunc={
'OrderDate':'max',
'Orders':'sum',
'Sales':'sum'
}
)
rfm_df
rfm_df.OrderDate.max()-rfm_df.OrderDate
rfm_df['R'] = (rfm_df.OrderDate.max()-rfm_df.OrderDate).dt.days
rfm_df['R']
rfm_df.rename(columns={'Sales':'M','Orders':'F'},inplace=True)
rfm_df 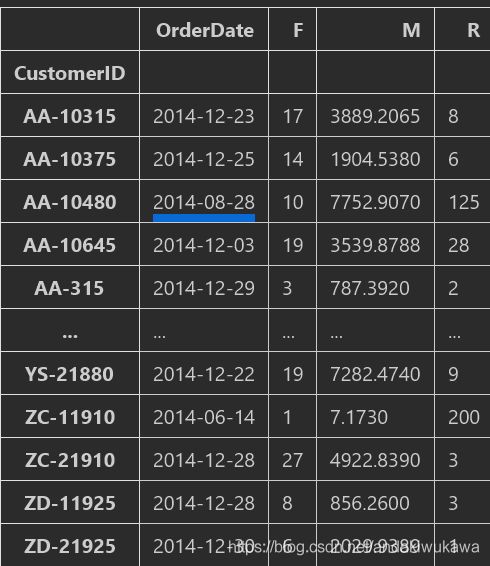
计算好rfm后为 用户打标签
rfm_df[['R','F','M']].apply(lambda x:x-x.mean(),axis=0)
def rfm_func(x):
level = x.apply(lambda x:'1' if x>=0 else '0')
label = level.R + level.F + level.M
d = {
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户',
}
result = d[label]
return result
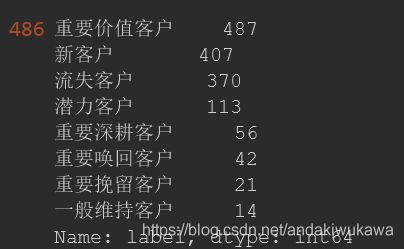
rfm_df['label']=rfm_df[['R','F','M']].apply(lambda x:x-x.mean(),axis=0).apply(rfm_func,axis=1)
rfm_df['label']
rfm_df.groupby(by=['label']).count()
rfm_df.label.value_counts()
rfm_df.label.value_counts().plot.bar(figsize=(20,9))
plt.xticks(rotation=0)
plt.savefig('rmf模型分析.png')
对其中apply的 和 方法的理解,第一个apply的axis=0 把每列数据传入x
rfm_df[['R','F','M']].apply(lambda x:x-x.mean(),axis=0)
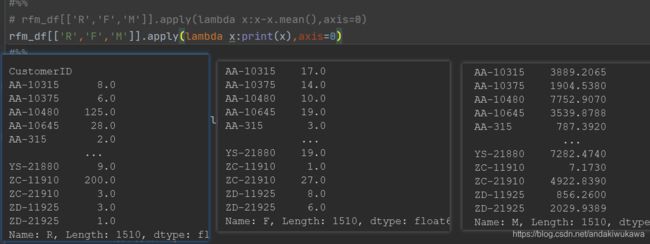
第二个axis=1,把每行数据(一个series)传入rfm_func的x。在方法里相当于对一个series调用了一个lambda
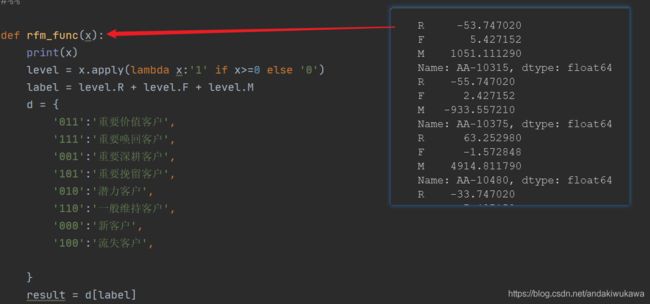
最后的解析结果: