提高Tesseract识别率
Tesseract分享 - 雾非雾的情思
Tesseract分享
本分享基于tesseract4.x
认识Tesseract
项目主页:https://github.com/tesseract-ocr/tesseract
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
识别
识别前处理
调整尺寸
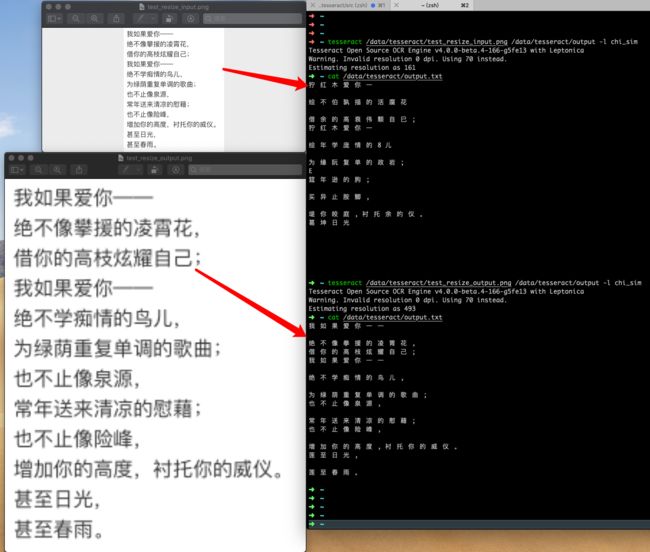
Tesseract对于dpi >= 300的图片有更好的识别效果。所以在识别之前将图片调整到合适的尺寸有助于提高识别效果。下图为识别图片调整尺寸前后的识别效果对比,可以看出图片放大之后,识别效果有明显的提升。
二值化
二值化就是将图像中灰度值大于某个临界灰度值的像素点设置为灰度最大值,灰度值小于某个临界灰度值的像素点设置为灰度最小值。这样图像中就只会出现黑和白两种颜色。合理的二值化能够减少被识别图像中的干扰因素,对于提升识别效果也是有很大的帮助的。例如下图,在二值化之前图片是有水印的,二值化之后能将水印直接去掉。
图片切割
很多情况下我们要识别的图片中文字的排版并不是我们想要的样子,有很多无用的信息,并且排版也不利于tesseract去识别。
简单切割
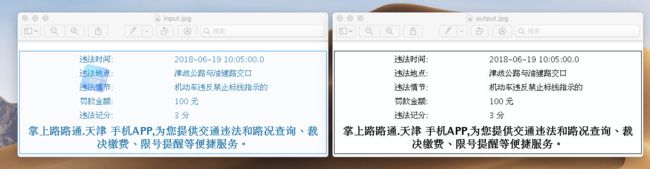
例如下图,我们要从图片中识别出违章信息,包括违章的时间、地点、原因、罚了多少钱、扣了多少分。如果直接拿原图去进行识别,假设所有的字都是别正确,那么这些字的排版也是不是我们最终想要的样子,并且图片中有很多的信息是我们不需要的。所以,可以在识别前分别将图片中时间、地点、原因、金额、分数分别切出多张图,将其他无用的信息都剔除掉。这样做的好处一是单行文字识别对tesseract很友好,二是针对时间、金额、分数这些数字内容可以针对性的使用数字语言库进行识别来提高识别率。
多行、多列切割

图片旋转
如果图片中的文字是倾斜的,会导致Tesseract的行数据分割不准确,严重影响ocr的效果,所以在识别之前可以先旋转图片,使文字保持水平。

命令号调用识别
命令行使用手册
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
➜ bin ./tesseract --help-extra
Usage:
./tesseract --help | --help-extra | --help-psm | --help-oem | --version
./tesseract --list-langs [--tessdata-dir PATH]
./tesseract --print-parameters [options...] [configfile...]
./tesseract imagename|imagelist|stdin outputbase|stdout [options...] [configfile...]
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
|
识别效果展示
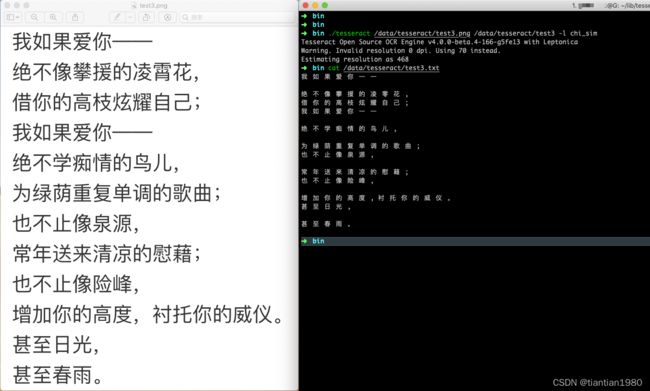
效果如下图所示,对于这种排版整齐、文字清晰、大小合适的图片,直接使用官方提供的中文语言库,识别效果是很好的,下图就做到了100%正确识别。所以一个合适的输入图片,对于提高识别的正确率是有很大的帮助的,识别前图片的预处理就显得尤为重要。
识别后处理
识别之后有些词能看出明显无语义的错误,可以再做一下替换,例如下面的词。
1 2 3 4 |
匕京=北京 交又=交叉 东潮=东湖 ... |
训练
对于一些特殊的字体,使用Tesseract自带的识别库,识别效果并不是那么理想。所以我们可以训练自己的识别库。例如下图的手写字体,我们对比下使用官方提供的chi_sim库和我训练的chi_my库的识别效果。
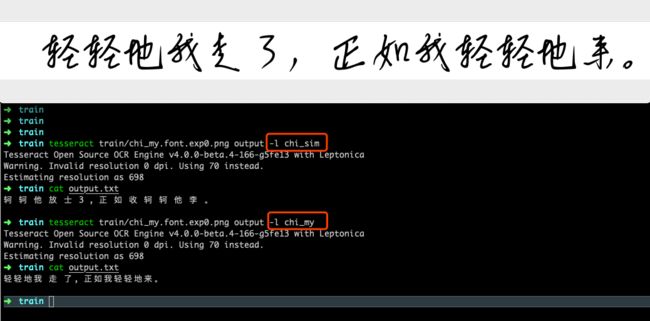
很明显,我自己训练的识别库能够100%准确的识别出图片中的文字,那么我们接下来看下如何去训练自己的识别库。
jTessBoxEditor是一个第三方工具,借助这个工具能够很方便的去训练一个自己的字库。jTessBoxEditor下载地址:VietOCR - Browse /jTessBoxEditor at SourceForge.net 我接下来的介绍中所使用的版本为jTessBoxEditorFX-2.1.0。jTessBoxEditor其实是对Tesseract命令的GUI封装,该工具其实最终也是调用的Tesseract相关的命令来完成训练工作。
基于图片训练
根据图片生成box文件
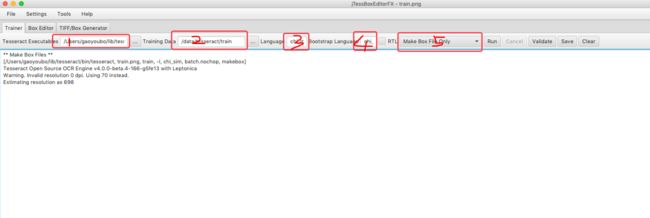
下面介绍下上图标注的5个步骤
- tesseract的安装目录,在这个目录下可以找到tesseract等可执行文件。
- 需要训练的图片所在的路径。
- 所要训练的语言名称,这个可以自己取名,我这里叫做:
chi_my。 - Bootstrap Languange,在生成box文件的时候Tesseract会先根据这里指定的语言识别下,虽然这里识别的会有很多的错误,但是也能帮我们减少一定的工作量。
- 这里选择Make Box File Only,因为生成的box文件可能会有错误,我们后面还会在进行一次编辑,所以这里先只生成box文件。
在jTessBoxEditor下面的输出中我们可以看到,我们最终执行的命令其实是:
1 |
/Users/gaoyoubo/lib/tesseract/bin/tesseract train.png train -l chi_sim batch.nochop makebox |
编辑box文件
在生成box文件之后,我们可以使用jTessEditor文件打开查看下box文件。如下图:
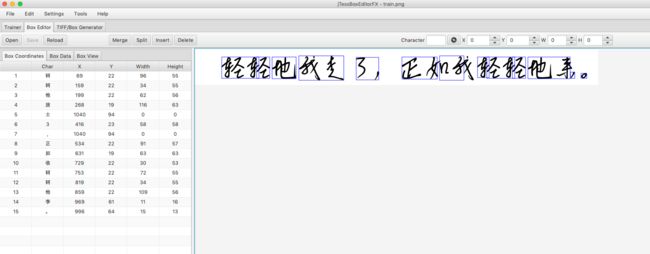
我们对照着生成的box文件查看一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
轲 69 17 165 72 0 轲 159 17 193 72 0 他 199 16 261 72 0 放 268 12 384 75 0 士 1040 0 1040 0 0 3 416 13 474 71 0 , 1040 0 1040 0 0 正 534 15 625 72 0 如 631 12 694 75 0 收 729 19 759 72 0 轲 753 17 825 72 0 轲 819 17 853 72 0 他 859 16 968 72 0 李 969 17 980 33 0 。 996 17 1011 30 0 |
可以看出box文件其实就是描述了图片中的每个字所在的位置,格式为:
1 |
字 x坐标 y坐标 宽度 高度 |
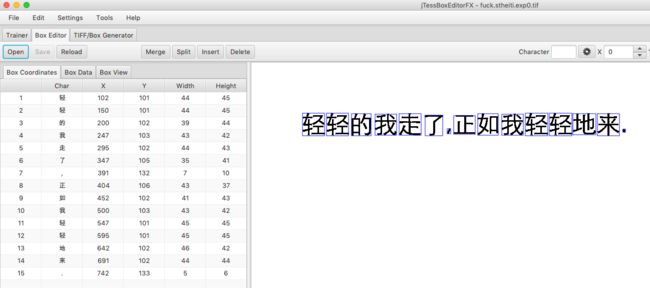
当然我们使用命令生成的box文件是有很多错误的,接下来就需要使用jTessBoxEditor来编辑box文件,调整文字、xy坐标、宽高来准确的标注图片中的每个字。调整完成的结果如下图:
完成训练
在完成box文件的编辑之后就可以使用box文件进行训练了,如下图:
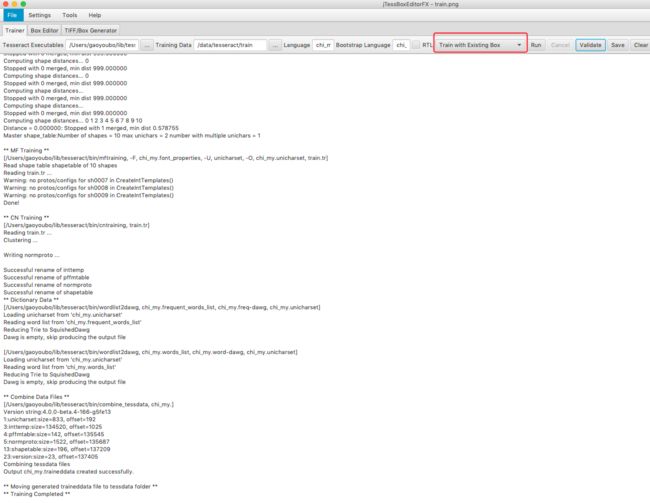
我们这里需要选择Train with Existing Box,进行训练,训练过程中具体使用了哪些命令,都可以在控制台中查看。训练完成之后会在Training Data目录下生成有一个tessdata文件夹,文件夹文件夹中有个chi_my.tessdata文件就是我们的训练结果。我们需要将这个文件copy到%TESSERACT_HOME%/share/tessdata就可以使用了。
基于字体训练
字体各式各样,很多情况下我们在识别图片中文字的时候可能由于字体问题,导致识别并不准确。所以就有为某种字体单独训练识别库的需求。对于根据字体进行训练
jTessBoxEditor也做了很好的支持。
如下图,我们输入想要训练的文字,然后选择字体就能生成相应的图片和box文件了。
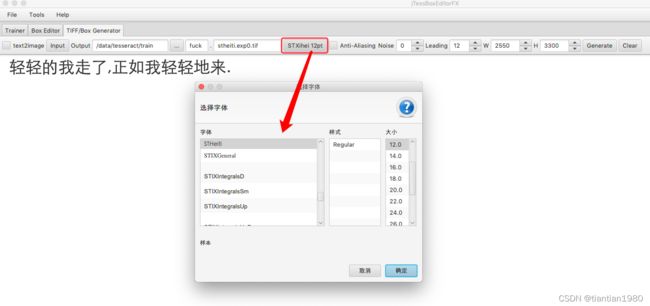
生成结果如下:
有了box文件之后,我们的识别库训练就可以参照上面的步骤了。
参考文档
- 编译安装文档:https://github.com/tesseract-ocr/tesseract/wiki/Compiling
- 训练文档:https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00
- 如何提高识别质量:https://github.com/tesseract-ocr/tesseract/wiki/ImproveQuality
- 什么是二值化:二值化_百度百科
- 图片降噪:Java基于opencv实现图像数字识别(四)—图像降噪_奇迹码农的博客-CSDN博客_opencv 降噪
- LSTM原理及实现:https://blog.csdn.net/gzj_1101/article/details/79376798