【Opencv+cvzone】实现眨眼计数
2022年1月10日,腊八,距离放假回家还有5天,距离下次周会还有2天
代码存在C:\Users\10133\PycharmProjects\Project_PictureProcessing
一、调研
-
cvzone
CVzone是一个计算机视觉包,可以让我们轻松运行像人脸检测、手部跟踪、姿势估计等,以及图像处理和其他 AI 功能。它的核心是使用 OpenCV 和 MediaPipe 库。
二、处理过程
-
初始处理
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector
cap = cv2.VideoCapture(0)
detector = FaceMeshDetector(maxFaces=1)
while True:
# 检查目前帧数是否等于全部的帧数 保持视频不断地重复而不关闭
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
success, img = cap.read()
# 用cvzone中的detector对面部特定点进行定位
img, faces = detector.findFaceMesh(img)
# 视频太大的话 可以将视频resize成目标大小
# img = cv2.resize(img, (640, 360))
cv2.imshow('image', img)
cv2.waitKey(1)有一个小的知识点,有关于 cv2 中 waitkey 的使用:
waitkey 控制着 imshow 的持续时间,当 imshow 之后不跟 waitkey 时,相当于没有给 imshow 提供时间展示图像,所以只有一个空窗口一闪而过。添加了 waitkey 后,哪怕仅仅是 cv2.waitkey(1),我们也能截取到一帧的图像。所以 cv2.imshow 后边是必须要跟 cv2.waitkey 的。
detector.findFaceMesh(img) 可以实现对图像进行网格定位,可以达到的效果如下图(救命 着实很好笑)
我这次没有按照教程给的导入视频,而是打开电脑自带摄像头,这次明显比上次流畅很多,不知道为什么手势识别的时候,录像卡成照片

-
对特定点进行检查
在前面先列出要检查的点
# 如果要检查这三个点 首先列一个list
idList = [22, 23, 24]在后面加入绘制这些点的函数
if faces:# 这里可以理解为假设face里面有我们需要知道的内容
face = faces[0]
for id in idList:
cv2.circle(img, face[id], 5, (255, 0, 255))结果如下

同理,可以找到眼睛周围的所有点,将其标注出来,并继续计算上下眼睑的竖直距离,但是只使用这一方法的话,其实也不好,因为当人物相对于摄像头的距离改变时,计算的距离数值也会改变,当人物距离摄像头很远时,会自动被识别成眼睛闭合,所以要改善算法。

-
计数结果
当ratiolength取10时,虽然结果曲线很平缓,但是可以看出依据峰值进行判断的效果很不好
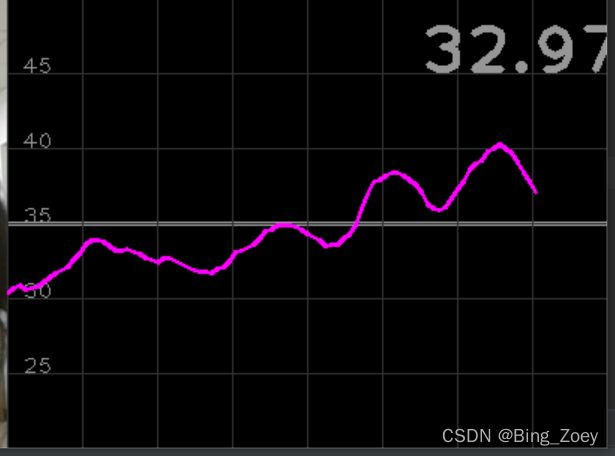
取3的时候就好很多
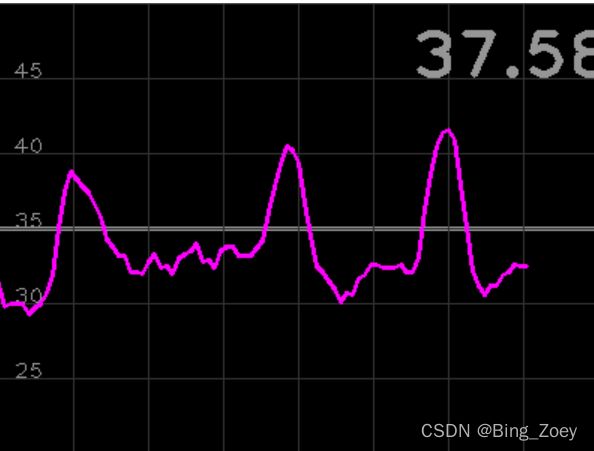
在plot中将技术图像反转之后,得到下图(峰值朝下)
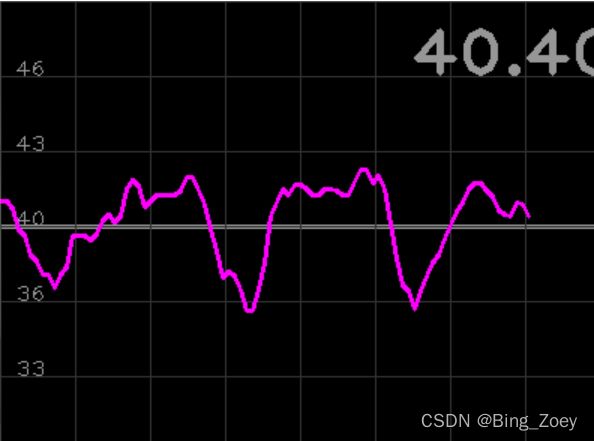
三、全部代码
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector
from cvzone.PlotModule import LivePlot
cap = cv2.VideoCapture(0)
detector = FaceMeshDetector(maxFaces=1)
plotY = LivePlot(400, 300, [30, 50], invert=True)
# 如果要检查这三个点 首先列一个list
idList = [22, 23, 24, 26, 110, 157, 158, 160, 161, 130, 243]
# 建一个空的ratio列表
ratioList = []
# 为了实现计数 先预设参数
blinkCounter = 0
# 为了防止眨眼的帧数重复计算,对进行判别的帧数进行设置
counter = 0
# 设置颜色,可以当眨眼时,将颜色设置为绿色
color = (255, 0, 255)
while True:
# 检查目前帧数是否等于全部的帧数 保持视频不断地重复而不关闭
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
success, img = cap.read()
# 用cvzone中的detector对面部特定点进行网格定位
img, faces = detector.findFaceMesh(img, draw = False)
if faces:# 这里可以理解为假设face里面有我们需要知道的内容
face = faces[0]
for id in idList:
cv2.circle(img, face[id], 5, color, cv2.FILLED)
# 第一个left表示左眼
leftUp = face[159]
leftDown = face[23]
leftLeft = face[130]
leftRight = face[243]
# 计算距离
lengthVer, _ = detector.findDistance(leftUp, leftDown)
lengthHor, _ = detector.findDistance(leftLeft, leftRight)
# 简单的连接两个点
cv2.line(img, leftUp, leftDown, (0, 200, 0), 3)
cv2.line(img, leftLeft, leftRight, (0, 200, 0), 3)
# 输出计算的值 比率*100 cancel int的话,会使后面的曲线更加平滑
ratio = lengthVer/lengthHor * 100
# 扩展ratio列表 以计算ratioAverage
ratioList.append(ratio)
if len(ratioList) > 3:
ratioList.pop(0)
ratioAvg = sum(ratioList)/len(ratioList)
if ratioAvg < 38 and counter == 0:
blinkCounter = blinkCounter+1
color = (0, 200, 0)
counter = 1
if counter != 0:
counter = counter+1
if counter > 10:
counter = 0
color = (255, 0, 255)
# 把文本和矩形放在一起
cvzone.putTextRect(img, f'Blink Count: {blinkCounter}',(50, 100), colorR = color)
# 画图计数
imgPlot = plotY.update(ratioAvg, color)
# cv2.imshow('imagePlot', imgPlot)
img = cv2.resize(img, (400, 300))
# 将视频和计数图像放在同一界面中
imageStack = cvzone.stackImages([img, imgPlot], 2, 1)
else:
img = cv2.resize(img, (400, 300))
imageStack = cvzone.stackImages([img, img], 2, 1)
# 视频太大的话 可以将视频resize成目标大小
# img = cv2.resize(img, (640, 360))
cv2.imshow('imageStack', imageStack)
cv2.waitKey(25)
其实最后实现的效果还可以,但是当人脸相对摄像头的距离发生改变时,判别眨眼与否的门限将会改变,以及我的眼睛也太小了吧,稍微离远一点居然能判别为一直眨眼的状态,哭了= =