bert系列第一篇: bert进行embedding
文章目录
-
- bert理解
- 简单机理
- encoder输入输出
-
- 输出的结果
- 作用
- code(notebook)
- 总结
- 引用
bert理解
一句话概括, bert就是一个抽取器。输入一句话(词序列),输出抽取后的embedding序列。
再简单理解就是,它就是一个 encoder。
简单机理
我们可以用transformer在语言模型上做预训练。因为transformer是encoder-decoder结构,语言模型就只需要encoder部分就够了。BERT,利用transformer的encoder来进行预训练。
那么什么是transformer?
这是一个新的训练结构,发展历程而言就是CNN,RNN,transformer; transformer是基于attention机理发展而来。
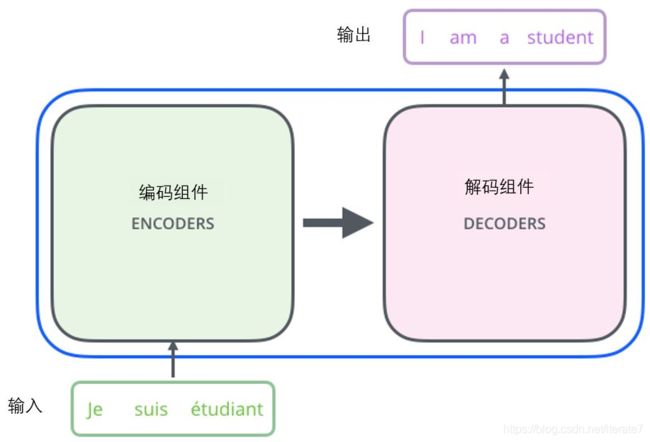
transformer由编码器和解码器组成。编码器和解码器都是基于attention机制。如下图
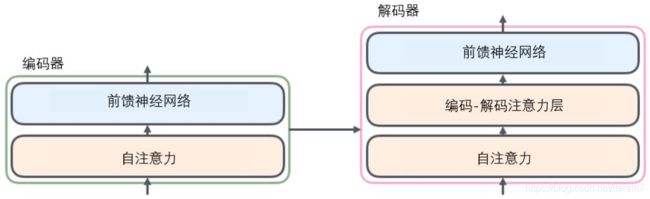
什么是注意力机制,一图简单领会,后面我们单独开一篇动手实践一下
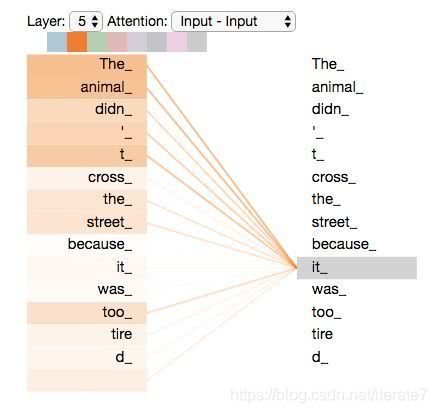
注意力机制就是,当前词的含义,必须结合结合上下文才能更好的理解。
encoder输入输出
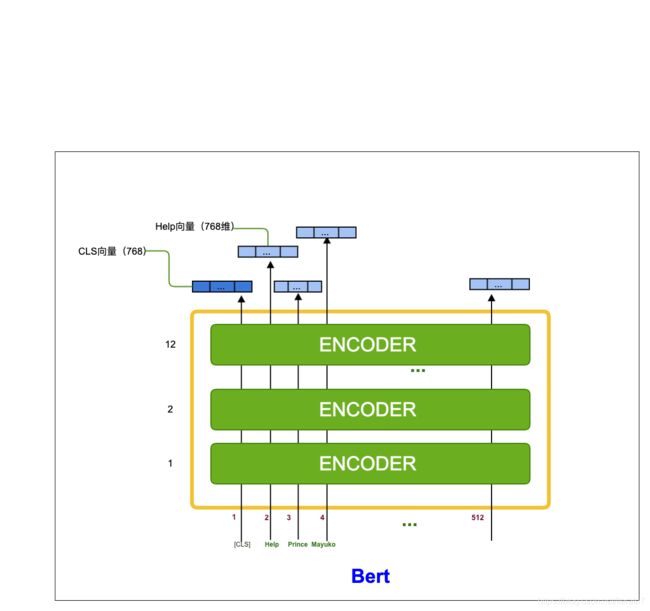
-
输入会加入特殊的[CLS]代表整句话的含义,可以用于分类。
-
input的词help,prince,mayuko等,一共512,这是截取的最大长度。
-
然后经过12层的encoder
-
最后输出的是每个token对应的embedding序列,每个token对应一个768维的向量。这个应该很好理解。
输出的结果
out = bert(xx)
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
**last_hidden_state** (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
**pooler_output** (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
**hidden_states** (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
**attentions** (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
作用
有了词序列对应的embedding向量,就可以对词分类、句子向量构建,句子分类、句子相似度比较等。
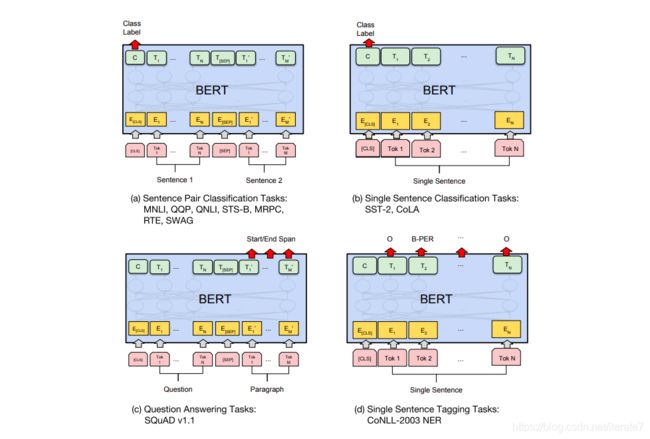
code(notebook)
#%% md
# bert
#%%
!pip install transformers
#%%
import torch
from transformers import BertModel, BertTokenizer
#%%
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
#%%
input_ids = tokenizer.encode('hello world bert!')
input_ids
#%%
type(input_ids)
#%%
ids = torch.LongTensor(input_ids)
ids
#%%
text = tokenizer.convert_ids_to_tokens(input_ids)
text
#%%
model = BertModel.from_pretrained('bert-base-uncased', output_hidden_states=True)
# Set the device to GPU (cuda) if available, otherwise stick with CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
ids = ids.to(device)
model.eval()
#%%
print(ids.size())
# unsqueeze IDs to get batch size of 1 as added dimension
granola_ids = ids.unsqueeze(0)
print(granola_ids.size())
#%% md
In the example below, an additional argument has been given to the model initialisation. output_hidden_states will give us more output information. By default, a BertModel will return a tuple but the contents of that tuple differ depending on the configuration of the model. When passing output_hidden_states=True, the tuple will contain (in order; shape in brackets):
1. the last hidden state (batch_size, sequence_length, hidden_size)
1. the pooler_output of the classification token (batch_size, hidden_size)
1. the hidden_states of the outputs of the model at each layer and the initial embedding outputs (batch_size, sequence_length, hidden_size)
#%%
out = model(input_ids=granola_ids) # tuple
hidden_states = out[2]
print("last hidden state:",out[0].shape) #torch.Size([1, 6, 768])
print("pooler_output of classification token:",out[1].shape)#[1,768] cls
print("all hidden_states:", len(out[2]))
#%%
for i, each_layer in enumerate(hidden_states):
print('layer=',i, each_layer)
#%%
sentence_embedding = torch.mean(hidden_states[-1], dim=1).squeeze()
print(sentence_embedding)
print(sentence_embedding.size())
#%%
# get last four layers
last_four_layers = [hidden_states[i] for i in (-1, -2, -3, -4)]
# cast layers to a tuple and concatenate over the last dimension
cat_hidden_states = torch.cat(tuple(last_four_layers), dim=-1)
print(cat_hidden_states.size())
# take the mean of the concatenated vector over the token dimension
cat_sentence_embedding = torch.mean(cat_hidden_states, dim=1).squeeze()
print(cat_sentence_embedding)
print(cat_sentence_embedding.size())
不同的emebdding组合会带来不一样的结果,参考。
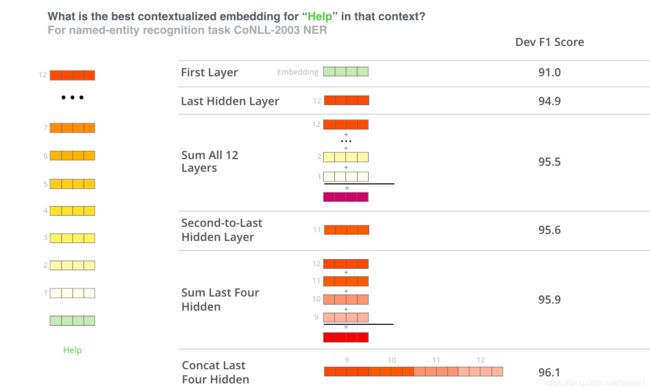
利用concat的向量,最优结果。
总结
- 不同的层代表不同的特征含义,向量组合的实验可以证明这一点。
- bert就是抽取器
- 不同隐层输出的向量的使用是核心所在
- 仔细理解文中的两幅图,和样例代码。然后就是感悟了!
引用
- https://github.com/huggingface/transformers/issues/2986
- https://github.com/BramVanroy/bert-for-inference/blob/master/introduction-to-bert.ipynb
- https://www.cnblogs.com/gczr/p/11785930.html
- https://blog.csdn.net/longxinchen_ml/article/details/86533005