2022_TIP_DSNet
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images
通过利用未标记的RGB图像来增强rgb-d显着性检测
1. 动机
1) 用于监督学习的像素级注释既昂贵又耗时。
2) 与RGB图像相比,成对的rgb-d图像更难以收集。
2. 解决方法
提出 Dual-Semi RGB-D Salient Object Detection Network(DS-Net),利用没有标记的RGB图像来增强 RGB-D 显著性检测。
第一步:设计了一个depth decoupling convolutional neural network (DDCNN),包含两个分,depth estimation branch and a saliency detection branch.
1. depth estimation branch:由RGB-D 图像训练,然后用于估计所有未标记的RGB图像的伪深度图,以形成配对数据。
2. saliency detection branch:用于融合RGB特征和深度特征以预测rgb-d显著性。
第二步:将第一步中的DDCNN作为骨干网络,用于半监督的教师学生框架。
第三步:介绍了未标记数据的中间注意力和显著图的一致性损失(consistency loss ),以及标记数据的监督深度和显著性损失。
3. 网络框架

用带标记的数据训练深度分支,将得到的模型用于生成未标记的RGB图片的深度图,
3.1DDCNN
包含两个分支,depth estimation branch and a saliency detection branch。给定一对输入的rgb-d图像: 将RGB图像传递到编码器以生成RGB特征![]() ,深度图像送到另一个编码器提取深度特征
,深度图像送到另一个编码器提取深度特征![]() 。
。
在depth estimation branch 中,使用“Conv(3×3) → BN → ReLU → Conv(3×3)”的卷积块将每个RGB特征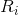 分解为两个特征:(1)用于估计深度图的深度感知特征
分解为两个特征:(1)用于估计深度图的深度感知特征![]() ,(2)用于预测显著性的深度消除特征
,(2)用于预测显著性的深度消除特征![]() 。深度感知特征
。深度感知特征![]() 上采样到与
上采样到与![]() 相同大小,并应用“Conv(3×3) → Conv(1×1)”的卷积块串联在一起以预测深度图。此外,我们融合
相同大小,并应用“Conv(3×3) → Conv(1×1)”的卷积块串联在一起以预测深度图。此外,我们融合![]() 和
和![]() 来重建RGB特征
来重建RGB特征![]() ,并计算重建损失
,并计算重建损失![]() 来正则化解耦过程:
来正则化解耦过程:![]()
其中,![]() 表示“Conv(3×3) → BN → ReLU → Conv(3×3)”的卷积块,Cat(·) 表示特征级联操作,
表示“Conv(3×3) → BN → ReLU → Conv(3×3)”的卷积块,Cat(·) 表示特征级联操作,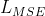 表示均方误差mean square error (MSE) 损失。
表示均方误差mean square error (MSE) 损失。
在saliency detection branch中,设计了一个深度诱导融合模块(DIM),将深度消除特征![]() 和 与每个CNN层的两个深度特征(
和 与每个CNN层的两个深度特征(![]() 和
和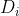 )融合在一起,生成融合特征
)融合在一起,生成融合特征![]() 。最后迭代合并
。最后迭代合并![]() ,采用3×3卷积,1×1卷积和sigmiod 激活函数生成显著图。两个相邻的特征进行相加融合时,低分辨率特征上采样到与高分辨率特征相同大小,高分辨率则是经过ASPP模块(r=1,6,8,12),目的是细化浅层特征,最后将4个分支串联再经过1×1卷积。
,采用3×3卷积,1×1卷积和sigmiod 激活函数生成显著图。两个相邻的特征进行相加融合时,低分辨率特征上采样到与高分辨率特征相同大小,高分辨率则是经过ASPP模块(r=1,6,8,12),目的是细化浅层特征,最后将4个分支串联再经过1×1卷积。
3.1.1深度诱导融合模块(DIM)
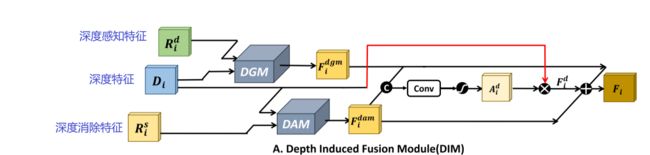
1. 深度门控模块 (DGM) 来融合来自输入深度图的深度特征和来自深度估计分支的![]() ,生成融合特征
,生成融合特征![]() 。2. 采用深度感知模块 (DAM) 融合
。2. 采用深度感知模块 (DAM) 融合![]() 和,以获得新的特征
和,以获得新的特征![]() 。此外,拼接
。此外,拼接![]() 和
和![]() ,并应用3×3卷积层和sigmiod 激活函数,目的是学习用于加权深度特征的注意力图
,并应用3×3卷积层和sigmiod 激活函数,目的是学习用于加权深度特征的注意力图![]() ,
,![]() 与生成新的特征
与生成新的特征![]() ,最后将
,最后将![]() ,
,![]() ,
,![]() 相加生成DIM的输出特征
相加生成DIM的输出特征![]() :
:
![]()
3.1.2 深度感知模块(DAM)
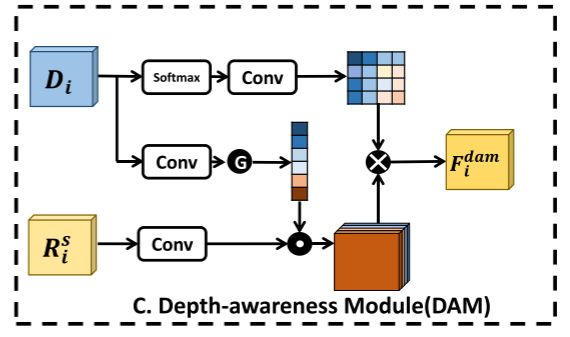
考虑到低质量深度图中的冗余和噪声以及RGB和深度特征之间的内在差异,我们设计了一种有效的融合方法来抑制噪声,并利用了两种模态的特征![]() 和的互补信息。受CBAM 的启发设计了DAM,配备了通道注意和空间注意操作。这是通过在上应用通道注意操作以加权
和的互补信息。受CBAM 的启发设计了DAM,配备了通道注意和空间注意操作。这是通过在上应用通道注意操作以加权![]() 的不同通道来实现的,然后在上计算空间注意以重新校准
的不同通道来实现的,然后在上计算空间注意以重新校准![]() 的逐像素显著性信息以获得
的逐像素显著性信息以获得![]() :
:
![]()
Catt(·) 包括3 × 3卷积和全局平均池化。空间注意Satt(·) 由具有softmax函数的3 × 3卷积组成。![]() 表示逐通道乘法,而 “⊗” 表示逐元素乘法。
表示逐通道乘法,而 “⊗” 表示逐元素乘法。
3.1.3 深度门控模块DGM

丰富了来自不同深度模态的深度表示 ,方法是考虑用于学习显著性线索的远程像素依赖性。首先,我们首先在![]() 上应用一个3 × 3卷积层,将合成特征重塑为中间C × HW特征图,在
上应用一个3 × 3卷积层,将合成特征重塑为中间C × HW特征图,在![]() 上应用另一个3 × 3卷积层,将合成特征重塑为另一个中间HW × C特征图,然后将两个中间特征相乘,生成大小为HW × HW的非局部相似性矩阵。此外,我们在上应用3 × 3卷积层,并将所得特征重塑为中间的HW × C特征图,然后将其与非局部相似性矩阵相乘。之后,我们将由乘法产生的特征HW ×C重塑为大小为H × W × C的特征图,该特征图经过3 × 3卷积以获得DGM的特征
上应用另一个3 × 3卷积层,将合成特征重塑为另一个中间HW × C特征图,然后将两个中间特征相乘,生成大小为HW × HW的非局部相似性矩阵。此外,我们在上应用3 × 3卷积层,并将所得特征重塑为中间的HW × C特征图,然后将其与非局部相似性矩阵相乘。之后,我们将由乘法产生的特征HW ×C重塑为大小为H × W × C的特征图,该特征图经过3 × 3卷积以获得DGM的特征![]() 。
。