【论文笔记】ConvNeXt论文阅读笔记
paper:A ConvNet for the 2020s
github:https://github.com/facebookresearch/ConvNeXt
自从ViT出现,在分类任务中很快取代各种CNN网络拿下SOTA。ViT的模型设计结构和传统的CNN结构差异很大,会不会是CNN的设计结构限制了CNN的能力呢?如果把CNN的结构设计成和ViT类似,CNN又会有什么样的表现呢?Transformer的设计结构会影响CNN的性能吗?
实验证明,CNN依然有效!仿照Transformer结构,作者对ResNet结构进行修改,实验证明修改后ResNet50的性能超过了Swin-T。
目录
一、网络设计
1、训练策略
2、宏观设计
3、ResNeXt-flops/acc
4、 Inverted Bottleneck
5、大卷积核
6、微观设计
7、网络结构
二、实验结果
一、网络设计
为了便于对比,选择ResNet-50 / Swin-T两个网络,他们的flops都在4.5*1e9。通过对ResNet50一步一步修改,检验ViT结构在CNN网络上的有效性。
ResNet的指标都是使用3个不同的随机数种子在ImageNet-1K训练后取平均得到的。
1、训练策略
训练策略对模型的性能表现非常重要,类似DeiT和Swin Transformer的训练策略,将ResNet的epochs从90增加到300,使用AdamW优化器,数据增强:MixUP、Cutmix、RandAugment、RandomErasing,Stochastic Depth正则化,Label Smoothing。
修改了训练策略后,ResNet-50的准确率从76.1%提升到78.8%,增加了2.7%。
下述改进均在此基础上。
2、宏观设计
Swin Transformer和CNN网络一样有着多Stage设计,每个Stage输出不同分辨率的特征图。从宏观设计对ResNet修改考虑2点:stage计算比率和Stem模块的结构。
(1)Stage计算比率
Swin-T不同stage的计算比例为![]() ,更大的Swin Transformer比率是
,更大的Swin Transformer比率是![]() ,ResNet50各stage的block比率是
,ResNet50各stage的block比率是![]() ,对ResNet50 stage修改,使其block比率为
,对ResNet50 stage修改,使其block比率为![]() 。
。
修改后ResNet50的准确率从78.8%上升到79.4%,下述改进均在此基础上。
(2)Stem
ResNet的Stem模块组成:一个步长为2卷积核7x7的卷积层,一个步长为2的maxpool,由此得到分辨率1/4的特征图。Swin Transformer的Stem(就是vit的PatchEmbedding层)是一个步长为4卷积核4x4的卷积。类似Swin,将ResNet50的Stem改为步长为4卷积核4x4的卷积层(non-overlapping卷积)。
修改后ResNet50的准确率从79.4%上升到79.5%,下述改进均在此基础上。
3、ResNeXt-flops/acc
ResNeXt在flops/acc上有更好的权衡,它的原则是:多使用分组卷积同时增加特征通道。
类似这种思想,将ResNet的通道数增加到和Swin-T相同(64->96),将卷积替换为深度可分离卷积(depth-wise卷积和point-wise卷积替换普通卷积)。
修改后ResNet50的准确率从79.5%上升到80.5%,下述改进均在此基础上。
4、 Inverted Bottleneck
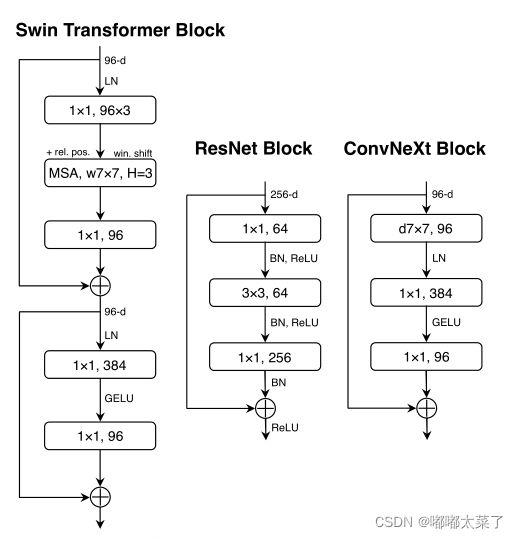
Transformer模块中,隐藏层MLP的维度是输入的4倍,如下图,它是inverted bottleneck结构。
将ResNet的Bottleneck结构改为Inverted Bottleneck,如下图b:
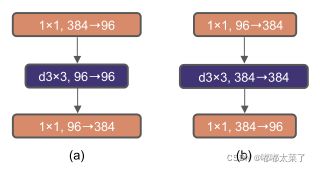
修改后ResNet50的准确率从80.5%上升到80.6%,下述改进均在此基础上。
5、大卷积核
ViT的Attention能够获得全局感受野,CNN通常使用小卷积核叠加的方法来增加感受野。Swin Transformer引入了最小窗口7x7的局部注意力模块,与之类似,将ResNet的卷积核增大到7x7。具体流程如下:
(1)上移深度可分离卷积层
Transformer中,MSA(multi-head self attention)放在MLP之前,因为MSA的计算量大,通常有较少的通道数。与之类似,将ResNet的Inverted Bottleneck中depth-wise卷积上移,让其在通道数较少的特征图上计算。
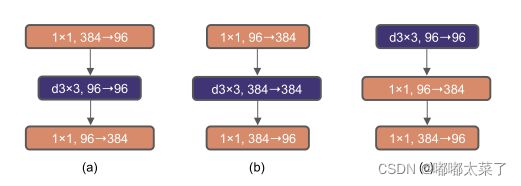
修改后ResNet50的准确率从80.5%下降到79.9%,同时flops下降了4.1G,下述改进均在此基础上。
(2)增加卷积核尺寸
类似Swin Transformer的局部窗口,将上一步的3x3卷积增加到7x7。
修改后ResNet50的准确率从79.9%上升到80.5%,下述改进均在此基础上。
6、微观设计
本小节将更关注于网络的细节设计,包括激活函数和归一化层的选择。
(1)使用GELU激活函数
GELU比RELU更平滑,在Transformer中广泛使用GELU。将ResNet的激活函数由RELU替换为GELU。
替换激活函数后ResNet50的准确率从80.5%上升到80.6%,下述改进均在此基础上。
(2)更少的激活函数
Transformer的激活函数很少,只有MLP之间有一个GELU激活函数。而ResNet Block有多个激活函数。
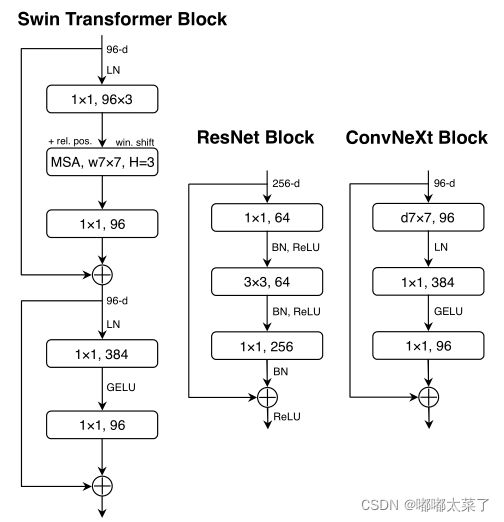
类似Transformer,减少激活函数数量,修改ResNet Block,只保留一个激活函数。
减少激活函数后ResNet50的准确率从80.7%上升到81.3%,下述改进均在此基础上。
(3)更少的归一化层
Transformer的归一化层很少,ResNet block的归一化层比较多,减少ResNet的归一化层数量,如上图。
另外:作者发现在block入口添加BN并不会提升模型性能。
减少归一化层后ResNet50的准确率从81.3%上升到81.4%,下述改进均在此基础上。
(4)使用LayerNorm替代BatchNorm
Transformer使用LayerNorm,ResNet使用BatchNorm,将ResNet的BatchNorm修改为LayerNorm。
修改归一化层后ResNet50的准确率从81.4%上升到81.5%,下述改进均在此基础上。
归一化参考资料:深度学习归一化方法
(5)分开下采样层
ResNet的下采样模块(步长为2的3x3卷积实现)包含在stage中,而Swin Transformer中将下采样层单独划分出来。类似地,修改ResNet,在stage间加入步长为2的2x2卷积层实现下采样。
研究发现:在特征图分辨率改变前和后加入归一化层都可以稳定训练。
修改归一化层后ResNet50的准确率从81.5%上升到82.0%,下述改进均在此基础上。
7、网络结构
结合以上所有修改,得到了ConvNeXt,下图为ResNet50\ConvNeXt-T\Swin-T的模型结构。

其他的几个版本:

二、实验结果
1、图像分类
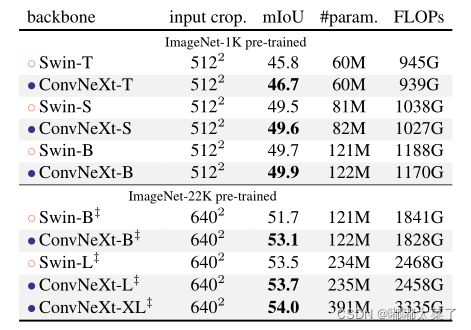
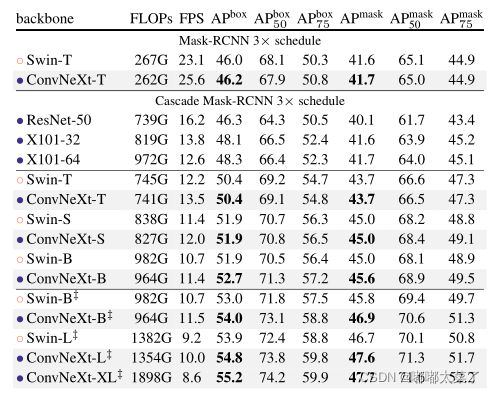
ConvNeXt在ImageNet1k上的性能已经超过Swin。

2、目标检测
3、语义分割