论文笔记:Offline Reinforcement Learning for Mobile Notifications
一、本文要解决的问题及模型选择逻辑
业务问题:time-insensitive notifications to determine the best delivery times towards long-term engagement(one week)
解决这个问题面临的挑战:
- user engagement may not be attributed to a single notification, but rather a sequence of notifications
- the short-term (within a few hours) impact and long-term (over a week or longer) impact may diverge
其他常规方法的局限性:
- cannot fully capture the sequential impact:可用强化学习
- may not necessarily lead to better online performance when couple with the threshold tuning:需离线评估
本文用强化学习应对上述问题:
- 强化学习应用的核心挑战:收益的定义(尽量与业务目标一致)
- Online RL应用的局限性:high infrastructure costs & unknown time to converge & unbounded risks of deteriorating user experience
- Offline RL应用的挑战:efficient offline policy learning & accurate offline policy evaluation
确定方法:Offline RL
二、如何建模
核心是如何构造MDP:![]() ,其中S为状态空间,A为动作空间,P为状态转移模型,R为收益函数,
,其中S为状态空间,A为动作空间,P为状态转移模型,R为收益函数, 为折扣系数
为折扣系数
三、模型要点
1. Offline Training
本文使用Double DQN(efficient offline policy learning)
Q-Learning -> DQN -> Double DQN: 训练样本都是![]()
Q-learning:维护一个Q_table,核心是更新Q值
公式为![]()
DQN:用神经网络代替Q_table,评估某个状态的收益,核心是更新神经网络的参数
训练时,有两个神经网络,评估网络和目标网络,隔一段时间就将评估网络的权重赋给目标网络,核心就是更新评估网络的参数
通过评估网络得到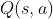
通过目标网络得到![]() ,
,![]()
神经网络训练的目标就是缩小和![]() 的差距
的差距
Double DQN:![]() 的计算逻辑有所改变
的计算逻辑有所改变
通过评估网络得到和![]()
通过目标网络得到![]() ,
,![]()
神经网络训练的目标就是缩小和![]() 的差距
的差距
2. Offline Evaluation
在部署到线上之前,利用线上的数据对学习的policy进行离线评估(accurate offline policy evaluation)
估计什么:某个策略的总期望收益
怎么估计:
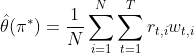
- 而
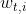 的无偏估计为
的无偏估计为
为什么需要从数据中估计![]() :一般情况下是不知道
:一般情况下是不知道![]() 和
和![]() 的
的
离线估计面临的挑战:
- 状态空间维度过大
- 回合(每个回合最大的时间步数)过长
Action Trajectory Based Weighting:根据马尔可夫的性质进行化简,利用policy下观察到的动作序列的概率即可估计![]() ,
,
One-Step Correction based Weighting:只取t时间步在状态 的条件下动作
的条件下动作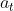 的概率即可,
的概率即可,![]()
State Marginalized Weighting(本文使用):
利用t时间步上的概率和在执行动作的条件下状态的概率进行估计,![]()
这种方法下,为了应对状态空间维度过大所做的优化:
- 去掉动作影响不了的特征(模型训练时不可去掉,会影响收益)
- 离散化每个特征
3. Simulation Evaluation
用来证明离线评估的重要性及哪种离线评估方法好
Environment & Transition process:
模拟用户访问:badge count & user activeness
生成notification candidates
- 正常notifications:4个小时为一个time step,每个time step生成新的notifications,放在队列中(分数 & 过期时间)
- 准实时notifications:队列之外的notifications
- 如何处理即将过期的notifications:50%的概率发送给用户,50%的概率丢弃
State:
- badge count(等待用户查看的notifications数量)
- number of candidate notifications in the queue
- time since the start of the week
- user activeness
Actions:SEND & NOT-SEND
Reward:
- 真实数据中:如果用户在接下来的4小时内访问,数字奖励为1
- 在模拟环境中:使用了一个reward model(输入为user activeness 和 badge count)
四、实验
1. Offline Evaluation in Simulation Environment
实验1: 不同超参下的policy以及baseline的比较(the online evaluation distribution in the simulation environment)
结论1: 离线的评估是必要的——学习的policy不一定超过baseline
实验2: 三种离线评估方法的比较,看在模拟环境中与在线评估的误差
结论2: State Marginalized Weighting更合适
- Action Trajectory Based Weighting:低偏差、高方差
- One-Step Correction based Weighting:高偏差、低方差
- State Marginalized Weighting:平衡了偏差和方差,中偏差、中方差,可调整这个平衡
2. Online Experiments in Notification Spacing
线上如何使用:用户的通知序列每几个小时评估一次,决定是否发送TOP通知
如何利用线上数据进行训练:
- 利用epsilon-greedy behavior policy采集以周为单位的快照数据
- 模型:Double DQN
- 离线评估方法:State Marginalized Weighting
结论1: 线上效果好
结论2: 本文的离线强化学习训练和评估框架提升了迭代速度,离线评估得到的policy可直接部署到线上
PS:本文大部分公式都来自于Offline Reinforcement Learning for Mobile Notifications,有理解不对的地方,欢迎指正