【CV】多目标跟踪-opencv+yolo+deepsort
【CV】多目标跟踪-opencv+yolo+deepsort
目录
- 1. 参考文献
-
- 1.1. 数据集
- 1.2. yolo教程
- 1.3. deepsort教程
- 1.4. 集成软件
- 2. 数据预处理
- 3. 生成训练集
-
- 3.1. labelimg标签
- 3.2. img生成txt文件
- 4. 目标检测-yolo
-
- 4.1. yolo框架下载
- 4.2. 改data-data.yaml
- 4.3. 改models-yolo.yaml
-
- 4.3.1. 改网络骨架
- 4.3.2. 改anchor框
- 4.4. 改utils文件路径
- 4.5. 改精度half为float
- 4.6. 下载预训练pt文件
- 4.7. yolo训练
-
- 4.7.1. 调参
- 4.7.2. 运行
- 4.7.3. 结果
- 4.8. yolo检测
-
- 4.8.1. 运行
- 4.8.2. 报错
- 4.8.3. 结果
- 4.9. 提高训练精度
-
- 4.9.1. 检查训练集
- 4.9.2. 改预设锚定框
1. 参考文献
1.1. 数据集
细胞跟踪挑战赛
http://celltrackingchallenge.net/2d-datasets/
自制VOC2007数据集——train、trainval、val、test文件的生成
https://blog.csdn.net/weixin_40161974/article/details/104901928
1.2. yolo教程
yolov3训练自己的数据集
https://blog.csdn.net/perfectdisaster/article/details/125674868
1.3. deepsort教程
教程:https://www.iotword.com/3391.html
代码:https://github.com/HowieMa/DeepSORT_YOLOv5_Pytorch
1.4. 集成软件
MATLAB科研图像处理——细胞追踪
https://zhuanlan.zhihu.com/p/368919577
2. 数据预处理
opencv 闭运算
opencv Sobel算子
3. 生成训练集
3.1. labelimg标签
创建如下格式的文件夹

下载插件:pip install labelimg
选择保存格式为yolo,打标签
 获得含标签结果的txt文件
获得含标签结果的txt文件
3.2. img生成txt文件
用多个txt文件,生成含所有有标签路径的txt文件
用多张图片,生成含有所有图片路径的txt文件
'''
image gen all_images_txt
generate file name in a big file_box
'''
import glob
path = r'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label'
def generate_train_and_val(image_path, txt_file):
print(image_path)
print(txt_file)
with open(txt_file, 'w') as tf:
print('open')
print(glob.glob(image_path + '\*.png'))
for jpg_file in glob.glob(image_path + '\*.png'):
tf.write(jpg_file + '\n')
# print(glob.glob(image_path + '\*.jpg'))
# for jpg_file in glob.glob(image_path + '\*.jpg'):
# tf.write(jpg_file + '\n')
generate_train_and_val(path + r'\images\train', path + r'\\train.txt')
generate_train_and_val(path + r'\images\val', path + '\\val.txt')
疑问
多目标跟踪时,一张图中有很多目标,是否要把整张图作为一个训练样本?还是只需要截取包含部分目标的图?
4. 目标检测-yolo
4.1. yolo框架下载
教程:https://www.iotword.com/3391.html
代码:https://github.com/HowieMa/DeepSORT_YOLOv5_Pytorch
4.2. 改data-data.yaml

4.3. 改models-yolo.yaml
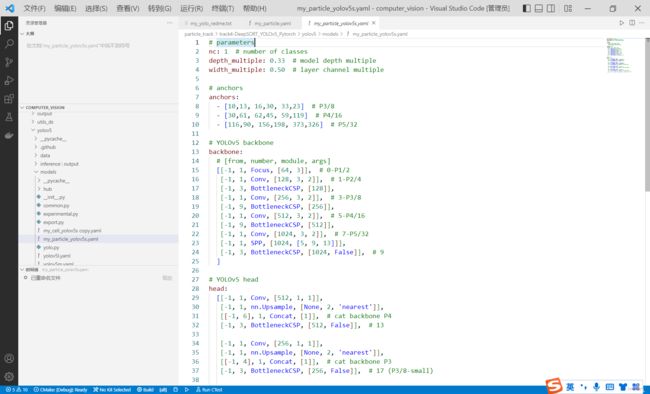
4.3.1. 改网络骨架
class改为自己数据集的类别数
4.3.2. 改anchor框
YOLOv5的anchor设定
https://blog.csdn.net/weixin_43427721/article/details/123608508
科普:目标检测Anchor是什么?怎么科学设置?[附代码]
https://blog.51cto.com/u_15671528/5631790
对于目标检测的anchor 设置,一定要根据您的数据分布设置合理的anchor,另外,也要考虑是否是归一化的anchor大小,或者是否做了改变图像长宽比的resize。
- class只有一种时怎么设置anchor?
4.4. 改utils文件路径
如果采用别人的框架,一个master里既有yolo又有deepsort,deepsort会直接调用yolo,这时,yolo模块中的文件的相对路径可能需要手动切换


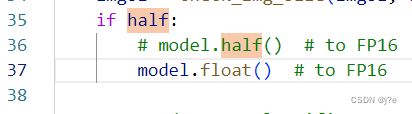
4.5. 改精度half为float
需要将detect文件代码中的所有half改为float,map才会上升
4.6. 下载预训练pt文件
4.7. yolo训练
4.7.1. 调参
conf置信度
iou交并比
YOLO 检测中有两个阈值参数,conf置信度比较好理解,但是IOU thres比较难理解。
IOU thres过大容易出现一个目标多个检测框;IOU thres过小容易出现检测结果少的问题。
4.7.2. 运行
:: cmd
conda activate F:\CS\Anaconda\envs\deeplearning
cd D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5
::使用默认文件夹的权重
python train.py --batch 16 --epoch 100 --data data/my_particle.yaml --cfg models/my_particle_yolov5s.yaml --weights weights/yolov5s.pt
::使用自己训练的权重
python train.py --batch 16 --epoch 100 --data data/my_particle.yaml --cfg models/my_particle_yolov5s.yaml --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp8\weights\last.pt
经过33个Epoch后,mAP才开始大于0,有时候可能要更久
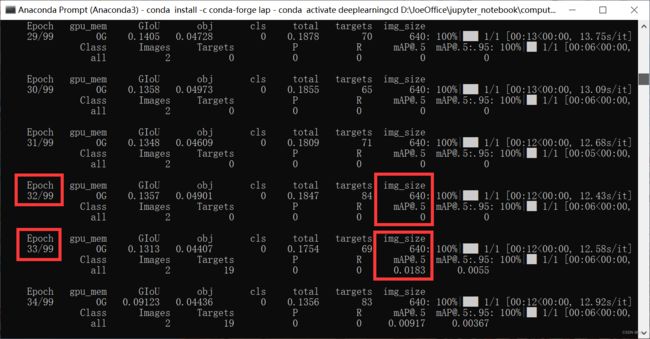
4.7.3. 结果
exp10:0-100 Epoch

exp11:100-200 Epoch

exp12:200-300 Epoch
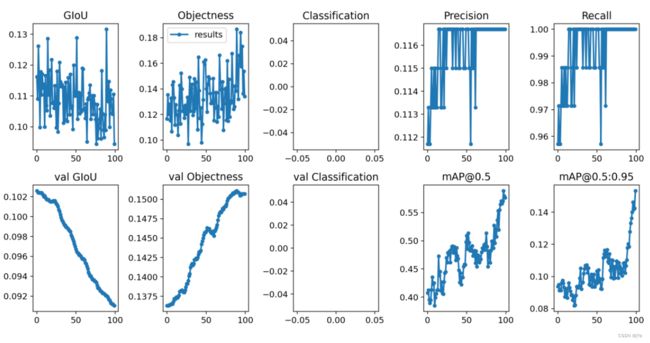
4.8. yolo检测
4.8.1. 运行
:: cmd
conda activate F:\CS\Anaconda\envs\deeplearning
cd D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5
::检测1
python detect.py --source D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\images\val\PEG_fliter_5.png --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp8\weights\last.pt --device 'cpu' --conf-thres 0.1 --iou-thres 0.1
::检测2
python detect.py --source D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\images\val\PEG_fliter_5.png --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp9\weights\best.pt --device 'cpu' --conf-thres 0.1 --iou-thres 0.1
4.8.2. 报错
'''
CUDA unavailable, invalid device 'cpu' requested
如下,把部分代码注释掉即可
'''
def select_device(device='', batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
cpu_request = device.lower() == 'cpu'
# if device and not cpu_request: # if device requested other than 'cpu'
# os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
# assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
4.8.3. 结果
conf取的越小,能检测出来的框越多;iou取的越大,重叠的框越多
–conf-thres 0.5 --iou-thres 0.1

–conf-thres 0.6 --iou-thres 0.1
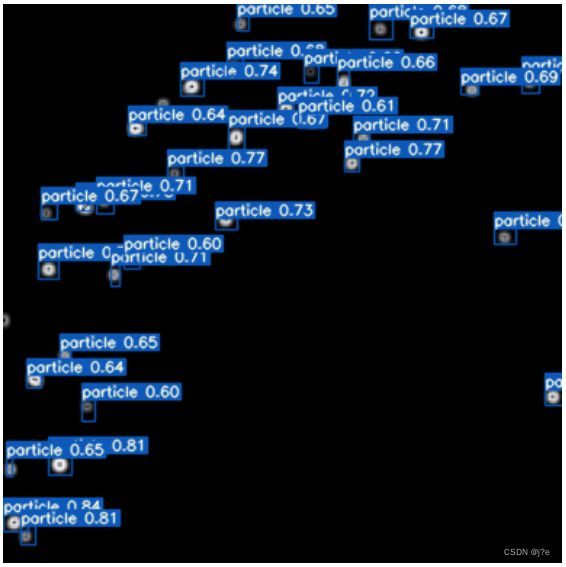
–conf-thres 0.7 --iou-thres 0.1 ——

4.9. 提高训练精度
4.9.1. 检查训练集
图片img和标签txt数量、匹配是否有错?
比如,如果训练集图片的index从0开始,放4张ig,素材应该取0,1,2,3,而不是0,1,2,3,4
4.9.2. 改预设锚定框
先明确anchor的单位是多少?
调整yolo.yaml中的anchors
# anchors
anchors:
- [5,6, 7,8, 9,10] # P3/8
- [25,26, 27,28, 29,30] # P4/16
- [35,36, 37,38, 39,40] # P5/32
# anchors:
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32