第三阶段文献总结
motion分割相关方法
(一)Semantic segmentation–aided visual odometry for urban autonomous driving
1、文章特点:VO中包含重投影误差和光度误差两部分,重投影误差就是通过ORB特征点匹配计算;光度误差类似直接法(此处叫图像对齐方法),但有着一些不同:
- 此处为半稠密方法,选取的是分割出的静态语义标签区域,然后进行梯度滤波,选取梯度较大部分的像素;
- 基于图像对齐的基本假设(平面假设),此处选取的标签都是地面类别,如:路面标记、路面等;
- 候选区域的深度可得,可以用来LS优化中对区域的加权和排序。
2、motion分割方法:直接去除动态先验语义像素
3、可参考部分:特征点法+对齐法的vo模式
(二)Meaningful Maps With Object-Oriented Semantic Mapping
1、文章特点:
(1)实例分割实现:首先SSD进行目标检测,然后利用非监督分割方法(基于[31]改进)对深度图进行目标分割;然后将分割与检测信息连接起来实现实例分割。
(2)对象map独立维护:对象模型更新的核心是更新置信度(通过新的目标检测的置信度来累计更新);map由两部分组成:所有观测到的点云(保存的是每一关键帧观测到的点云),每个对象对应的所有分割点云(保存着指向pose graph的指针)。这种保存方式可以在位姿更新时更新map。
2、motion分割方法:此处针对静态场景,没有motion分割功能
(1)帧间数据关联方法:对象实例间数据关联用类似ICP方法:选择与当前检测目标点云质心最近的landmrks对象点云,然后对每个当前目标点云与相关联的landmarks点云计算最近邻点,得到欧式距离,如果有50%点云的距离小于阈值,则形成关联,否则创建新的对象。
3、可参考部分:
- 帧间数据关联
- 环境/目标独立建图思路
4、几何分割相关文献:[31] T. T. Pham, M. Eich, I. Reid, and G. Wyeth, “Geometrically consistent plane extraction for dense indoor 3d maps segmentation,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS. IEEE, October 2016. [32] P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph-based image segmentation,” International Journal of Computer Vision, vol. 59, no. 2, pp. 167–181, 2004
(三)Improving RGB-D SLAM in dynamic environments: A motion removal approach
1、文章特点
- 提出了一种新的运动去除方法。该方法是在线的,只需要一个RGB-D摄像机作为传感器。在任何阶段都不需要人为干预。
- 采用矢量量化深度图像进行运动分割,并通过实验证明了其优点。
2、motion分割方法
(1)motion检测(相机运动补偿后的帧间差异计算):相机运动由RANSAC方法通过单应变换计算相邻图片间的变换(因此需要保证平面场景能占场景中大部分),然后在补偿后的2D图像上对比差异(也可以在3D点云上对比差异,但是深度信息误差不稳定,且计算3D相机变换较慢)。
- 输入:当前帧+前一帧 输出:差分图
(2)motion跟踪(基于粒子滤波器的跟踪):在检测阶段,差分图像中的非零像素表示由运动对象引起的运动。图像差分结果中的噪声是不可避免的,尤其是在单应性估计错误的情况下。因此,使用粒子滤波器来增强运动检测。此处的噪声表示不位于移动对象上的非零像素。以上节输出的差分图作为观测,在2D图像空间跟踪(在3D欧式空间跟踪会在深度方向产生大量粒子层,会增加计算量),粒子滤波步骤:
- 选择粒子:初始时设置为2D图像空间均匀分布的粒子,之后的分布逐渐趋近非线性(此处用高斯分布表示)
- 贝叶斯公式:粒子滤波器的变量(粒子)的后验置信度由状态转移方程和观测方程得出

- 状态转移方程:第一节得出的2D透视变换矩阵,将前一帧点映射到当前帧的坐标
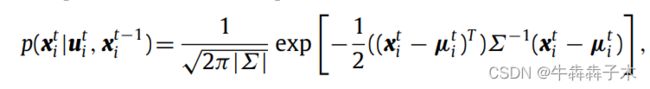
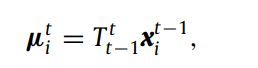
- 粒子权重计算:权重计算由观测得出,此处权重是差分图对应粒子点邻域的高斯核函数值


- 重采样:根据权重重采样粒子,此处用Sequential Importance Re-sampling (SIR) strategy [37]
(3)motion分割(基于深度图矢量量化的分割):在分割阶段,由粒子滤波器计算的后验信度作为MAP估计的似然度。采用矢量量化聚类的深度图像进行运动分割。由MAP计算的前景概率最高的簇被视为前景。
- 深度图矢量量化(VQ):其实就是在深度图上构建向量(向量由像素点和像素值组成,每个像素为一个向量),然后对向量进行K-means聚类,得到数个类别kt。
- 计算cluster k为前景的后验概率:由粒子滤波得到的结果形成似然,由似然得到后验


其中nt表示在k类中的粒子数,Nt表示总的粒子数
- MAP得到前景

3、可参考部分:二维图像上的运动检测和跟踪
(四)Motion Segmentation by Exploiting Complementary Geometric Models
1、文章特点
(1)运动分割的几何模型和其假设:将F帧中跟踪点的观测值表示为{xi}F=1··F。然后,我们随机抽取一对帧中可见的最少数量的p个这样的点,并使用它们来拟合模型的假设。测试的模型包括基本矩阵F、单应性H以及仿射矩阵A。之所以包括仿射矩阵模型,是因为许多现有数据集包含透视性非常弱的序列,因此该简单模型可能在数值上更稳定。对于三种型号F、H和A,p的相应值分别为8、4和3。通过线性算法估计模型参数,并对每种几何模型采样500×F假设。
(2)Affinity Captured as Ordered Residual Kernel(介绍特征点之间的亲和力如何封装到内核中):根据所有几何模型采样的500×F假设,计算剩余特征点的残差(sampson error),残差小于阈值T表示为inliner。特征点间的亲密性由两特征点在所有假设中的共视数量衡量,然而一个特征点在假设中的是否为内点由阈值T决定,而由于不同场景运动范围不同,T往往不好确定。本文使用ORK(有序残差核)来自适应选取阈值。这样就得到了亲和矩阵,一般亲和矩阵需要根据特征点k近邻方法进行稀疏化。
(3)谱聚类进行运动分割:回顾单视图光谱聚类问题,然后将其扩展到多视图聚类
- 单模型谱聚类:亲和矩阵可计算度量矩阵D,计算归一化拉普拉斯矩阵L,Ncut方法进行切图(对归一化拉普拉斯矩阵进行特征分解(特征降维N->M):得到M个最小的特征值及对应特征向量,由特征向量组成N*M维的特征矩阵U);对特征矩阵U按行向量(向量维度为M,向量个数为N)进行K-means聚类,聚为M类。
![]()

- 多模型谱聚类:先介绍了多核聚类加法和协同正则化之间的融合方法,然后提出了子集约束多模型谱聚类(利用模型间几何关系来指定子集约束的多视图聚类)
2、参考学习:sampson error等代价函数的原理,及如何用在单应/基础矩阵评价上(参考MVG书)。
(五)RGB-D SLAM in Dynamic Environments Using Static Point Weighting
1、文章特点:一般里程计实时执行2D关键点的精确匹配。但是,稀疏的2D关键点可能在环境中分布不均匀。如果动态对象具有许多纹理,则动态关键点的数量将超过静态关键点,这可能导致RANSAC回归失败。因此,通常使用额外的IMU传感器数据来补偿此问题。在本文中,我们选择使用深度边来寻找对应关系。深度边包含环境的结构信息。结果表明,基于深度边缘可以估计出准确的视觉里程。深度边缘点是稀疏的,因此可以有效地进行匹配。此外,深度边缘点的数量比2D关键点更平衡。通过使用几何距离和强度距离来匹配帧之间的边缘点。在匹配边缘点的基础上,提出了一种新的静态加权方法来对视觉里程计方法中的动态点进行加权。此外,利用一种有效的环路闭合检测方法,将视觉里程测量方法融合到一个基于位姿图的SLAM系统中,得到了一个适用于动态环境的快速RGB-D SLAM系统。
2、motion分割:本文是通过给深度边缘上的点赋予静态权重,来分割动静的。这个静态权重是在算得当前帧位姿后,计算当前帧上点与变换坐标后的关键帧上对应点的场景流来分配权重的。
(六)DOT: Dynamic Object Tracking for Visual SLAM
1、文章特点:介绍了DOT(动态对象跟踪),这是一种可以添加到现有的 SLAM 系统中的前端,可以显著提高其在高动态环境中的鲁棒性和准确性。DOT 将实例分割和多视图几何图形相结合,为动态对象生成掩码,以使基于刚性场景模型的 SLAM 系统在优化时避开这些图像区域。为了确定哪些对象实际上在移动,DOT 首先对潜在动态对象实例进行分割,然后利用估计的相机运动,通过最小化光度重投影误差来跟踪这些对象。相比于其他方法,这种短期跟踪提高了分割的准确性。其实DOT的作用就是:生成实际的动态掩码、为SLAM提供优化初始值。
2、motion分割:
- 实例分割,得到潜在运动目标
- 根据实例分割计算ego-motion和object-motion:注意其中的跟踪质量保证、遮挡物跟踪、光度影响处理的操作
- 根据算得的Tc、To计算各目标是否实际运动(由几何关系计算视差得到),视差阈值由微分熵确定
- 掩码传播:前一帧变换到后一帧(通过Tc、To运动模型预测得到变换关系)。
(七)DSP-SLAM
1、文章特点:
- SDF函数如何描述物体形状,DeepSDF的原理
- 可微渲染器如何将物体体积投影为深度图,并如何与深度图上的观测一起构成残差从而进行物体形状和位姿优化?
2、motion分割:
(1)目标检测:每个关键帧上进行2D bounding box和分割掩码推断,另外用3Dbounding box检测方法估计目标初始位姿。
(2)数据关联:将每个检测I与地图中最近的对象相关联,根据不同的输入模式采用不同的策略。当激光雷达输入可用时,比较三维边界框和重建对象之间的距离。当仅使用立体或单目图像作为输入时,计算检测和目标之间的匹配特征点数量。如果多个检测与同一对象相关联,保留最近的一个,并拒绝其他检测。未与任何现有对象关联的检测被初始化为新对象,其形状和姿势在之后进行优化。对于立体和单目输入模式,仅当观察到足够多的曲面点时,才会进行重建。当观测到已经重建的目标后,加入新的camera-object边并仅进行位姿优化。这样通过对象级数据关联,新的检测要么被关联到现有地图中的对象中,要么保存为新对象。一个对象检测实例包括:2D bounding box、2D语义掩码、观测到的3D点云深度值和对象初始位姿(I = {B,M, D, Tco,0})
(3)基于先验的目标重建:使用预训练的DeepSDF作为形状先验,将同一个类别的物体形状表示为64维向量。物体的重建可以被转化为对物体形状向量和7D位姿(Sim(3))的联合优化,使得形状和位姿最适合于当前的观测。我们利用SLAM重建的稀疏map 3D点作为观测,最小化表面损失和深度渲染损失函数以优化目标形状编码和目标位姿。已经存在的目标只优化6自由度位姿。
- 观测:目标检测结果I = {B,M, D, Tco,0}
- 优化量:64维形状向量z,7-DoF位姿Tco = [sRco, tco; 0, 1] ∈ Sim(3)
- 表面一致性能量:表示观测到的目标稀疏3D点与重建的目标表面的对齐程度

此处的函数G是DeepSDF预测得到的有符号距离函数,如果点与目标表面完全对齐的话,SDF值为0.
- 深度渲染能量:Ωs上的点是起到深度监督作用(来自于属于目标的稀疏3D点集),而 Ωb上是2D包围框内但是分割掩码之外的点(2D边界框内执行均匀采样,并过滤掉分割掩码内的采样,深度被统一赋予为逃逸点深度值),用来作为轮廓监督,惩罚对象边界外的点。

其中du就是Ωr上的观测值;du后验是通过可微光线跟踪构建的SDF渲染器得到的Ωr上对应的后验深度,它是优化量(目标位姿和目标形状)的函数,由于此渲染器是可微的,所以du后验可对优化量(目标位姿和形状参数)求导,因而此深度渲染能量可以作为优化项。
- 总体优化项:
![]()
(4)联合地图优化:对象作为节点加入因子图进行优化,且与相机的相对位姿作为camera-object edge
3、参考学习:
- 相似形状先验对象级SLAM: FroDO[32]Martin Runz, Kejie Li, Meng Tang, Lingni Ma, Chen Kong, Tanner Schmidt, Ian Reid, Lourdes Agapito, Julian Straub, Steven Lovegrove, and Richard Newcombe. Frodo: From detections to 3d objects. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 3 Node-SLAM[36]Edgar Sucar, Kentaro Wada, and Andrew Davison. Neural object descriptors for-multi view shape reconstruction. In arXiv preprint arXiv:2004.04485, 2020. 3, 4, 5 DeepSLAM++[15] Lan Hu, Wanting Xu, Kun Huang, and Laurent Kneip. Deepslam++: Object-level rgbd slam based on class-specific deep shape priors. arXiv preprint arXiv:1907.09691, 2019. 3
- 以上方案与本文区别:与FroDO[32]不同,本文方法是顺序SLAM系统,而不是批处理方法。与Node-SLAM[36]不同,本文系统中,低级点特征和高级对象被联合优化,以实现两个方面的最佳效果:精确的跟踪和丰富的语义形状信息。DeepSLAM++[15]通过选择Pix3D[37]预测的3D形状来利用SLAM通道中的形状先验,但正向形状生成通常不稳定,导致实际数据的结果不佳。
- 3Dbounding box检测:[18, 45]
- 目标初始位姿3D检测器:[18]
(八)动态场景下的视觉定位与语义建图技术研究_郑冰清
1、文章特点
2、静态区域提取
3、无监督场景分割(3D点云分割方法):
(1)简述:利用场景的全局结构化信息和物体局部表面凹凸性,本章提出一种无监督的 3D 场景分割算法,与目前典型的无监督分割算法(还有哪些?)的对比实验结果表明,本场景分割算法抗噪声能力强、分割效果好。主要包括三部分:
- 综合几何拓扑特性和拟合度的基准平面集解算,可快速完备地提取场景的平面拓扑信息;
- 基于场景基准平面结构对点云面片集的分类操作,完成点云的初步平面分割;
- 基于面片局部凹凸性质的局部点云分割,完成非平面区域的点云分割。
(2)超体素滤波
点云处理流程中滤波处理作为预处理,是对点云进行下采样,方便之后的面片操作,此处利用超体素聚类方法进行滤波。
- 首先利用八叉树存储点云,根据分辨率构建体素空间,并确定点云邻接关系(26邻接)
- 再在体素空间选取种子,通过种子最近邻搜索确定边点,让边点也称为种子
- 开始超体聚类:构建体素相似度公式(包含其空间距离、RGB相似度、法线角度差),由种子点开始通过邻接关系进行扩展,相似度大于阈值就吸收到超体里来。起初种子点为超体中心,每次迭代将所有超体内点的重心作为超体中心,如此迭代直到超体收敛。这样对点云实现了超体滤波,并形成了面片(面片点为超体中心),根据面片邻接关系可将成场景表示为图G(V,E),于是场景分割转化为图分割。
(3)寻找基准平面集:用平面拟合方式寻找基准平面
(4)基于空间结构和局部凹凸性的分割:
- 空间结构即将属于同一基准平面的邻接面片归为一类;若邻接两面片分属于两基准平面,则断开两面片间的邻接边;
- 局部凹凸性是说:一般来说相邻面片关系为凸则两面片属于同一物体,为凹则分属不同物体。故对于不属于基准平面的两邻接面片,利用凹凸性判断他们是否为同一物体。