CNN卷积神经网络的学习笔记
目录
1.分类与回归问题的认识
2.基本原理
3.卷积的过程,提取特征的方法
4.图像识别,实践
分类与回归问题的认识
机器学习是对计算机数据进行学习,然后对一些数据进行预测。机器学习的其中一种学习方法为监督学习,而监督学习通常用于分类与回归。
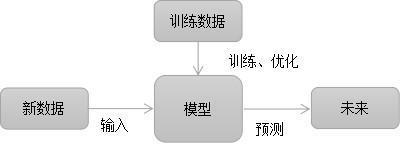
分类是给一个样本预测离散型类别标签的问题。
回归是给一个样本预测连续输出量的问题。
分类就像在做选择题,从已知选项中找到答案。
回归就像填空题,根据题目(输入),找到答案,注回归问题得到的答案并不准确,只是某个范围内的值。
比如说人脸识别
计算机根据数据识别人脸(计算机识别有可能为人脸的区域为回归),找到区域后,可设定一个具体的数值,超过75%可识别为人脸。对超过75%,小于75%这个问题的选择就是分类。
基本原理
将输入的图像数据通过CNN卷积神经网络的处理,提取其特征达到图像识别的效果。提供以下两个网站,易于理解。
CNN ExplainerCNN解释器网站,从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变_哔哩哔哩_bilibilij
卷积是怎样的过程,怎么提取特征,如图所示

具体是怎么计算的呢
将卷积核与图片矩阵对齐,根据步长(步长或称步幅stride,表示采样间隔)当前步长为一,由左上角向右向下移动,根据计算结果形成新的矩形特征图(feature map)新矩阵能反映原图像的部分特征,设置不同的卷积核就能提取出不同的图像特征,整个卷积过程就起到了提取特征的作用。
池化层也有类似的功能,后面会讲到。下图反映了计算过程。
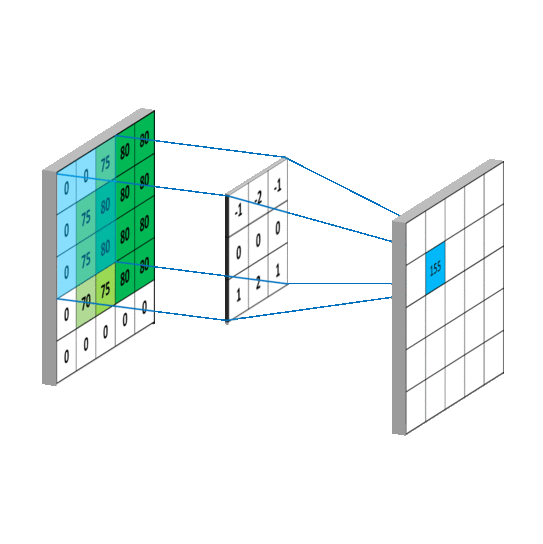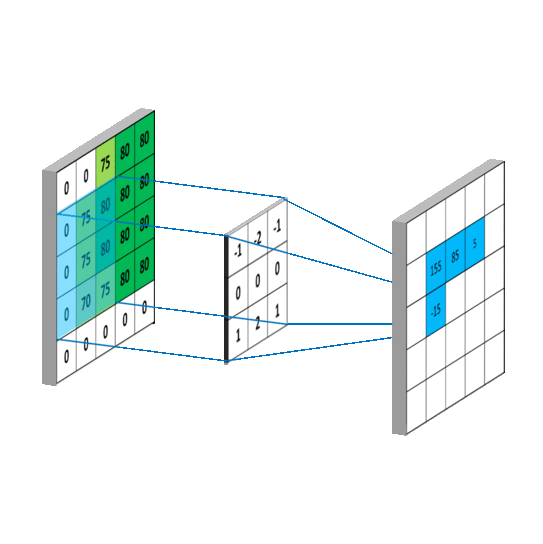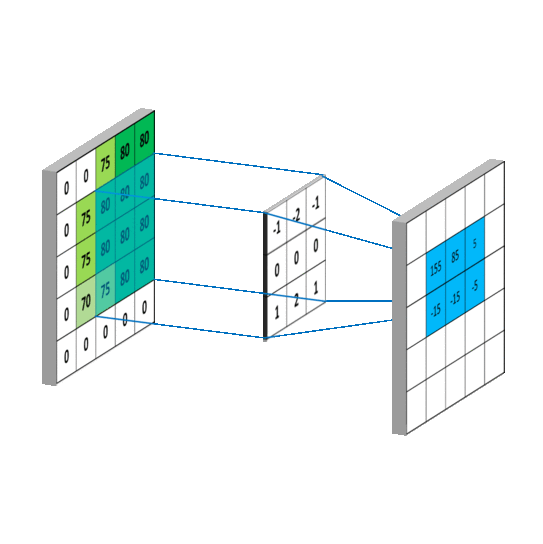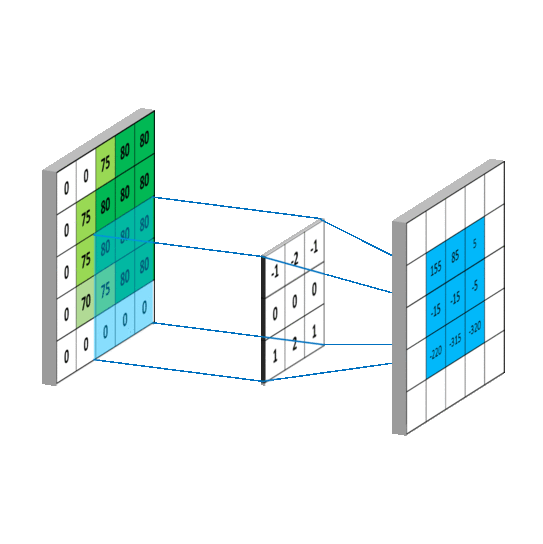
注 feature map表示方法【b,h,w,c】b张照片,h行,w列,c个通道,比如输入RGB图像,就有R,G,B三个通道。当前得到feature map是下一层的输入,通过卷积又形成新的feature,在这个过程中通道数会不断增加。

从这幅图可以看到,蓝色方形外围补了一圈零,为什么要这样做呢
因为不补充零的时候,图片边界的像素点不会处在卷积核的中心,没有被检测到,造成数据丢失。
补零不会对原图数据造成影响。
另一个起提取特征作用的是池化层pooling
常见的有平均池化和最大池化

池化可以大量减少参数
最后是全连接层,将提取的特征集合到一起,给出最后图片可能是什么的概率。

实践:
使用前需装备好VScode,python,opencv。
lolikonloli的博客_CSDN博客-深度学习,人工智能,环境搭建领域博主可以查看VScode的安装方法,Python可以在VScode的商店里下载。
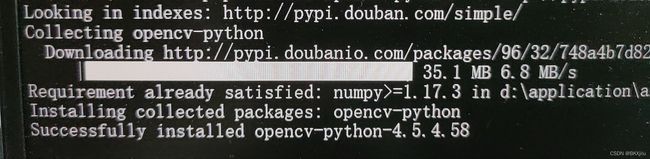
win+r ,输入cmd,输入pip install opencv-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com,如出现下图,就是下载完成
开始:
import cv2
img=cv2.imread('C:/Users/admin/Desktop/20191027-Pyhton+OpenCV/a/1.jpg')#绝对路径(推荐),也可以是相对路径
cv2.imshow('text',img)#imshow指读取图片
cv2.imshow('text1',img)
cv2.waitKey(0)#没有这句话,图片将会一闪而过
————————————————
版权声明:本文为CSDN博主「JMU-HZH」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_45603919/article/details/102829891第一行是导入库
第二行imread就是image read,是读取图片的函数。C:/Users/admin/Desktop/20191027-Pyhton+OpenCV/a/1.jpg的文件路径需要替换(路径可以用鼠标右键点击文件,点击属性,在安全里找到文件名称,注意:复制文件名称后使用英文输入法把“\”换成“/”或“\\”)
第三行test是显示窗口的名字,也是可以替换的。
cv2.imshow('text',img)#imshow指读取图片
cv2.imshow('text1',img)如果输入两个窗口,就会像这样。

cv2.waitKey(0)中的0可以换成其他数字,图像显示的时长会有所变化。