第七章:PyTorch可视化
7.1 可视化网络结构
随着深度神经网络做的的发展,网络的结构越来越复杂,我们也很难确定每一层的输入结构,输出结构以及参数等信息,这样导致我们很难在短时间内完成debug。因此掌握一个可以用来可视化网络结构的工具是十分有必要的。
类似的功能在另一个深度学习库Keras中可以调用一个叫做model.summary()的API来很方便地实现,调用后就会显示我们的模型参数,输入大小,输出大小,模型的整体参数等,但是在PyTorch中没有这样一种便利的工具帮助我们可视化我们的模型结构。
为了解决这个问题,人们开发了torchinfo工具包 ( torchinfo是由torchsummary和torchsummaryX重构出的库, torchsummary和torchsummaryX已经许久没更新了) 。本节我们将介绍如何使用torchinfo来可视化网络结构。
经过本节的学习,你将收获:
- 可视化网络结构的方法
7.1.1 使用print函数打印模型基础信息
在本节中,我们将使用ResNet18的结构进行展示。
import torchvision.models as models
model = models.resnet18()
通过上面的两步,我们就得到resnet18的模型结构。在学习torchinfo之前,让我们先看下直接print(model)的结果。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
... ...
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
我们可以发现单纯的print(model),只能得出基础构件的信息,既不能显示出每一层的shape,也不能显示对应参数量的大小,为了解决这些问题,我们就需要介绍出我们今天的主人公torchinfo。
7.1.2 使用torchinfo可视化网络结构
- torchinfo的安装
# 安装方法一
pip install torchinfo
# 安装方法二
conda install -c conda-forge torchinfo
- torchinfo的使用
trochinfo的使用也是十分简单,我们只需要使用torchinfo.summary()就行了,必需的参数分别是model,input_size[batch_size,channel,h,w],更多参数可以参考documentation,下面让我们一起通过一个实例进行学习。
import torchvision.models as models
from torchinfo import summary
resnet18 = models.resnet18() # 实例化模型
summary(resnet18, (1, 3, 224, 224)) # 1:batch_size 3:图片的通道数 224: 图片的高宽
- torchinfo的结构化输出
=========================================================================================
Layer (type:depth-idx) Output Shape Param #
=========================================================================================
ResNet -- --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
=========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
=========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
=========================================================================================
我们可以看到torchinfo提供了更加详细的信息,包括模块信息(每一层的类型、输出shape和参数量)、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等
注意:
但你使用的是colab或者jupyter notebook时,想要实现该方法,summary()一定是该单元(即notebook中的cell)的返回值,否则我们就需要使用print(summary(…))来可视化。
7.2 CNN可视化
卷积神经网络(CNN)是深度学习中非常重要的模型结构,它广泛地用于图像处理,极大地提升了模型表现,推动了计算机视觉的发展和进步。但CNN是一个“黑盒模型”,人们并不知道CNN是如何获得较好表现的,由此带来了深度学习的可解释性问题。如果能理解CNN工作的方式,人们不仅能够解释所获得的结果,提升模型的鲁棒性,而且还能有针对性地改进CNN的结构以获得进一步的效果提升。
理解CNN的重要一步是可视化,包括可视化特征是如何提取的、提取到的特征的形式以及模型在输入数据上的关注点等。本节我们就从上述三个方面出发,介绍如何在PyTorch的框架下完成CNN模型的可视化。
经过本节的学习,你将收获:
- 可视化CNN卷积核的方法
- 可视化CNN特征图的方法
- 可视化CNN显著图(class activation map)的方法
7.2.1 CNN卷积核可视化
卷积核在CNN中负责提取特征,可视化卷积核能够帮助人们理解CNN各个层在提取什么样的特征,进而理解模型的工作原理。
例如在Zeiler和Fergus 2013年的paper中就研究了CNN各个层的卷积核的不同,他们发现靠近输入的层提取的特征是相对简单的结构,而靠近输出的层提取的特征就和图中的实体形状相近了,如下图所示:


在PyTorch中可视化卷积核也非常方便,核心在于特定层的卷积核即特定层的模型权重,可视化卷积核就等价于可视化对应的权重矩阵。下面给出在PyTorch中可视化卷积核的实现方案,以torchvision自带的VGG11模型为例。
首先加载模型,并确定模型的层信息:
import torch
from torchvision.models import vgg11
model = vgg11(pretrained=True)
print(dict(model.features.named_children()))
{'0': Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'1': ReLU(inplace=True),
'2': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'3': Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'4': ReLU(inplace=True),
'5': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'6': Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'7': ReLU(inplace=True),
'8': Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'9': ReLU(inplace=True),
'10': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'11': Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'12': ReLU(inplace=True),
'13': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'14': ReLU(inplace=True),
'15': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
'16': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'17': ReLU(inplace=True),
'18': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
'19': ReLU(inplace=True),
'20': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)}
卷积核对应的应为卷积层(Conv2d),这里以第“3”层为例,可视化对应的参数:
conv1 = dict(model.features.named_children())['3']
kernel_set = conv1.weight.detach()
num = len(conv1.weight.detach())
print(kernel_set.shape)
for i in range(0,num):
i_kernel = kernel_set[i]
plt.figure(figsize=(20, 17))
if (len(i_kernel)) > 1:
for idx, filer in enumerate(i_kernel):
plt.subplot(9, 9, idx+1)
plt.axis('off')
plt.imshow(filer[ :, :].detach(),cmap='bwr')
torch.Size([128, 64, 3, 3])
由于第“3”层的特征图由64维变为128维,因此共有128*64个卷积核,其中部分卷积核可视化效果如下图所示: 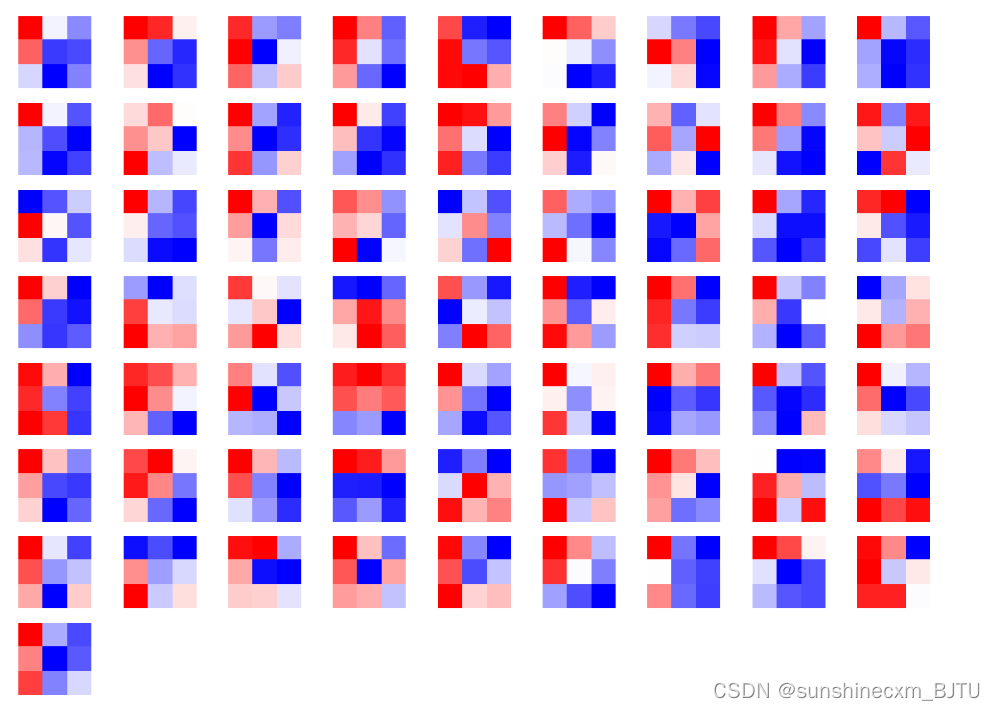
7.2.2 CNN特征图可视化方法
与卷积核相对应,输入的原始图像经过每次卷积层得到的数据称为特征图,可视化卷积核是为了看模型提取哪些特征,可视化特征图则是为了看模型提取到的特征是什么样子的。
获取特征图的方法有很多种,可以从输入开始,逐层做前向传播,直到想要的特征图处将其返回。尽管这种方法可行,但是有些麻烦了。在PyTorch中,提供了一个专用的接口使得网络在前向传播过程中能够获取到特征图,这个接口的名称非常形象,叫做hook。可以想象这样的场景,数据通过网络向前传播,网络某一层我们预先设置了一个钩子,数据传播过后钩子上会留下数据在这一层的样子,读取钩子的信息就是这一层的特征图。具体实现如下:
class Hook(object):
def __init__(self):
self.module_name = []
self.features_in_hook = []
self.features_out_hook = []
def __call__(self,module, fea_in, fea_out):
print("hooker working", self)
self.module_name.append(module.__class__)
self.features_in_hook.append(fea_in)
self.features_out_hook.append(fea_out)
return None
def plot_feature(model, idx, inputs):
hh = Hook()
model.features[idx].register_forward_hook(hh)
# forward_model(model,False)
model.eval()
_ = model(inputs)
print(hh.module_name)
print((hh.features_in_hook[0][0].shape))
print((hh.features_out_hook[0].shape))
out1 = hh.features_out_hook[0]
total_ft = out1.shape[1]
first_item = out1[0].cpu().clone()
plt.figure(figsize=(20, 17))
for ftidx in range(total_ft):
if ftidx > 99:
break
ft = first_item[ftidx]
plt.subplot(10, 10, ftidx+1)
plt.axis('off')
#plt.imshow(ft[ :, :].detach(),cmap='gray')
plt.imshow(ft[ :, :].detach())
这里我们首先实现了一个hook类,之后在plot_feature函数中,将该hook类的对象注册到要进行可视化的网络的某层中。model在进行前向传播的时候会调用hook的__call__函数,我们也就是在那里存储了当前层的输入和输出。这里的features_out_hook 是一个list,每次前向传播一次,都是调用一次,也就是features_out_hook 长度会增加1。
7.2.3 CNN class activation map可视化方法
class activation map (CAM)的作用是判断哪些变量对模型来说是重要的,在CNN可视化的场景下,即判断图像中哪些像素点对预测结果是重要的。除了确定重要的像素点,人们也会对重要区域的梯度感兴趣,因此在CAM的基础上也进一步改进得到了Grad-CAM(以及诸多变种)。CAM和Grad-CAM的示例如下图所示:
相比可视化卷积核与可视化特征图,CAM系列可视化更为直观,能够一目了然地确定重要区域,进而进行可解释性分析或模型优化改进。CAM系列操作的实现可以通过开源工具包pytorch-grad-cam来实现。
- 安装
pip install grad-cam
- 一个简单的例子
import torch
from torchvision.models import vgg11,resnet18,resnet101,resnext101_32x8d
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
model = vgg11(pretrained=True)
img_path = './dog.png'
# resize操作是为了和传入神经网络训练图片大小一致
img = Image.open(img_path).resize((224,224))
# 需要将原始图片转为np.float32格式并且在0-1之间
rgb_img = np.float32(img)/255
plt.imshow(img)

from pytorch_grad_cam import GradCAM,ScoreCAM,GradCAMPlusPlus,AblationCAM,XGradCAM,EigenCAM,FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
target_layers = [model.features[-1]]
# 选取合适的类激活图,但是ScoreCAM和AblationCAM需要batch_size
cam = GradCAM(model=model,target_layers=target_layers)
targets = [ClassifierOutputTarget(preds)]
# 上方preds需要设定,比如ImageNet有1000类,这里可以设为200
grayscale_cam = cam(input_tensor=img_tensor, targets=targets)
grayscale_cam = grayscale_cam[0, :]
cam_img = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
print(type(cam_img))
Image.fromarray(cam_img)

7.2.4 使用FlashTorch快速实现CNN可视化
聪明的你可能要问了,已经202x年了,难道还要我们手把手去写各种CNN可视化的代码吗?答案当然是否定的。随着PyTorch社区的努力,目前已经有不少开源工具能够帮助我们快速实现CNN可视化。这里我们介绍其中的一个——FlashTorch。
(注:使用中发现该package对环境有要求,如果下方代码运行报错,请参考作者给出的配置或者Colab运行环境:https://github.com/MisaOgura/flashtorch/issues/39)
- 安装
pip install flashtorch
- 可视化梯度
# Download example images
# !mkdir -p images
# !wget -nv \
# https://github.com/MisaOgura/flashtorch/raw/master/examples/images/great_grey_owl.jpg \
# https://github.com/MisaOgura/flashtorch/raw/master/examples/images/peacock.jpg \
# https://github.com/MisaOgura/flashtorch/raw/master/examples/images/toucan.jpg \
# -P /content/images
import matplotlib.pyplot as plt
import torchvision.models as models
from flashtorch.utils import apply_transforms, load_image
from flashtorch.saliency import Backprop
model = models.alexnet(pretrained=True)
backprop = Backprop(model)
image = load_image('/content/images/great_grey_owl.jpg')
owl = apply_transforms(image)
target_class = 24
backprop.visualize(owl, target_class, guided=True, use_gpu=True)

- 可视化卷积核
import torchvision.models as models
from flashtorch.activmax import GradientAscent
model = models.vgg16(pretrained=True)
g_ascent = GradientAscent(model.features)
# specify layer and filter info
conv5_1 = model.features[24]
conv5_1_filters = [45, 271, 363, 489]
g_ascent.visualize(conv5_1, conv5_1_filters, title="VGG16: conv5_1")
