医学影像总结(二)
目录
FCN网络
U-NET网络
Alexnet网络
VGG网络
Deeplab网络
ASPP网络
RNN网络
LSTM网络和Con-LSTM网络
FCN网络
FCN网络改变了CNN网络的末端,也就是最后不采取全连接层+softmax,输出每一类的概率。而是在最后一层,采用转置卷积,上采样,让数据最后以图片的形式输出,完成像素级别的分类。
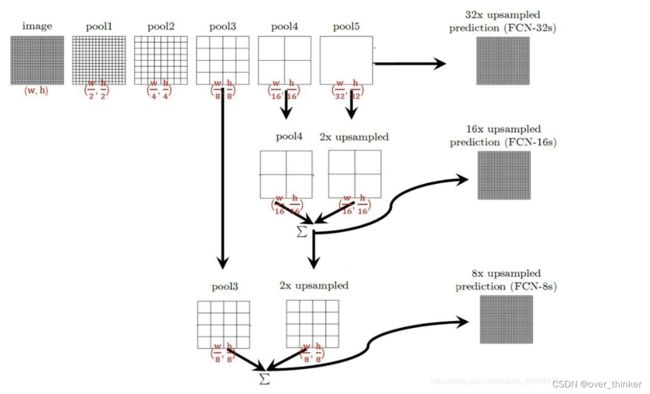
fcn-32s 直接将最后的结果通过转置卷积扩大 32 倍进行输出,而 fcn-16s 就是联合前面一次的结果上采样,相加,扩大 16 倍的输出,fcn-8s就是16s结果加上原特征层进行 8 倍的输出状一样大的结果。这样可以填补细节,减少由于卷积后尺寸太小导致的损失。
U-NET网络
u-net网络也同样是通过反卷积上采样图片,最后输出一张与原图大小相同的图片,但与FCN的加操作不同,u-net在每次填补操作中都是维度调整后合并,而不是加操作。
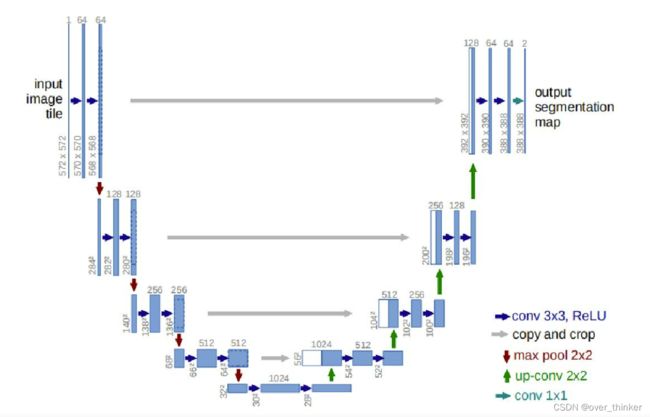
UNet融合了不同尺度的特征,同时跳级连接保证上采样恢复出来的特征不会很粗糙, 更加精细。
Alexnet网络
VGG网络
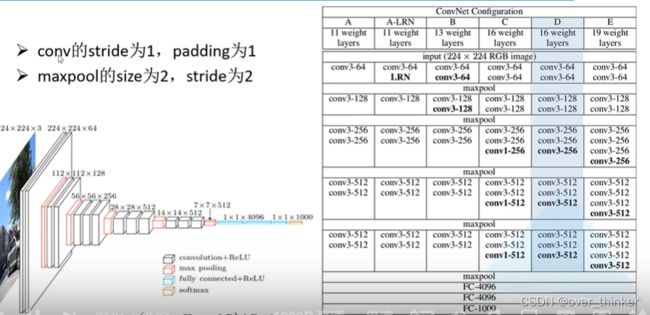
通过增加网络深度提高精度,利用2个3*3卷积核替代5*5,利用3个3*3的卷积核替代7*7.
这样可以有效减少参数。
Deeplab网络
1)deeplabv1:采用large-FOV,CRF(后续版本无),MSc(源码不建议使用)。
large-FOV是为了减少参数数量同时不降低准确率,在FCN网络里会将最后一层全连接层变为卷积操作,但这会导致计算瓶颈,而这一步则是利用膨胀卷积对最后的全连接层做下采样。使感受野不变,减少参数数量和提升训练速度。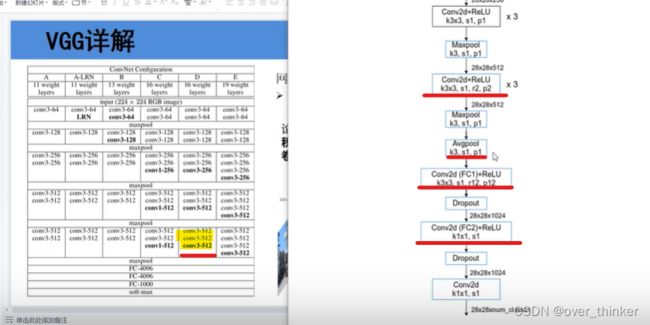
红色线标注出来的是与VGG(D)的区别,将最后的三个卷积改为了膨胀卷积。
以及什么是dropout?
(83条消息) 深度学习中Dropout层作用_UncleDrew_lsy的博客-CSDN博客_dropout层
2)deeplab2
这里有一个目标多尺度问题。
(83条消息) 一文理解深度学习中的多尺度和不同感受野(视野)信息_风兮木萧的博客-CSDN博客_多尺度感受野
ASPP
在deeplab2被提出,类似于FOV的升级版本。 融合多尺度问题

在最后的池化层,利用相同的膨胀卷积和卷积将不同大小的输出特征同样尺寸,使他既包含局部也有整体。
RNN网络
循环神经网络,这个网络主要是来处理序列信息,例如文章段落,天气等相互联系的信息,内部其实就是在做线性变换,但是加入了上一层中经过变换的值并上新的输入作为输出。
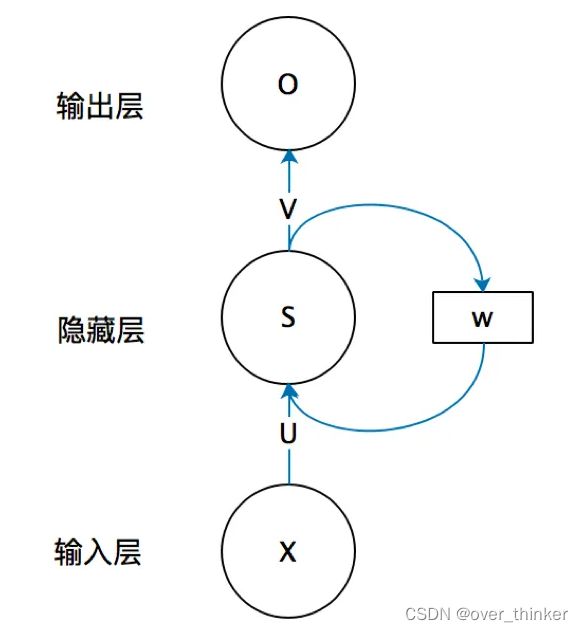
输出可以相同,也可以不同。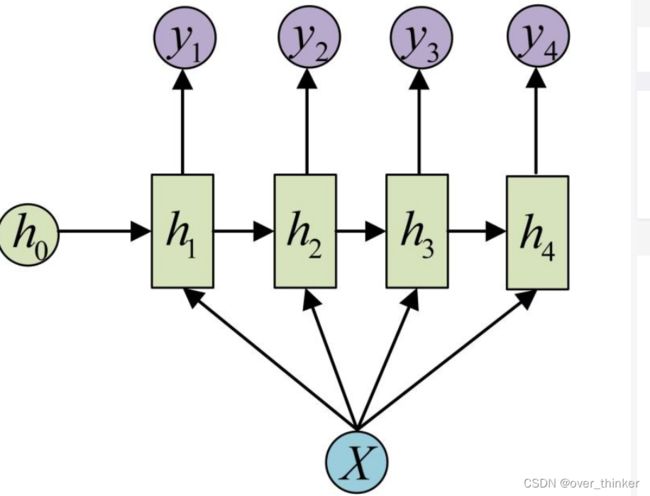
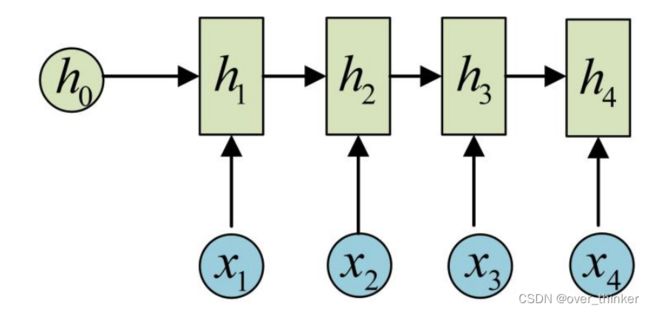
这里会运用tanh做一次激活,但是会出现梯度消失和梯度爆炸的问题,而且还会有无法找到长远序列信息的状况。
LSTM网络和Con-LSTM网络
这里我们利用另外一个激活函数sigmoid来解决两个输入中哪些需要记住和不需要记住的问题。
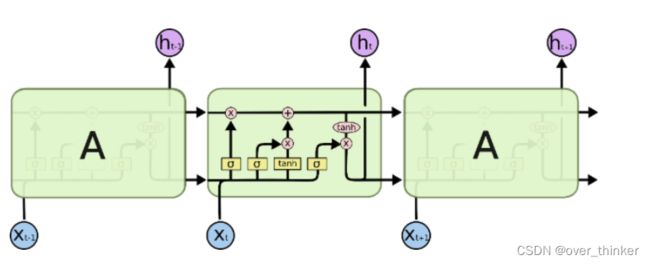
LSTM网络就是对RNN网络的改进,可以有效地解决长期信息的传递,不会导致长期信息的消失。
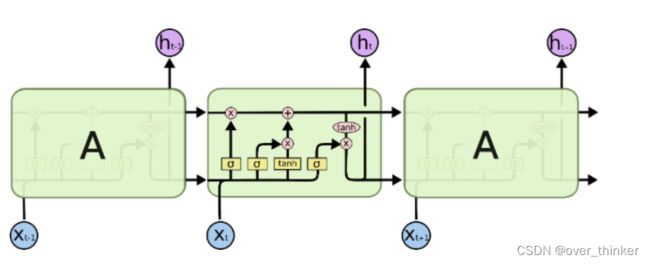
这里输出是一个统计前面哪些需要记住和哪些不需要的记忆细胞的Ct和输出ht。
第一个sigmoid表示遗忘门:在输入中剔出不需要记住的并入记忆细胞。
第二个是将其先tanh在sigmoid:提炼有效信息,将有效信息再次剔除不需要记忆的,与记忆细胞相加。
第三个是输出门,将记忆细胞tanh激活,在城上剔除过无效信息的输入得到输出。
由于 LSTM 在 输入-隐状态、隐状态-输出 的转换中使用了完全连接,因此也可以将其称为 Fully Connected-LSTM,FC-LSTM。为了克服LSTM在处理三维信息中的不足,ConvLSTM 将 LSTM 中的2D的输入转换成了3D的tensor,ConvLSTM 将 LSTM 中的一部分连接操作替换为了卷积操作,即通过当前输入和局部邻居的过去状态来进行预测。