【Project】决策树、随机森林、多层感知机、支持向量机在多分问题中的对比
决策树、随机森林、多层感知机、支持向量机在多分问题中的对比
- Introduction
- 数据
- 决策树 (Decision Tree)
- 随机森林 (Random Forest)
- 多层感知机 (Multiple Perceptron)
- 支持向量机 (Support Vector Machine)
- 四种方法学习正确率
Introduction
本篇文章使用决策树 (Decision Tree)、随机森林 (Random Forest)、多层感知机 (Multiple Perceptron)、支持向量机 (Support Vector Machine) 四种算法来进行三分类问题。依赖于python sklearn 代码库。
数据
项目中使用的数据有六个特征,分成三类,从excel表格中读取数据,并使用dataframe进行简单的数据处理。
决策树 (Decision Tree)
在sklearn中,决策树的两种criterion分别是gini和entropy,本文用gini作为判别方式,因为查阅资料,目前基尼系数和信息熵增法没有较大的区别。
以下代码覆盖数据导入、找到决策树最佳深度、画不同深度对应的test正确率、画feature importance柱状图、画混淆矩阵和树的导出。其中树的导出需要安装额外的库,导出的数据直接以PDF格式存在文件夹中。from IPython.display import Image
import pydotplus
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import mglearn
from sklearn.tree import DecisionTreeClassifier
excelFile = r'K2_1013.xlsx'
df=pd.DataFrame(pd.read_excel(excelFile))
#Part1 导入数据
###### For feature subset 1
df4=df[['n-pentane', 'iso-octane', 'n-decane', 'T', 'P','Classification','K1/K2(Pa/Pb)']]
#print(df1.shape) #(270,6)
y_df4=df4['Classification'].values
X_df4=df4.drop(['Classification'],axis=1).values
X_df4_col=df4.drop(['Classification'],axis=1)
X_df4_train, X_df4_test, y_df4_train, y_df4_test = train_test_split(X_df4,y_df4,test_size=0.25,random_state=1)
#print("X_df1_train_shape:", X_df1_train.shape, " y_df1_train_shape:", y_df1_train.shape)
#print("X_df1_test_shape:", X_df1_test.shape," y_df1_test_shape:", y_df1_test.shape)
#clf_df1=DecisionTreeClassifier(random_state=1)
#Part 2 find max depth, plot max depth vs train_accuracy and test_accuracy
def cv_score(d):
clf=DecisionTreeClassifier(random_state=1, max_depth=d)
clf.fit(X_df4_train,y_df4_train)
return(clf.score(X_df4_train, y_df4_train),clf.score(X_df4_test,y_df4_test))
#bestdepth=[]
#for i in range(100):
depth=np.arange(1,7)
scores=[cv_score(d) for d in depth]
#print("scores:", scores)
tr_scores=[s[0] for s in scores]
te_scores=[s[1] for s in scores]
# 找出交叉验证数据集评分最高的索引
tr_best_index = np.argmax(tr_scores)
te_best_index = np.argmax(te_scores)
#bestdepth.append(te_best_index+1)
#print("bestdepth:", te_best_index+1, " bestdepth_score:", te_scores[te_best_index], '\n')
'''
print(bestdepth)
unique_data=np.unique(bestdepth)
print(unique_data)
resdata=[]
for ii in unique_data:
resdata.append(bestdepth.count(ii))
print(resdata)
'''
#对于feature 1, 发现 max_depth=4
#matplotlib inline
from matplotlib import pyplot as plt
depths = np.arange(1,7)
plt.figure(figsize=(6,4), dpi=120)
plt.grid()
plt.xlabel('max depth')
plt.ylabel('Scores')
plt.plot(depths, te_scores, label='test_scores')
plt.plot(depths, tr_scores, label='train_scores')
plt.legend()
plt.show()
print(te_scores)
#part 3 feature importance
clf_df4=DecisionTreeClassifier(random_state=1, max_depth=2)
clf_df4.fit(X_df4_train, y_df4_train)
importance=clf_df4.feature_importances_
#print(importance)
'''
##############################################################calculate total accuracy (the performance)
clf_df4=DecisionTreeClassifier(random_state=1, max_depth=2)
clf_df4.fit(X_df4, y_df4)
total_score=clf_df4.score(X_df4,y_df4)
print("the total accuracy is: ", total_score)
###############################################################
'''
feature_importance_df=pd.DataFrame(importance, index=X_df4_col.columns, columns=['Importance'])
#print(importance_df)
#print(feature_importance_df.values)
feature=feature_importance_df['Importance']
charac=X_df4_col.columns
#charac_array=np.array(charac)
#print(charac_array)
y=[1,2,3,4,5,6]
label=np.array(charac)
plt.figure()
plt.barh(y, feature, height=0.5,tick_label=label)
plt.xlabel('Feature importance')
plt.ylabel('Feature')
plt.show()
#part 4 confusion matrix + export_graphviz
#confusion matrix
import seaborn as sns
from sklearn.metrics import confusion_matrix
from sklearn.tree import export_graphviz
from sklearn import tree
cn=confusion_matrix(y_df4_test, clf_df4.predict(X_df4_test))
sns.heatmap(cn, cmap=sns.hls_palette(8, l=0.8, s=0.5), annot=True)
plt.show()
#export_graphviz
'''
with open("feature1_tree.dot",'w') as f:
f=tree.export_graphviz(clf_df1, feature_names=vec.get_feature_names(), out_file=f)
'''
from IPython.display import Image
import pydotplus
tree4 = tree.export_graphviz(clf_df4, out_file=None, feature_names=charac, class_names=['0','1','2'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(tree4)
graph.write_png("tree4.png")
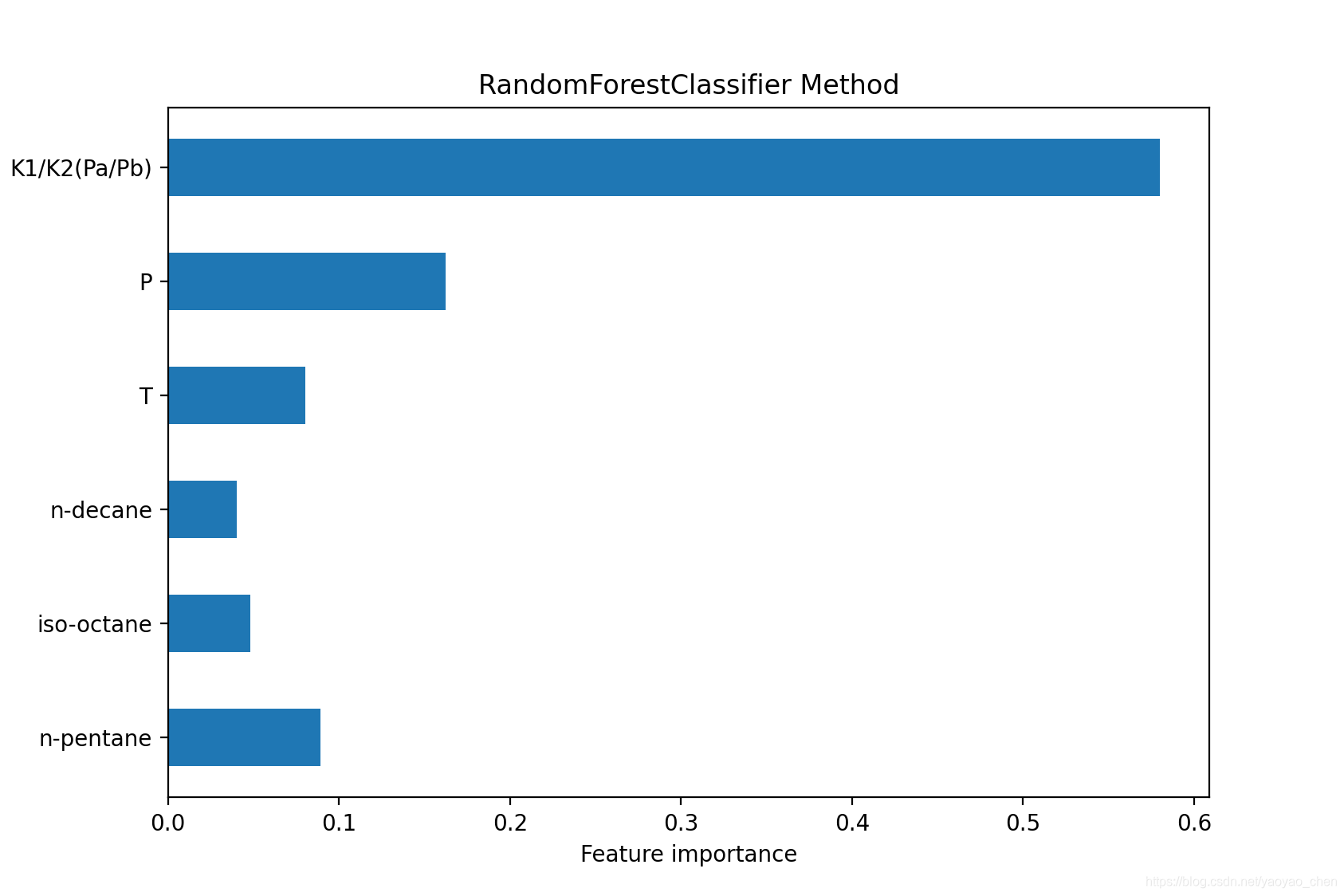
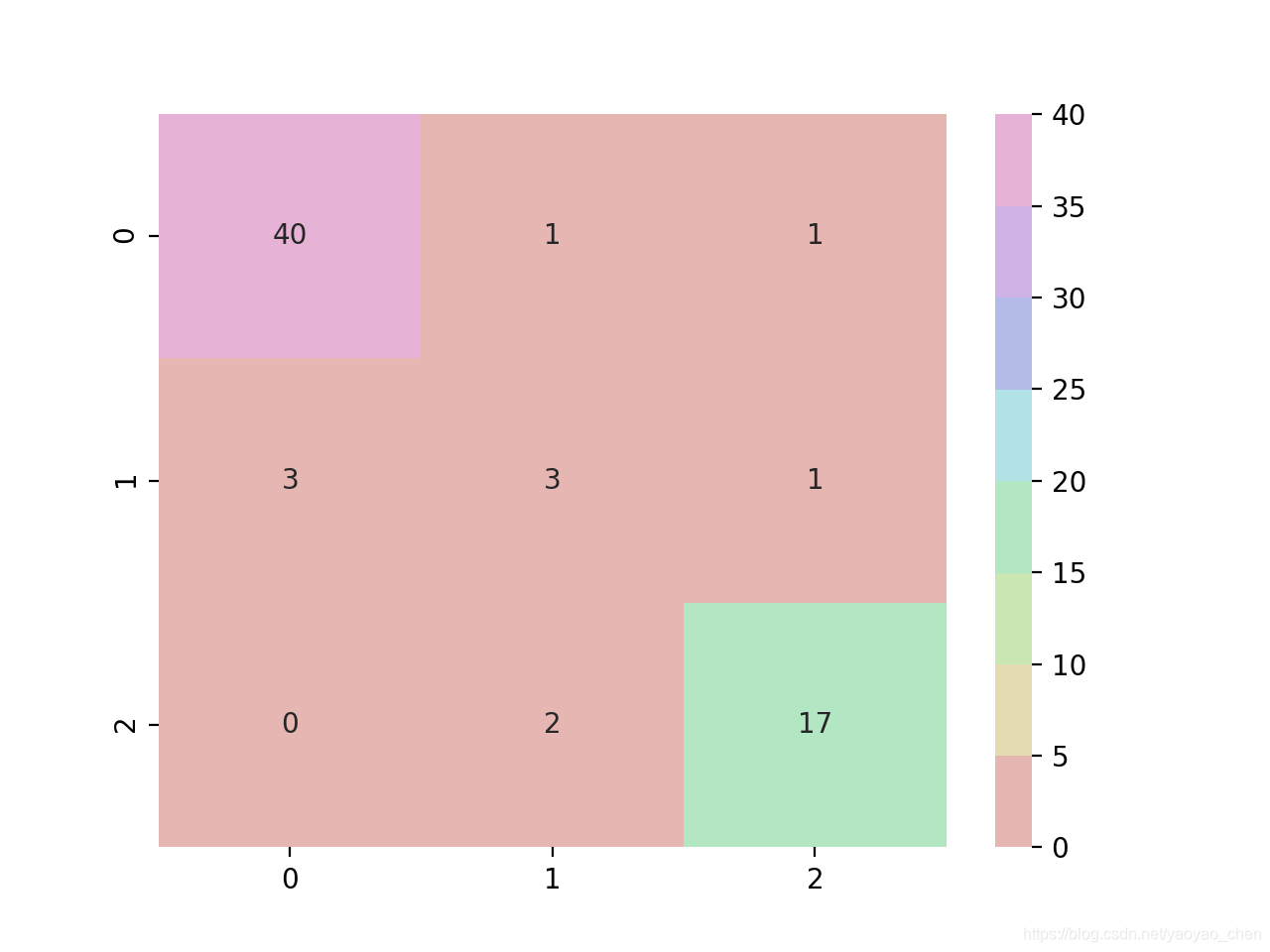
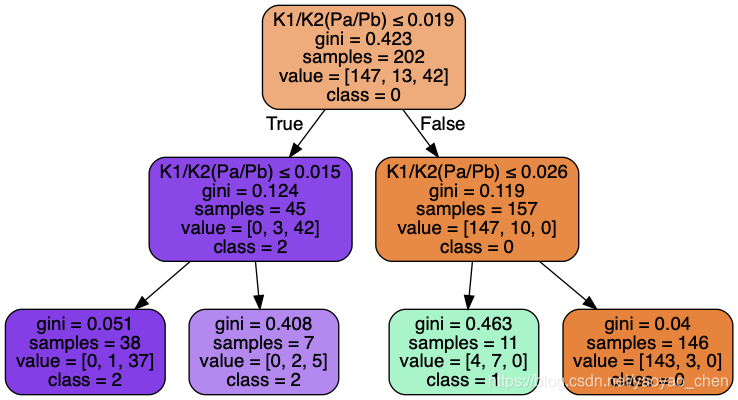
随机森林 (Random Forest)
随机森林与决策树的区别就是,随机森林的结果是所有决策树共同决策的结果。
对于分类来说,决策树的特征选择应该是1/3总特征,(e.g. 总数据有六个features,那么每个决策树应该使用两个features)。
以下代码包括数据导入、feature importance柱状图、画混淆矩阵和输出训练、测试的正确率。
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import mglearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
excelFile = r'K2_1013.xlsx'
df=pd.DataFrame(pd.read_excel(excelFile))
#Part1 导入数据
###### For feature subset 1
df1=df[['n-pentane', 'iso-octane', 'n-decane', 'T', 'P','Classification','K1/K2(Pa/Pb)']]
#print(df1.shape) #(270,6)
y_df1=df1['Classification'].values
X_df1=df1.drop(['Classification'],axis=1).values
X_df1_col=df1.drop(['Classification'],axis=1)
X_df1_train, X_df1_test, y_df1_train, y_df1_test = train_test_split(X_df1,y_df1,test_size=0.25,random_state=1)
#n_estimators integer, optimal=10 决策树的个数 for feature 1 , n=50 has the best accuracy
clf_df1=RandomForestClassifier(n_estimators=50, criterion='gini', max_features=2, random_state=1)
clf_df1.fit(X_df1_train,y_df1_train)
y_pred=clf_df1.predict(X_df1_test)
#print(classification_report(y_df1_test,y_pred))
print("Accuracy of train: ", metrics.accuracy_score(y_df1_train, clf_df1.predict(X_df1_train)))
print("Accuracy of test: ",metrics.accuracy_score(y_df1_test,y_pred))
'''
clf_df1_tree=DecisionTreeClassifier(random_state=1, max_depth=4)
clf_df1_tree.fit(X_df1_train,y_df1_train)
y_pred_tree=clf_df1_tree.predict(X_df1_test)
print("Accuracy of DTC: ",metrics.accuracy_score(y_df1_test,y_pred_tree))
'''
importance=clf_df1.feature_importances_
feature_importance_df=pd.DataFrame(importance, index=X_df1_col.columns, columns=['Importance'])
feature=feature_importance_df['Importance']
charac=X_df1_col.columns
y=[1,2,3,4,5,6]
label=np.array(charac)
plt.figure()
plt.barh(y, feature, height=0.5,tick_label=label)
plt.xlabel('Feature importance')
plt.ylabel('Feature')
plt.title('RandomForestClassifier Method')
plt.show()
#part 4 confusion matrix + export_graphviz
#confusion matrix
import seaborn as sns
from sklearn.metrics import confusion_matrix
from sklearn.tree import export_graphviz
from sklearn import tree
cn=confusion_matrix(y_df1_test, y_pred)
sns.heatmap(cn, cmap=sns.hls_palette(8, l=0.8, s=0.5), annot=True)
plt.show()
多层感知机 (Multiple Perceptron)
多层感知机在分类问题中并没有决策树或随机森林好用,(可能是因为还没有找到最佳hidden_layer、learning rate、iteration time参数),随机森林正确率在本项目中也低于决策树。
以下代码包括输出训练正确率,和混淆矩阵的绘图。
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
import pandas as pd
excelFile = r'K2_1013.xlsx'
df=pd.DataFrame(pd.read_excel(excelFile))
df1=df[['n-pentane', 'iso-octane', 'n-decane', 'T', 'P','Classification','K1/K2(Pa/Pb)']]
y_df1=df1['Classification'].values
X_df1=df1.drop(['Classification'],axis=1).values
scaler=StandardScaler()
scaler.fit(X_df1)
X_df1=scaler.transform(X_df1)
X_df1_train, X_df1_test, y_df1_train, y_df1_test = train_test_split(X_df1,y_df1,test_size=0.25,random_state=1)
cls = MLPClassifier(activation='logistic', hidden_layer_sizes=(150,10), learning_rate='constant',
learning_rate_init=0.01, max_iter=1000, random_state=1, shuffle=True,
solver='lbfgs')
cls.fit(X_df1_train,y_df1_train)
y_pred=cls.predict((X_df1_test))
print('trainscore: ',cls.score(X_df1_train,y_df1_train))
print('testscore: ', cls.score(X_df1_test,y_df1_test))
#print(metrics.confusion_matrix(y_df1_test,y_pred))
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.tree import export_graphviz
from sklearn import tree
cn=confusion_matrix(y_df1_test, cls.predict(X_df1_test))
sns.heatmap(cn, cmap=sns.hls_palette(8, l=0.8, s=0.5), annot=True)
plt.show()
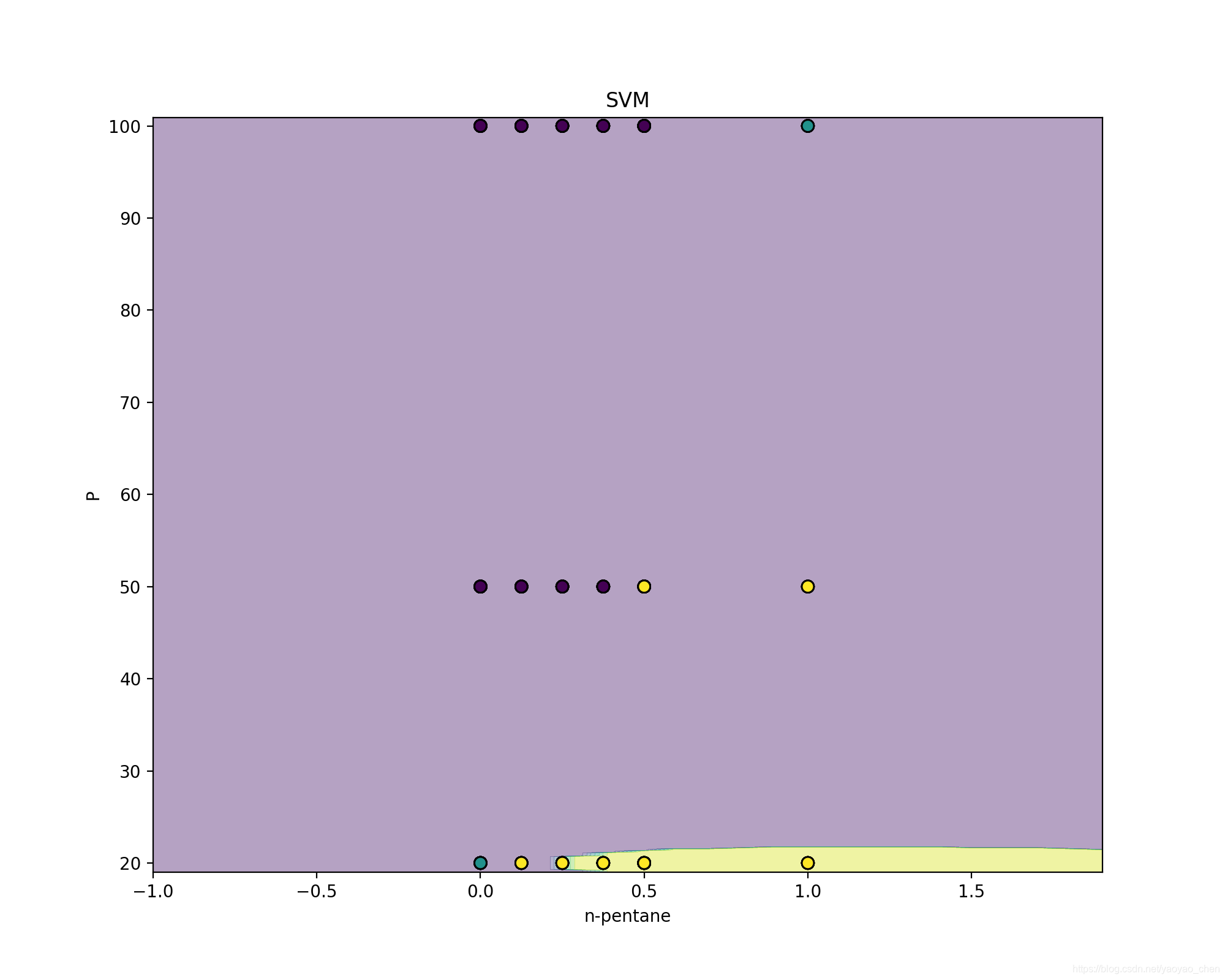
支持向量机 (Support Vector Machine)
支持向量机比较适用于二分问题,对于多分问题的正确率不是很高(可能是因为没找到合适的kernal和参数)。
虽然本项目有6个feature,但在SVM中每次选取两个feature进行training并画图。
以下代码包括train、test正确率的输出,画出SVM学习正确率的图像。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn import datasets
from itertools import product
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
excelFile = r'K2_1013.xlsx'
# 原始数据
df=pd.DataFrame(pd.read_excel(excelFile))
# 仅取以下列的数据
df1=df[['n-pentane', 'iso-octane', 'n-decane', 'T', 'P','Classification','K1/K2(Pa/Pb)']]
# label
y_df1=df1['Classification'].values
# 只取这俩列
X_df1=df[['n-pentane', 'P']].values
X_df1_train, X_df1_test, y_df1_train, y_df1_test = train_test_split(X_df1, y_df1, test_size=0.25, random_state=1)
degree=2
gamma=0.5
coef0=0.1
clf=SVC(C=1, kernel='rbf', gamma=gamma, random_state=1)
clf.fit(X_df1_train,y_df1_train)
#print(clf.score(X_df1_train,y_df1_train))
print('degree', degree, 'gamma', gamma, 'coef0', coef0)
print('trainscore:', accuracy_score(y_df1_train,clf.predict(X_df1_train)))
#print(clf.score(X_df1_test,y_df1_test))
print('testscore:', accuracy_score(y_df1_test,clf.predict(X_df1_test)))
#print ('decision_function:\n', clf.decision_function(X_df1_train))
#print ('\npredict:\n', clf.predict(X_df1_train))
x_min, y_min = np.min(X_df1, axis=0)-1
x_max, y_max = np.max(X_df1, axis=0)+1
#np.meshgrid 从一个坐标向量中返回一个坐标矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(1, 1, sharex='col', sharey='row', figsize=(10, 8))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.xlabel('n-pentane')
plt.ylabel('P')
#contourf画三维等高线图,对等高线间的区域进行填充
axarr.contourf(xx, yy, Z, alpha=0.4)
axarr.scatter(X_df1[:, 0], X_df1[:, 1], c=y_df1, s=50, edgecolor='k')
axarr.set_title('SVM')
plt.show()
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.tree import export_graphviz
from sklearn import tree
cn=confusion_matrix(y_df1_test, clf.predict(X_df1_test))
sns.heatmap(cn, cmap=sns.hls_palette(8, l=0.8, s=0.5), annot=True)
plt.show()
四种方法学习正确率
本项目用了两组数据进行学习,图中用1.3 ms 和 1.4 ms进行表示。图中可以看出DTC具有较强稳定性,且正确率较高,是一种很好的分类算法。
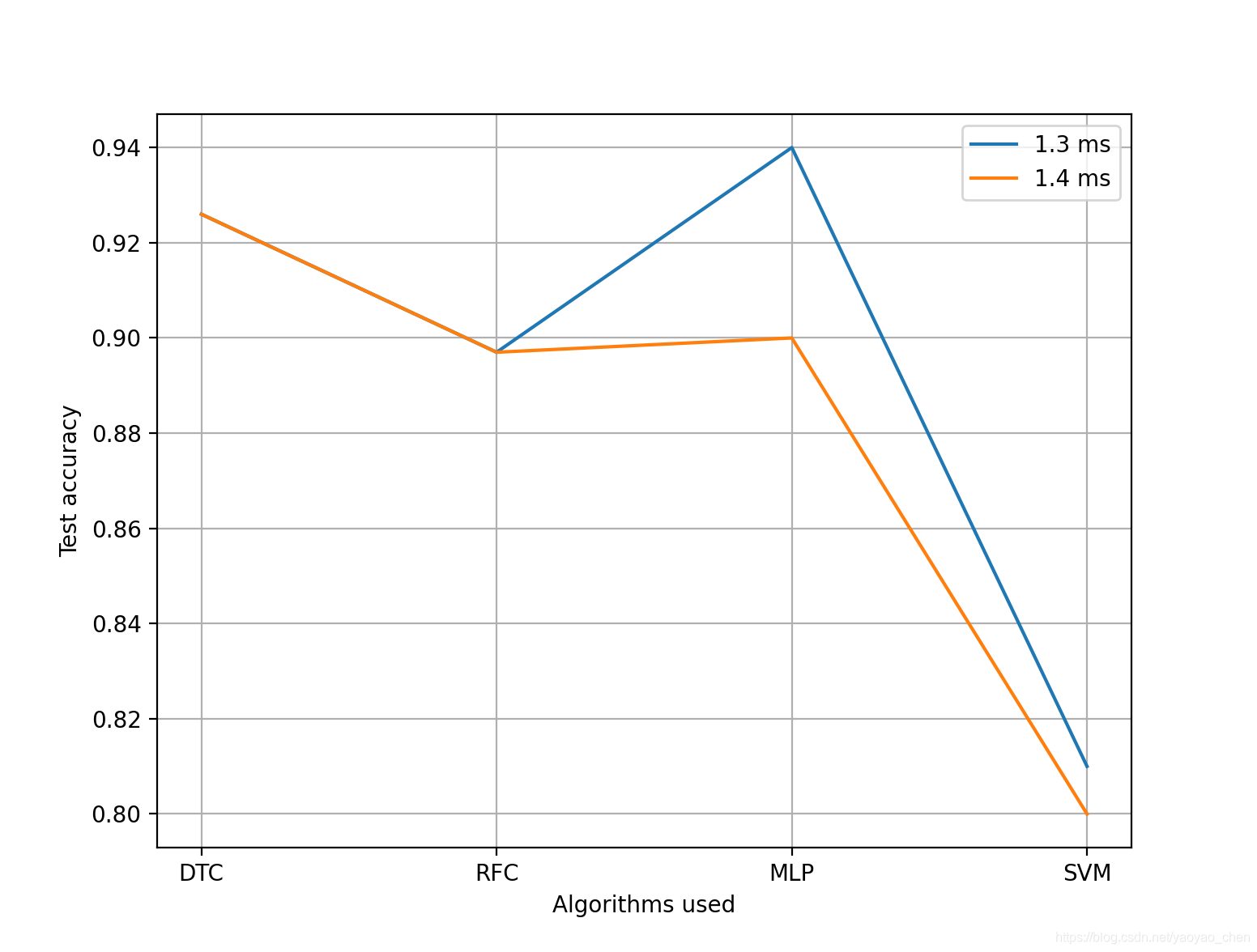
另外,决策树在调参方面极具优势。简易情况下需要调整的参数:
- 决策树:树的深度 (这里指 只需要调整树的深度,就能得到不错的学习正确率)
- 随机森林:决策树的个数,每棵树的深度(如果不调整这项参数,那么决策树会无限生长直至分类结束),每棵树使用的特征个数
- 多层感知机:学习速率,迭代次数,中间层个数
- 支持向量机:核的选择,次数(degree, 针对polynomial等核),错误容忍度(C),gamma。
由此看出,决策树在调参方面易于其他三种算法。