YOLOv1
什么是YOLOv1?
一、网络结构

看大佬的总结,目前目标检测领域网络结构的总体框基本上都包含了上面三个部分:Backbone、Neck network和detect head.
Backbone用作特征提取,Neck network用于对Backbone提取到的特征进行整合,Detect head用于对整合后的特征进行预测。
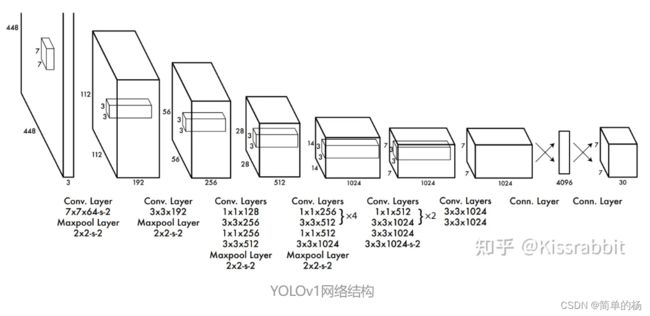
下面是YOLOv1d的网络结构(预测过程)

1.Backbone
Backbone这个骨干网络是用来做特征提取的,但是至于到底提取了什么特征,这个我们是无从知晓的,因为神经网络对于我们来说仍然是一个黑盒子,我们只关注什么样的Backbone可以为我们更好的提取特征信息,下面梳理一下Backboned分类:
(1)大型网络
VGGNet:包括VGG19
ResNet:ResNet50和ResNet101
ResNexT:
ResNet+DCN:
DarkNet:DarkNet19和DarkNet53,这里YOLOv1的骨干网络用的就是DarkNet19。
CspResNet:在减小网络的参数量的同时还能提高网络的性能。
(2)轻量型网络
MobileNet:谷歌的工作
ShuffleNet:旷世的工作
(3)YOLOv1的Backbone
输入:448*448*3,网络的最后是两个全连接层,由于全连接层要求特征图固定尺寸,所以需要对输入网络的图片做resize;
conv+FC:网络用1*1卷积核和3*3卷积核来做通道下降,在卷积和全连接操作中使用的激活函数是Leaky ReLU做激活函数,在最后一个全连接层使用的是线性激活函数。
输出:网络在最后一层全连接层输出的是1470*1的向量,在通过一个reshape操作,这个1470*1的向量被转换为7*7*30的张量。
这个7*7*30的张量贴个图:
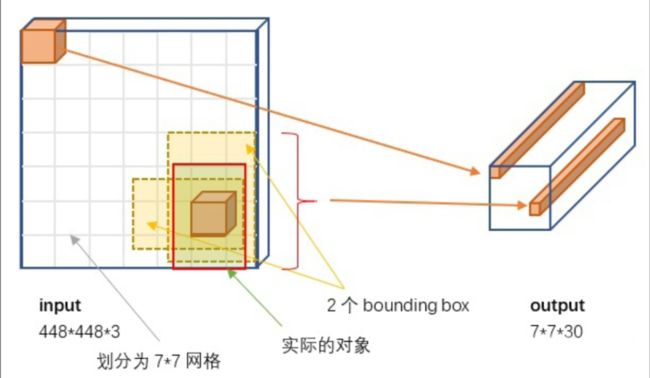

对这个7*7*30的进行解释:
7*7网格:图像输入到网络后会被划分为7*7d的网格,同时网络最后输出的7*7*30的张量与它相对应。
30维的张量:每个网格会输出一个30维的向量,这个30维向量包含的信息有预测的2个bouning box的置信度,2个预测框的信息和20个类别的概率。
2个预测框的信息:包含框的中心点的坐标(x,y)和框的宽高(w,h)
2个bounding box的置信度:每个置信度包含两个信息,一个是这个框含有背景的概率,一个是预测框和真实框的iou的值。
20个类别的概率值:每个网格都会预测出20个类别的概率值
2.Neck network
图像经过Backbone提取特征之后,输出的是非常粗糙的特征图,具有相当大的感受野,因此这么这么大的感受野容易造成检测对象的“失焦”,而且对于小物体而言非常不友好。
3.Detect head
我一直对这个部分比较好奇,没想到看大佬说的这么简单,至少这个大佬是这么说的,就是对Backbone和Neck输出的特征图进行几个堆叠卷积的操作:

二、训练过程
1.特征提取阶段
特征提取阶段主要是用的是yolov1的骨干网络,那么具体是怎么提取的呢?
2.
三、预测过程
四、YOLOv1的缺点
1.一个网格只能预测一个类别,当两个物体落在这个网格中时,但是一个网格只能预测一个目标;
2.损失函数设计有问题,这样导致模型的预测的定位误差较大;
3.图片经过64倍下采样后,最后网络输出的特征图会变成非常粗糙的特征图。
参考资料
【目标检测论文阅读】YOLOv1 - 知乎 (zhihu.com)
1.1 YOLO入门教程:YOLOv1(1)-目标检测结构浅析 - 知乎 (zhihu.com)